

大家好,我是民工哥。
又是新的一年奋斗路的开启,相信有不少人农历新年之后,肯定会有所变动(跳槽加薪少不了)。所以,我把往期推送过的MySQL技术文章做了一个相关的整理,基础不好的可以从最基础的学习一遍,提高的也可以从中再提取深入一下。
码字不易,如有帮助,请随手点在看与转发朋友圈支持一下民工哥,关注我,一起学习更多的IT技术知识,共同进步。
数据库是什么?
数据库管理系统,简称为DBMS(Database Management System),是用来存储数据的管理系统。
DBMS 的重要性
- 无法多人共享数据
- 无法提供操纵大量数据所需的格式
[En]
unable to provide the format required to manipulate large amounts of data*
- 自动阅读需要编程技能
[En]
automating reading requires programming skills*
- 无法应对突发事故
DBMS 的种类
- 层次性数据库
- 最古老的数据库之一,因为突出的缺点,所以很少使用了
- 关系型数据库
- 采用行列二维表结构来管理数据库,类似Excel的结构,使用专用的SQL语言对数据进行控制。
- 常见类型的关系数据库管理系统
[En]
common types of relational database management systems*
- Oracle ==> 甲骨文
- SQL Servce ==> 微软
- DB2 ==> IBM
- PostgreSQL ==> 开源
- MySQL ==> 开源
- 面向对象的数据库
- XML数据库
- 键值存储系统
- DB2
- Redis
- MongoDB
SQL 语句及其种类
- DDL(数据定义语言)
- create ==> 创建数据库或者表等对象
- drop ==> 删除数据库或者表等对象
- alter ==> 修改数据库或者表等对象的结构
- DML(数据操作语言)
- select ==> 查询表中数据
- insert ==> 向表中插入数据
- update ==> 更新表中数据
- delete ==> 删除表中数据
- DCL(数据控制语言)
- commit ==> 决定对数据库中的数据进行变更
- rollback ==> 取消对数据库中的数据进行变更
- grant ==> 赋予用户操作权限
- revoke ==> 取消用户的操作权限
SQL 的基本书写规则
- SQL 语句要以;结尾
- 关键字不区分大小写,但表中数据区分大小写
[En]
keywords are not case-sensitive, but data in the table is case-sensitive*
- 关键字大写
- 表名的首字母大写
- 列明等小写
- 常数的书写方式是固定的
- 遇到字符串、日期等时需要使用‘’。
[En]
need to use”when encountered with strings, dates, etc.*
- 单词间需要使用空格分割
- 命名规则
- 数据库和表名可以是英文、数据和下划线
[En]
Database and table names can be in English, data and underscores*
- 名称必须以英文作为开头
- 名称不能重复
- 掌握 SQL 这些核心知识点,出去吹牛逼再也不担心了
数据类型
- integer
- 数字型,但是不能存放小数
- char
- 定长字符串类型,指定最大长度,不足使用空格填充
- varchar
- 可变长度字符串类型,指定最大长度,但是不足不填充
- data
- 存储日期,年/月/日
以上内容是对通用数据库以及sql语句相关的知识点介绍,本文不做过多的赘述,本文主要针对关系型数据库:MySQL 来进行各方面的知识点总结。
MySQL 数据库简介
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
MySQL 是一个关系型数据库管理系统,由瑞典 MySQL AB 公司开发,目前属于 Oracle 公司。MySQL 是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL 是开源的,目前隶属于 Oracle 旗下产品。
- MySQL 支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL 使用标准的 SQL 数据语言形式。
- MySQL 可以运行于多个系统上,并且支持多种语言。这些编程语言包括 C、C++、Python、Java、Perl、PHP、Eiffel、Ruby 和 Tcl 等。
- MySQL 对PHP有很好的支持,PHP 是目前最流行的 Web 开发语言。
- MySQL 支持大型数据库,支持 5000 万条记录的数据仓库,32 位系统表文件最大可支持 4GB,64 位系统支持最大的表文件为8TB。
- MySQL 是可以定制的,采用了 GPL 协议,你可以修改源码来开发自己的 MySQL 系统。
在日常工作与学习中,无论是开发、运维、还是测试,对于数据库的学习是不可避免的,同时也是日常工作的必备技术之一。在互联网公司,开源产品线比较多,互联网企业所用的数据库占比较重的还是MySQL。
更多关于MySQL数据库的介绍,有兴趣的读者可以参考官方网站的文档和这篇文章:可能是全网最好的MySQL重要知识点,关于MySQL架构的介绍可以参考:MySQL 架构总览->查询执行流程->SQL 解析顺序
MySQL 安装
MySQL 8正式版8.0.11已发布,官方表示MySQL8要比MySQL 5.7快2倍,还带来了大量的改进和更快的性能!到底谁最牛呢?请看:MySQL 5.7 vs 8.0,哪个性能更牛?
