

视觉SLAM十四讲笔记-2
文章目录
第二讲-初识SLAM
直接截取高翔视觉SLAM第二章开头图片:
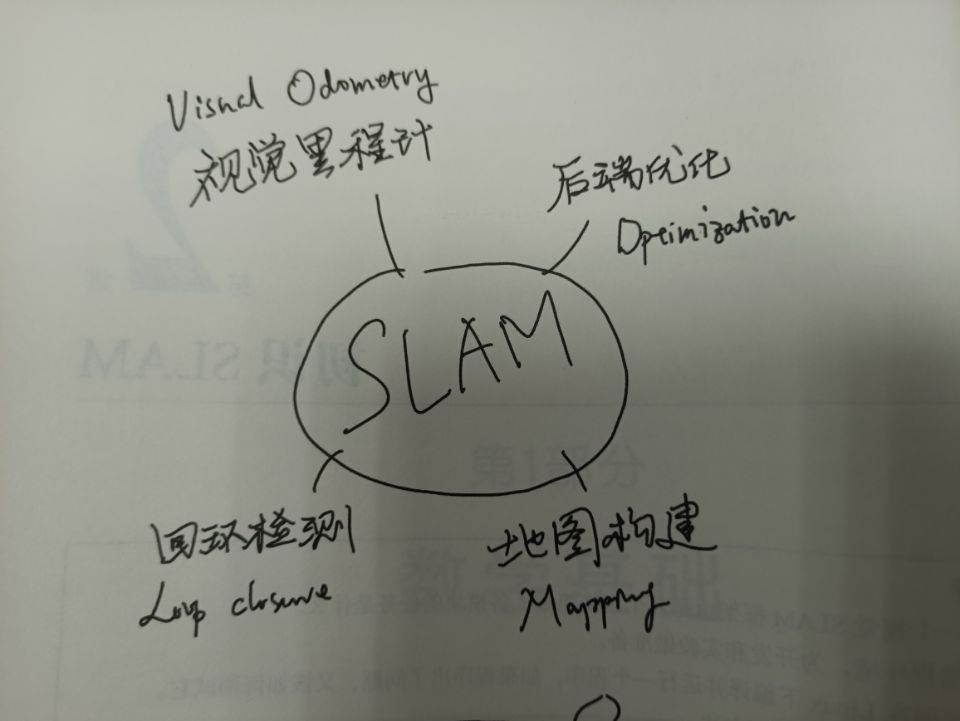

; 2.1 引子
一个机器人要进行自主运动,首先需要感知周围的环境,需要完成两件事情:
1.我在什么地方?定位
2.周围环境是什么样?建图
定位和建图可以看做是建图的”内外之分”。一方面需要明白自身的状态(位置),另一方面也要了解外在的环境(即地图)。
传感器:
1.安装在机器人上
轮式编码器:测量轮子转动的角度
IMU:测量运动的角速度和加速度
相机,激光传感器
2.安装在环境中
导轨,二维码标志等等,受到环境限制可能无法使用
相机:按照工作方式的不同,相机分为单目、双目、深度相机。
1.单目相机:
构造简单成本低。
只使用一个摄像头进行SLAM的做法称为单目SLAM。
特点:单目相机拍摄的图像只是三维空间的二维投影,不知道深度。所以,如果想要恢复三维结构,必须改变相机视角。必须移动相机,才能估计相机的运动,同时估计场景中的远近和大小,不妨称之为结构。
单目SLAM估计的轨迹和地图将与真实的轨迹和地图相差一个因子,也就是所谓的尺度。由于单目SLAM无法仅凭图像确定这个真实尺度,称为尺度不确定性。
2.双目相机和深度相机:
使用双目相机和深度相机的目的是通过某种手段测量物体与相机之间的距离,克服单目相机无法知道距离的特点。一旦知道了距离,场景的三维结构就可以通过单个图像恢复,同时消除尺度不确定性。双目相机由两个单目相机组成,但这个相机之间的距离(称为基线)是已知的。通过这个基线来估计每个像素的空间位置。(基线距离越大,能够测量到的物体就越远,并且计算量是双目的主要问题之一)
深度相机(又称RGB-D相机),它最大的特点是可以通过红外结构光或Time-of-Filght(ToF)原理,激光传感器通过主动向物体发射光并接收返回的光,测出物体与相机之间的距离。通过物理测量手段,相比于双目相机计算来说可以节省计算资源。
现在多数RGB-D相机存在测量范围窄、噪声视野小、易受日光干扰、无法测量透射材质等诸多问题,在SLAM方面,主要用于室内,室外较难应用。
2.2 经典视觉SLAM框架
整个SLAM流程框架如图所示。
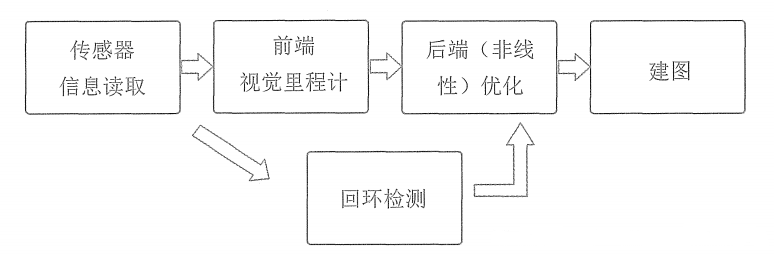
整个视觉SLAM包括以下几个步骤:
1.传感器信息读取。视觉SLAM中主要是相机图像信息的读取和预处理,如果是机器人中可能有码盘、惯性传感器的读取和同步。
2.前端视觉里程计。视觉里程计的任务是估计相邻图像间相机的运动,以及局部地图的样子。
3.后端(非线性优化)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。