详细的安装步骤请参阅:CentOS 下 MySQL 8.0 安装部署,超详细!,介绍几个 8.0 在关系数据库方面的主要新特性:MySQL 8.0 的 5 个新特性,太实用了!
MySQL基础入门操作
Windows服务
-- 启动MySQL
net start mysql
-- 创建Windows服务
sc create mysql binPath= mysqld_bin_path(注意:等号与值之间有空格)
连接与断开服务器
mysql -h 地址 -P 端口 -u 用户名 -p 密码
SHOW PROCESSLIST -- 显示哪些线程正在运行
SHOW VARIABLES -- 显示系统变量信息
数据库操作
-- 查看当前数据库
SELECT DATABASE();
-- 显示当前时间、用户名、数据库版本
SELECT now(), user(), version();
-- 创建库
CREATE DATABASE[ IF NOT EXISTS] 数据库名 数据库选项
数据库选项:
CHARACTER SET charset_name
COLLATE collation_name
-- 查看已有库
SHOW DATABASES[ LIKE 'PATTERN']
-- 查看当前库信息
SHOW CREATE DATABASE 数据库名
-- 修改库的选项信息
ALTER DATABASE 库名 选项信息
-- 删除库
DROP DATABASE[ IF EXISTS] 数据库名
同时删除该数据库相关的目录及其目录内容
表的操作
-- 创建表
CREATE [TEMPORARY] TABLE[ IF NOT EXISTS] [库名.]表名 ( 表的结构定义 )[ 表选项]
每个字段必须有数据类型
最后一个字段后不能有逗号<details><summary>*<font color='gray'>[En]</font>*</summary>*<font color='gray'>There cannot be a comma after the last field</font>*</details>
TEMPORARY 临时表,会话结束时表自动消失
对于字段的定义:
字段名 数据类型 [NOT NULL | NULL] [DEFAULT default_value] [AUTO_INCREMENT] [UNIQUE [KEY] | [PRIMARY] KEY] [COMMENT 'string']
-- 表选项
-- 字符集
CHARSET = charset_name
如果表没有设定,则使用数据库字符集
-- 存储引擎
ENGINE = engine_name
表在管理数据时采用的不同的数据结构,结构不同会导致处理方式、提供的特性操作等不同
常见的引擎:InnoDB MyISAM Memory/Heap BDB Merge Example CSV MaxDB Archive
不同的引擎在保存表的结构和数据时采用不同的方式
MyISAM表文件含义:.frm表定义,.MYD表数据,.MYI表索引
InnoDB表文件含义:.frm表定义,表空间数据和日志文件
SHOW ENGINES -- 显示存储引擎的状态信息
SHOW ENGINE 引擎名 {LOGS|STATUS} -- 显示存储引擎的日志或状态信息
-- 自增起始数
AUTO_INCREMENT = 行数
-- 数据文件目录
DATA DIRECTORY = '目录'
-- 索引文件目录
INDEX DIRECTORY = '目录'
-- 表注释
COMMENT = 'string'
-- 分区选项
PARTITION BY ... (详细见手册)
-- 查看所有表
SHOW TABLES[ LIKE 'pattern']
SHOW TABLES FROM 表名
-- 查看表机构
SHOW CREATE TABLE 表名 (信息更详细)
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
-- 修改表
-- 修改表本身的选项
ALTER TABLE 表名 表的选项
eg: ALTER TABLE 表名 ENGINE=MYISAM;
-- 对表进行重命名
RENAME TABLE 原表名 TO 新表名
RENAME TABLE 原表名 TO 库名.表名 (可将表移动到另一个数据库)
-- RENAME可以交换两个表名
-- 修改表的字段机构(13.1.2. ALTER TABLE语法)
ALTER TABLE 表名 操作名
-- 操作名
ADD[ COLUMN] 字段定义 -- 增加字段
AFTER 字段名 -- 表示增加在该字段名后面
FIRST -- 表示增加在第一个
ADD PRIMARY KEY(字段名) -- 创建主键
ADD UNIQUE [索引名] (字段名)-- 创建唯一索引
ADD INDEX [索引名] (字段名) -- 创建普通索引
DROP[ COLUMN] 字段名 -- 删除字段
MODIFY[ COLUMN] 字段名 字段属性 -- 支持对字段属性进行修改,不能修改字段名(所有原有属性也需写上)
CHANGE[ COLUMN] 原字段名 新字段名 字段属性 -- 支持对字段名修改
DROP PRIMARY KEY -- 删除主键(删除主键前需删除其AUTO_INCREMENT属性)
DROP INDEX 索引名 -- 删除索引
DROP FOREIGN KEY 外键 -- 删除外键
-- 删除表
DROP TABLE[ IF EXISTS] 表名 ...
-- 清空表数据
TRUNCATE [TABLE] 表名
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
-- 检查表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
-- 优化表
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
-- 修复表
REPAIR [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ... [QUICK] [EXTENDED] [USE_FRM]
-- 分析表
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
有关该操作的更多基本知识,请参阅以下文章:
[En]
For more basic knowledge of the operation, please refer to the following articles:
MySQL 多实例配置
MySQL 主从同步复制
复制概述
Mysql内建的复制功能是构建大型,高性能应用程序的基础。将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其它主机(slaves)上,并重新执行一遍来实现的。复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。主服务器将更新写入二进制日志文件,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。当一个从服务器连接主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置。从服务器接收从那时起发生的任何更新,然后封锁并等待主服务器通知新的更新。
请注意当你进行复制时,所有对复制中的表的更新必须在主服务器上进行。否则,你必须要小心,以避免用户对主服务器上的表进行的更新与对从服务器上的表所进行的更新之间的冲突。 mysql支持的复制类型:
- L默认采用基于语句的复制,效率比较高。一旦发现没法精确复制时, 会自动选着基于行的复制。
- l5.0开始支持
- 采用基于行的复制。
复制解决的问题
MySQL复制技术有以下一些特点:
- 数据分布 (Data distribution )
- 负载平衡(load balancing)
- 备份(Backups)
- 高可用性和容错行 High availability and failover
复制如何工作
整体上来说,复制有3个步骤:
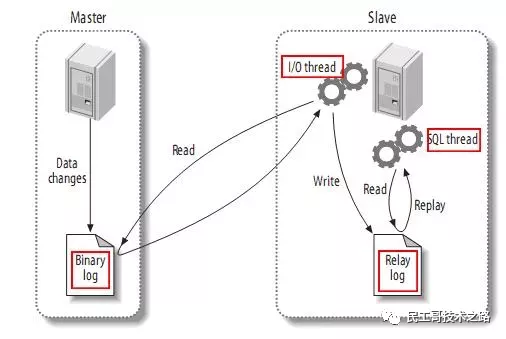

- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
- slave将master的binary log events拷贝到它的中继日志(relay log);
- slave重做中继日志中的事件,将改变反映它自己的数据。
更多相关的更深入的介绍参考:Mysql主从架构的复制原理及配置详解
MySQL 复制有两种方法:
- 传统方式:基于主库的bin-log将日志事件和事件位置复制到从库,从库再加以 应用来达到主从同步的目的。
- Gtid方式:global transaction identifiers是基于事务来复制数据,因此也就不 依赖日志文件位置,同时又能更好的保证主从库数据一致性。
- MySQL数据库主从同步实战过程
- 基于 Gtid 的 MySQL 主从同步实践
- MySQL 主从同步架构中你不知道的”坑” (上)
- MySQL 主从同步架构中你不知道的”坑”(下)
MySQL复制有多种类型:
- 异步复制:一个主库,一个或多个备库,数据异步同步到备库。
[En]
Asynchronous replication: one master library, one or more slave libraries, data asynchronous synchronization to slave libraries.*
- 同步复制:在MySQL Cluster中特有的复制方式。
- 半同步复制:在异步复制的基础上,确保事务提交前至少有一个备库已经收到并记录。
[En]
semi-synchronous replication: on the basis of asynchronous replication, ensure that at least one slave library has received the transaction and logged it before it is committed.*
- 延迟复制:在异步复制的基础上,人为设置主从库的数据同步延迟时间,保证数据延迟至少为该参数。
[En]
delayed replication: on the basis of asynchronous replication, artificially set the data synchronization delay time of the master database and the slave database to ensure that the data delay is at least this parameter.*
MySQL主从复制延迟解决方案:高可用数据库主从复制延时的解决方案
MySQL 数据备份与恢复
数据备份多种方式:
- 物理备份是指通过复制数据库文件来完成备份。此备份方法适用于大型、重要且需要快速恢复的数据库。
[En]
physical backup refers to the completion of backup by copying database files. This backup method is suitable for databases that are large, important and need to be quickly restored.*