4.回环检测。判断机器人是否到达先前的位置。如果检测到回环,会把消息提供给后端进行处理。
5.建图。根据估计的轨迹,建立与任务对应的地图。
; 2.2.1 视觉里程计
视觉里程计关心相邻图像之间的相机运动,
在计算机视觉领域,图像在计算机里只是一个数值矩阵。在视觉SLAM中,只能看到一个个像素,知道它们是某些空间点在相机的成像平面上投影的结果。所以,为了定量地估计相机运动,必须先了解相机与空间点的几何关系。
假设已经有了一个视觉里程计,估计了两张图像间的相机运动。那么,一方面只要把相邻时刻的运动串起来就可以构成了机器人的运动轨迹,从而解决了定位问题。另一方面,根据每一时刻的相机位置,计算出各像素对应的空间点位置,就得到了地图。由此看来,视觉里程计是SLAM的关键。
然而,视觉里程计会出现累积漂移。为了解决漂移问题,需要:后端优化和回环检测。
2.2.2 后端优化
后端有话主要指处理SLAM过程中的噪声问题。现实过程中,再精确的传感器也会有一定的噪声,除了解决”如何从图像中估计出相机运动”,还要关系这个估计带有多大的噪声。 后端优化要解决的问题就是如何从这些带有噪声的数据中估计整个系统的状态,以及这个状态估计的不确定性有多大。
后端,负责整体的优化过程,往往面对的只有数据,不必关心这些数据到底来自什么传感器。
后端主要是滤波与非线性优化算法
2.2.3 回环检测
主要解决位置估计随时间漂移的问题。
为了实现回环检测,需要机器人具有识别到过场景的能力。
2.2.4 建图
分为度量地图和拓扑地图
2.3 SLAM问题的数学表述
把一段连续时间的运动变成了离散时刻 t = 1 , 2 , 3 , … , K t=1,2,3,…,K t =1 ,2 ,3 ,…,K,在这些时刻,用x x x表示每一时刻机器人的位置,于是每一时刻的位置记为x 1 , x 2 , . . . , x K x_{1},x_{2},…,x_{K}x 1 ,x 2 ,…,x K 。实际环境中存在许多路标,每一时刻,传感器会测量得到一部分路标点,得到它们的观测数据。不妨设路标点一共有 N N N个,用 y 1 , y 2 , . . . , y N y_{1},y_{2},…,y_{N}y 1 ,y 2 ,…,y N 表示它们。
根据上面的定义,机器人在环境中的运动,可以由下面两件事情描述:
1.运动。要考察从 k − 1 k-1 k −1时刻到 k k k时刻,机器人的位置 x x x是如何变化的。
2.观测。在 k k k 时刻于 x k x_{k}x k 处探测到了某一个路标 y j y_{j}y j
数学模型:
x k = f ( x k − 1 , u k , w k ) x_{k} = f(x_{k-1},u_{k},w_{k})x k =f (x k −1 ,u k ,w k )