- 逻辑备份是指通过备份数据库的逻辑结构(create database/table语句)和数据内容(insert语句或者文本文件)的方式完成备份。这种备份方式适用于数据库不是很大,或者你需要对导出的文件做一定的修改,又或者是希望在另外的不同类型服务器上重新建立此数据库的情况
- 通常情况下物理备份的速度要快于逻辑备份,另外物理备份的备份和恢复粒度范围为整个数据库或者是单个文件。对单表是否有恢复能力取决于存储引擎,比如在MyISAM存储引擎下每个表对应了独立的文件,可以单独恢复;但对于InnoDB存储引擎表来说,可能每个表示对应了独立的文件,也可能表使用了共享数据文件
- 通常需要在关闭数据库时执行物理备份,但如果数据库正在运行,则备份过程中不能修改数据库
[En]
physical backups are usually required to be performed when the database is closed, but if the database is running, the database cannot be modified during the backup*
- 逻辑备份的速度要慢于物理备份,是因为逻辑备份需要访问数据库并将内容转化成逻辑备份需要的格式;通常输出的备份文件大小也要比物理备份大;另外逻辑备份也不包含数据库的配置文件和日志文件内容;备份和恢复的粒度可以是所有数据库,也可以是单个数据库,也可以是单个表;逻辑备份需要再数据库运行的状态下执行;它的执行工具可以是mysqldump或者是select … into outfile两种方式
- 生产数据库备份方案:高逼格企业级MySQL数据库备份方案
- MySQL数据库物理备份方式:Xtrabackup实现数据的备份与恢复
- MySQL 定时备份:MySQL 数据库定时备份的几种方式(非常全面)
MySQL 高可用架构设计与实战
MHA
- MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点。
- MHA Manager: 可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。
- MHA Node: 行在每台MySQL服务器上。
- MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
MHA高可用方案实战:MySQL集群高可用架构之MHA
MGR
- Mysql Group Replication(MGR)是从5.7.17版本开始发布的一个全新的高可用和高扩张的MySQL集群服务。
- 高一致性,基于原生复制及paxos协议的组复制技术,以插件方式提供一致数据安全保证;
- 高容错性,大部分服务可以继续正常工作,自动检测不同节点之间的资源征用冲突,优先按顺序处理,并具有内置的防脑裂解机制。
[En]
High fault tolerance, most services can continue to work normally, automatically detect resource requisition conflicts among different nodes, give priority to processing in order, and have built-in anti-brain fissure mechanism.*
- 高可伸缩性,自动添加和删除节点,更新组信息
[En]
High scalability, automatically add and remove nodes and update group information*
- 高灵活性,单主模式和多主模式。单主模式自动选主,所有更新操作在主进行;多主模式,所有server同时更新。
MySQL 数据库读写分离高可用
海量数据的存储和访问成为了系统设计的瓶颈问题,日益增长的业务数据,无疑对数据库造成了相当大的负载,同时对于系统的稳定性和扩展性提出很高的要求。随着时间和业务的发展,数据库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作的开销也会越来越大;另外,无论怎样升级硬件资源,单台服务器的资源(CPU、磁盘、内存、网络IO、事务数、连接数)总是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。分表、分库和读写分离可以有效地减小单台数据库的压力。
MySQL读写分离高可用架构实战案例:
MySQL性能优化
- 顾名思义,B-tree索引使用B-tree的数据结构存储数据,不同的存储引擎以不同的方式使用B-Tree索引,比如MyISAM使用前缀压缩技术使得索引空间更小,而InnoDB则按照原数据格式存储,且MyISAM索引在索引中记录了对应数据的物理位置,而InnoDB则在索引中记录了对应的主键数值。B-Tree通常意味着所有的值都是按顺序存储,并且每个叶子页到根的距离相同。
- B-Tree索引驱使存储引擎不再通过全表扫描获取数据,而是从索引的根节点开始查找,在根节点和中间节点都存放了指向下层节点的指针,通过比较节点页的值和要查找值可以找到合适的指针进入下层子节点,直到最下层的叶子节点,最终的结果就是要么找到对应的值,要么找不到对应的值。整个B-tree树的深度和表的大小直接相关。
- 全键值匹配:和索引中的所有列都进行匹配,比如查找姓名为zhang san,出生于1982-1-1的人
- 匹配最左前缀:和索引中的最左边的列进行匹配,比如查找所有姓为zhang的人
- 匹配列前缀:匹配索引最左边列的开头部分,比如查找所有以z开头的姓名的人
- 匹配范围值:匹配索引列的范围区域值,比如查找姓在li和wang之间的人
- 精确匹配左边列并范围匹配右边的列:比如查找所有姓为Zhang,且名字以K开头的人
- 只访问索引的查询:查询结果完全可以通过索引获得,也叫做覆盖索引,比如查找所有姓为zhang的人的姓名
- MySQL 常用30种SQL查询语句优化方法|
- MySQL太慢?试试这些诊断思路和工具
-
您可以允许在单个表中存储更多数据,从而打破磁盘限制或组件系统限制。
[En]
you can allow more data to be stored in individual tables, breaking disk restrictions or component system restrictions.*
- 很容易从表中删除过期或历史数据,只要移除相应的分区即可
[En]
it is easy to remove expired or historical data from the table, as long as the corresponding partition is removed*
- 对某些查询和修改语句来说,可以⾃动将数据范围缩⼩到⼀个或⼏个表分区上,优化语句执⾏效率。⽽且可以通过显示指定表分区来执⾏语句,⽐如 select * from temp partition(p1,p2) where store_id < 5;
- 表分区就是按照定义的规则,将每个表的数据分成不同的逻辑块,分别存储。此规则称为分区函数,可以有不同的分区规则。
[En]
Table partitioning is to divide the data of each table into different logical blocks according to the defined rules, and store them separately. This rule is called partitioning function, and there can be different partitioning rules.*
- MySQL5.7版本可以通过show plugins语句查看当前MySQL是否⽀持表分区功能。
- MySQL8.0版本移除了show plugins⾥对partition的显示,但社区版本的表分区功能是默认开启的。
- 但是,当表包含主键或唯一键时,每个被视为分区函数的字段必须是表中唯一键和主键的全部或部分,否则将创建分区表。
[En]
however, when the table contains a primary key or only key, each field that is regarded as a partitioning function must be all or part of the unique key and primary key in the table, otherwise the partitioned table will be created.*
MySQL分库分表
- 能不分就不分,1000万以内的表,不建议分片,通过合适的索引,读写分离等方式,可以很好的解决性能问题。
- 分片数量尽量少,分片尽量均匀分布在多个DataHost上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进 行扩容,增加分片数量。
- 分片规则需要慎重选择,分片规则的选择,需要考虑数据的增长模式,数据的访 问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片, 一致性Hash分片,这几种分片都有利于扩容。
- 尽量不要在一个事务中的SQL跨越多个分片,分布式事务一直是个不好处理的问题。
- 查询条件尽量优化,尽量避免Select * 的方式,大量数据结果集下,会消耗大量 带宽和CPU资源,查询尽量避免返回大量结果集,并且尽量为频繁使用的查询语句建立索引。
数据库分库分表概述:数据库分库分表,何时分?怎样分?
Mysql分库分表方案:MySQL 分库分表方案,总结的非常好!
Mysql分库分表的思路:解救 DBA—数据库分库分表思路及案例分析
MySQL性能监控
MySQL性能监控的指标大体可以分为以下4大类:
- 查询吞吐量
- 查询延迟与错误
- 客户端连接与错误
- 缓冲池利用率
对于MySQL性能监控,官方也提供了相关的服务插件:MySQL-Percona,下面简单介绍一下插件的安装
[root@db01 ~]# yum -y install php php-mysql
[root@db01 ~]# wget https://www.percona.com/downloads/percona-monitoring-plugins/percona-monitoring-plugins-1.1.8/binary/redhat/7/x86_64/percona-zabbix-templates-1.1.8-1.noarch.rpm
[root@db01 ~]# rpm -ivh percona-zabbix-templates-1.1.8-1.noarch.rpm
warning: percona-zabbix-templates-1.1.8-1.noarch.rpm: Header V4 DSA/SHA1 Signature, key ID cd2efd2a: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:percona-zabbix-templates-1.1.8-1 ################################# [100%]
Scripts are installed to /var/lib/zabbix/percona/scripts