u k u_{k}u k 为运动传感器的输入,w k w_{k}w k 为该过程中加入的噪声。上式表示为运动方程。
由于噪声的存在,如果只根据运动传感器的指令来确定位置可能会与实际位置相差很大。因此,与运动方程相对应,还有一个观测方程。当机器人在 x k x_{k}x k 位置上看到某个路标点 y j y_{j}y j 时,产生一个观测数据 z k , j z_{k,j}z k ,j 。同样,用一个抽象的函数 h h h 来描述这个关系:
z k , j = h ( y j , x k , v k , j ) z_{k,j} = h(y_{j}, x_{k}, v_{k,j})z k ,j =h (y j ,x k ,v k ,j )
v k , j v_{k,j}v k ,j 为这次观测里的噪声。
因此,SLAM过程可以总结为两个基本方程:
{ x k = f ( x k − 1 , u k , w k ) k = 1 , . . . , K z k , j = h ( y j , x k , v k , j ) , ( k , j ) ∈ O \left{ \begin{array}{c} x_{k} = f(x_{k-1},u_{k},w_{k}) k=1,…,K\ z_{k,j} = h(y_{j}, x_{k}, v_{k,j}), (k,j)\in O \ \end{array}\right.{x k =f (x k −1 ,u k ,w k )k =1 ,…,K z k ,j =h (y j ,x k ,v k ,j ),(k ,j )∈O
可以参考下图:link
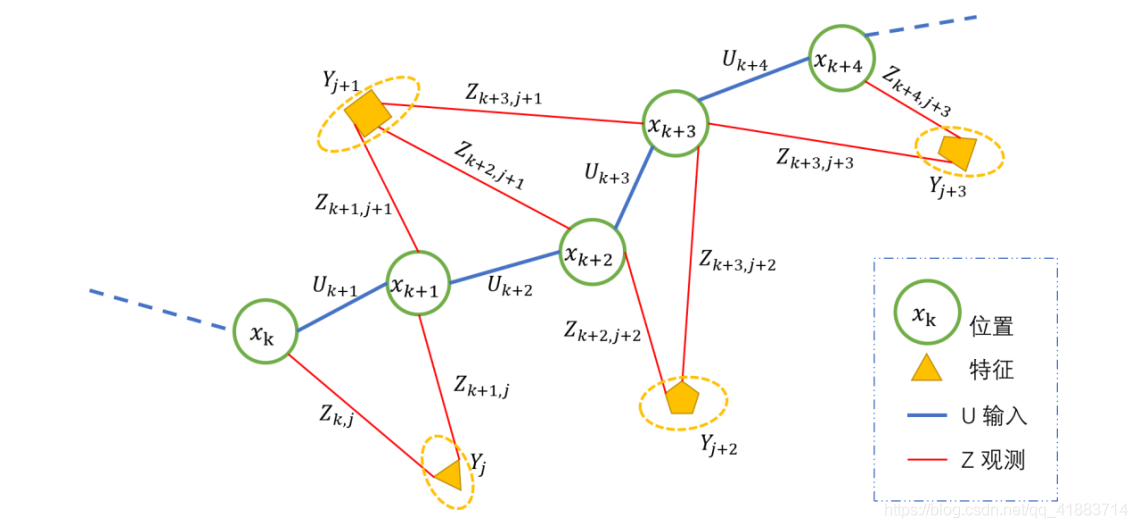
这两个方程描述了最基本的SLAM问题,当知道运动测量的读数 u u u,以及传感器的读数 z z z时,如何求解定位问题(估计 x x x)和建图问题(估计 y y y)?把SLAM问题建模成一个状态估计问题:如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量。
求解方法
目前,主流视觉SLAM使用以图优化为代表的优化技术进行状态估计。
Original: https://blog.csdn.net/qq_35588369/article/details/124210580
Author: 四夕小一冰
Title: 视觉SLAM十四讲笔记-2
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/598147/
转载文章受原作者版权保护。转载请注明原作者出处!