Templates are installed to /var/lib/zabbix/percona/templates
最后,可以配合其它监控工具来实现对MySQL的性能监控。
MySQL服务器配置插件:
- 修改php脚本连接MySQL的monitor@localhost用户
- 修改MySQL的sock文件路径
[root@db01 ~]# sed -i '30c $mysql_user = "monitor";' /var/lib/zabbix/percona/scripts/ss_get_mysql_stats.php
[root@db01 ~]# sed -i '31c $mysql_pass = "123456";' /var/lib/zabbix/percona/scripts/ss_get_mysql_stats.php
[root@db01 ~]# sed -i '33c $mysql_socket = "/tmp/mysql.sock";' /var/lib/zabbix/percona/scripts/ss_get_mysql_stats.php
测试是否可用( 可以从MySQL中获取到监控值 )
[root@db01 ~]# /usr/bin/php -q /var/lib/zabbix/percona/scripts/ss_get_mysql_stats.php --host localhost --items gg
gg:12
确保当前文件的 属主 属组 是zabbix,否则zabbix监控取值错误。
[root@db01 ~]# ll -sh /tmp/localhost-mysql_cacti_stats.txt
4.0K -rw-rw-r-- 1 zabbix zabbix 1.3K Dec 5 17:34 /tmp/localhost-mysql_cacti_stats.txt
移动zabbix-agent配置文件到 /etc/zabbix/zabbix_agentd.d/目录
[root@db01 ~]# mv /var/lib/zabbix/percona/templates/userparameter_percona_mysql.conf /etc/zabbix/zabbix_agentd.d/
[root@db01 ~]# systemctl restart zabbix-agent.service
导入并配置Zabbix模板与主机:
默认模板监控时间为 5分钟 ( 当前测试修改为 30s) 同时也要修改Zabbix模板时间
如果要修改监控获取值的时间不但要在zabbix面板修改取值时间,bash脚本也要修改。
[root@db01 scripts]# sed -n '/TIMEFLM/p' /var/lib/zabbix/percona/scripts/get_mysql_stats_wrapper.sh
TIMEFLM=stat -c %Y /tmp/$HOST-mysql_cacti_stats.txt
if [ expr $TIMENOW - $TIMEFLM -gt 300 ]; then
这个 300 代表 300s 同时也要修改。
默认模板版本为2.0.9,无法在4.0版本使用,可以先从3.0版本导出,然后再导入4.0版本 。
其实,在实际生产过程中,还是有相关的专业监控数据库的第三方开源软件的,民工哥之前也写过相关的文章,今天发出来供大家参考:强大的开源企业级数据库监控利器Lepus
MySQL 管理工具
MySQL 是最广泛使用和流行的开源数据库之一,围绕它有许多工具,可以让设计,创建和管理数据库的过程变得更加容易和便捷。但是如何选择最适合自己需求的工具,并不容易。这里为大家推荐:10款MySQL的GUI工具,它们对开发人员和DBA来说都是不错的解决方案。
很早之前民工哥就给大家介绍过一款开源的SQL管理工具:自动补全、回滚!介绍一款可视化 sql 诊断利器。
今天,民工哥再给大家推荐一款SQL审核利器:MySQL 自动化运维工具 goinception。
可视化管理工具,大家可以试试这个:介绍一款免费好用的可视化数据库管理工具
俗话说工欲善其事,必先利其器,定期对你的MYSQL数据库进行一个体检,是保证数据库安全运行的重要手段,因为,好的工具是使你的工作效率倍增!
今天和大家分享几个mysql 优化的工具,你可以使用它们对你的mysql进行一个体检,生成awr报告,让你从整体上把握你的数据库的性能情况。
性能优化诊断工具:别小看这几个工具!关键时能帮你快速解决数据库瓶颈
MySQL 常见错误代码说明
首先,我将向大家展示一些错误分析和解决方案的例子。
[En]
First of all, I will show you some examples of error analysis and solutions.
- 1.ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/data/mysql/mysql.sock’
问题分析:可能是数据库没有启动或者端口被防火墙禁止。
[En]
Problem analysis: it may be that the database is not started or the port is prohibited by the firewall.
解决方案:启动数据库或防火墙,打开数据库监听端口。
[En]
Solution: start the database or firewall to open the database listening port.
- 2.ERROR 1045 (28000): Access denied for user ‘root’@’localhost’ (using password: NO)
问题分析:密码不正确或没有访问权限。
[En]
Problem analysis: incorrect password or no permission to access.
解决方法:
1)修改 my.cnf 主配置文件,在[mysqld]下添加 skip-grant-tables,重启数据库。最后修改密码命令如下:
mysql> use mysql;
mysql> update user set password=password("123456") where user="root";
再删除刚刚添加的 skip-grant-tables 参数,再重启数据库,使用新密码即可登录。
2)重新授权,命令如下:
mysql> grant all on *.* to 'root'@'mysql-server' identified by '123456';
- 3.客户端报 Too many connections
问题分析:连接数超出 Mysql 的最大连接限制。
解决方法:
- 1、在 my.cnf 配置文件里面增加连接数,然后重启 MySQL 服务。max_connections = 10000
- 2、临时修改最大连接数,重启后不生效。需要在 my.cnf 里面修改配置文件,下次重启生效。
set GLOBAL max_connections=10000;
- 4.Warning: World-writable config file ‘/etc/my.cnf’ is ignored ERROR! MySQL is running but PID file could not be found
问题分析:MySQL 的配置文件/etc/my.cnf 权限不对。
解决方法:
chmod 644 /et/my.cnf
- 5.InnoDB: Error: page 14178 log sequence number 29455369832 InnoDB: is in the future! Current system log sequence number 29455369832
问题分析:innodb 数据文件损坏。
解决方法:修改 my.cnf 配置文件,在 [mysqld]下添加 innodb_force_recovery=4, 启动数据库后备份数据文件,然后去掉该参数,利用备份文件恢复数据。
- 6.从库的 Slave_IO_Running 为 NO
问题分析:主库和从库的 server-id 值一样.
解决方法:修改从库的 server-id 的值,修改为和主库不一样,比主库低。修改完后重启,再同步即可!
- 7.从库的 Slave_IO_Running 为 NO问题
问题分析:造成从库线程为 NO 的原因会有很多,主要原因是主键冲突或者主库删除或更新数据, 从库找不到记录,数据被修改导致。通常状态码报错有 1007、1032、1062、1452 等。
解决方法一:
mysql> stop slave;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> start slave;
解决方案2:从库中设置用户权限和只读权限
[En]
Solution 2: set user permissions and set read-only permissions from the library
set global read_only=true;
<br>8.Error initializing relay log position: I/O error reading the header from the binary log
分析问题:从库的中继日志 relay-bin 损坏. 解决方法:手工修复,重新找到同步的 binlog 和 pos 点,然后重新同步即可。
mysql> CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.xxx',MASTER_LOG_POS=xxx;
维护过MySQL的运维或DBA都知道,经常会遇到的一些错误信息中有一些类似10xx的代码。
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows event on table xuanzhi.test; Can't find record in 'test', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log mysql-bin.000004, end_log_pos 3704
但是,如果您没有深入研究它或以前遇到过它,就不清楚这段代码到底是什么意思。这也给我们的错误安排造成了一些阻碍。
[En]
However, if you don’t delve into it or have encountered it before, it’s not clear what exactly this code means. This also caused some hindrance to our wrong arrangement.
所以,今天民工哥就把主从同步过程中一些常见的错误代码,它的具体说明给大家整理出来了:建议收藏备查!MySQL 常见错误代码说明
MySQL 开发规范与使用技巧
命名规范
- 1.库名、表名、字段名必须使用小写字母,并采用下划线分割。
- a)MySQL有配置参数lower_case_table_names,不可动态更改,Linux系统默认为 0,即库表名以实际情况存储,大小写敏感。如果是1,以小写存储,大小写不敏感。如果是2,以实际情况存储,但以小写比较。
- b)如果大小写混合使用,可能存在abc,Abc,ABC等多个表共存,容易导致混乱。
- c)字段名显示区分大小写,但实际使⽤用不区分,即不可以建立两个名字一样但大小写不一样的字段。
- d)为了统一规范, 库名、表名、字段名使用小写字母。
- 2.库名、表名、字段名禁止超过32个字符。
- 库名、表名、字段名支持最多64个字符,但为了统一规范、易于辨识以及减少传输量,禁止超过32个字符。
- 3.使用INNODB存储引擎。
- INNODB引擎是MySQL5.5版本以后的默认引擘,支持事务、行级锁,有更好的数据恢复能力、更好的并发性能,同时对多核、大内存、SSD等硬件支持更好,支持数据热备份等,因此INNODB相比MyISAM有明显优势。
- 4.库名、表名、字段名禁止使用MySQL保留字。
- 当库名、表名、字段名等属性含有保留字时,SQL语句必须用反引号引用属性名称,这将使得SQL语句书写、SHELL脚本中变量的转义等变得⾮非常复杂。
- 5.禁止使用分区表。
- 分区表对分区键有严格要求;分区表在表变大后,执⾏行DDL、SHARDING、单表恢复等都变得更加困难。因此禁止使用分区表,并建议业务端手动SHARDING。
- 6.建议使用UNSIGNED存储非负数值。
- 同样的字节数,非负存储的数值范围更大。如TINYINT有符号为 -128-127,无符号为0-255。
- 7.建议使用INT UNSIGNED存储IPV4。
- 用UNSINGED INT存储IP地址占用4字节,CHAR(15)则占用15字节。另外,计算机处理整数类型比字符串类型快。使用INT UNSIGNED而不是CHAR(15)来存储IPV4地址,通过MySQL函数inet_ntoa和inet_aton来进行转化。IPv6地址目前没有转化函数,需要使用DECIMAL或两个BIGINT来存储。
例如:
SELECT INET_ATON('209.207.224.40'); 3520061480SELECT INET_NTOA(3520061480);
209.207.224.40
- 8.强烈建议使用TINYINT来代替ENUM类型。
- ENUM类型在需要修改或增加枚举值时,需要在线DDL,成本较高;ENUM列值如果含有数字类型,可能会引起默认值混淆。
- 9.使用VARBINARY存储大小写敏感的变长字符串或二进制内容。
- VARBINARY默认区分大小写,没有字符集概念,速度快。
- 10.INT类型固定占用4字节存储
- 例如INT(4)仅代表显示字符宽度为4位,不代表存储长度。数值类型括号后面的数字只是表示宽度而跟存储范围没有关系,比如INT(3)默认显示3位,空格补齐,超出时正常显示,Python、Java客户端等不具备这个功能。
- 11.区分使用DATETIME和TIMESTAMP。
- 存储年使用YEAR类型。存储日期使用DATE类型。存储时间(精确到秒)建议使用TIMESTAMP类型。
- DATETIME和TIMESTAMP都是精确到秒,优先选择TIMESTAMP,因为TIMESTAMP只有4个字节,而DATETIME8个字节。同时TIMESTAMP具有自动赋值以及⾃自动更新的特性。注意:在5.5和之前的版本中,如果一个表中有多个timestamp列,那么最多只能有一列能具有自动更新功能。
如何使用TIMESTAMP的自动赋值属性?
a)自动初始化,而且自动更新:
column1 TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATECURRENT_TIMESTAMP
b)只是自动初始化:
column1 TIMESTAMP DEFAULT CURRENT_TIMESTAMP
c)自动更新,初始化的值为0:
column1 TIMESTAMP DEFAULT 0 ON UPDATE CURRENT_TIMESTAMP
d)初始化的值为0:
column1 TIMESTAMP DEFAULT 0
- 12.索引字段均定义为NOT NULL。
- a)对表的每一行,每个为NULL的列都需要额外的空间来标识。
- b)B树索引时不会存储NULL值,所以如果索引字段可以为NULL,索引效率会下降。
- c)建议用0、特殊值或空串代替NULL值。
详细的可参阅以下文章
MySQL 高频企业面试题
要学好知识,当然要去面试,进大厂,拿高薪。但在进入面试之前,必要的准备是必要的,做做练习就是其中之一。
[En]
To learn knowledge well, of course, you have to go to an interview, get into a big factory, and get a high salary. But before entering the interview, the necessary preparation is necessary, and doing exercises is one of them.
以下内容主要受众为开发人员,所以不涉及到MySQL的服务部署等操作,且内容较多,大家准备好耐心和瓜子矿泉水.
前一阵系统的学习了一下MySQL,也有一些实际操作经验,偶然看到一篇和MySQL相关的面试文章,发现其中的一些问题自己也回答不好,虽然知识点大部分都知道,但是无法将知识串联起来.
因此决定搞一个MySQL灵魂100问,试着用回答问题的方式,让自己对知识点的理解更加深入一点.
此文不会事无巨细的从select的用法开始讲解mysql,主要针对的是开发人员需要知道的一些MySQL的知识点,主要包括索引,事务,优化等方面,以在面试中高频的问句形式给出答案.
MySQL用户行为安全
- 假设这么一个情况,你是某公司mysql-DBA,某日突然公司数据库中的所有被人为删了。
- 虽然有数据备份,但服务中断造成的损失数以千万计,现在公司需要找出是谁做的删除。
[En]
although there are data backups, there are tens of millions of losses caused by service stoppage, and now the company needs to find out who did the deletion.*
- 但有很多人有权操作数据库。如何调查,证据在哪里?
[En]
but there are many people who have the right to operate the database. How to investigate and where is the evidence?*
- 是不是觉得无能为力?
- mysql本身并没有操作审计的功能,那是不是意味着遇到这种情况只能自认倒霉呢?
民工哥技术之路公众号 不定期更新MySQL技术知识体系,大家可以关注我查阅MySQL技术专栏 学习更多的MySQL知识。
Original: https://www.cnblogs.com/youkanyouxiao/p/15790770.html
Author: 民工哥
Title: 谁再说学不会 MySQL 数据库,就把这个给他扔过去!
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/507882/
转载文章受原作者版权保护。转载请注明原作者出处!