

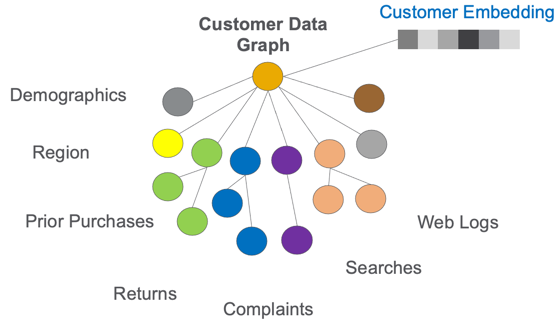

知识图谱中的客户数据样本以及该图中附加的嵌入向量
去年,图嵌入在企业知识图谱(EKG)策略中变得越来越重要。 图形嵌入将很快成为在大型十亿顶点EKG中快速找到相似项目的实际方法。 实时相似性计算对于许多领域至关重要,例如推荐,最佳行动和队列构建。
本文的目的是使您直观地了解什么是图形嵌入以及如何使用它们,以便您可以确定这些嵌入是否适合您的EKG项目。 对于那些具有一定数据科学背景的人,我们还将介绍如何计算它们。 在大多数情况下,我们将使用讲故事和隐喻来解释这些概念。 我们希望你能用这些故事向你的非技术同行解释图形嵌入的有趣和难忘的方式。让我们从第一个故事开始,我把它叫做”Mowgli’s Walk”。
; Mowgli’s Walk
这个故事是基于Rudyard Kipling的精彩小说《The Jungle Book》改编的。
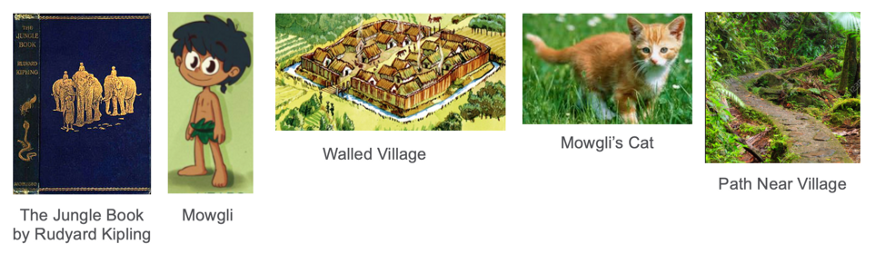
毛克利(Mowgli)是一个住在史前村庄的小男孩,村庄周围有一道坚固的保护墙。毛克利有一只可爱的宠物猫,有着橙色的皮毛和条纹。一天,毛克利走在村外的一条小路上,看见前面的小路上有一只大老虎。毛克利应该做什么?

路上看到一只老虎。他该怎么办?跑回村子里去,或者沿着小路继续走。
他应该继续沿着小路走下去,还是迅速跑回村庄和安全的隔离墙?毛克利没有太多的时间来做这个决定。也许只有几秒钟。毛克利的大脑正在进行实时的威胁检测,他的生命依赖于一个快速的决定。
如果毛克利的大脑认为这只老虎和他的宠物猫很像,他会继续沿着这条路走下去。但如果他意识到老虎是一个威胁,他会很快跑回村庄的安全地带。
让我们来看看毛克利的大脑是如何进化来进行实时威胁评估的。老虎的形象通过毛克利的眼睛传到他大脑的视觉皮层。然后,提取出图像的关键特征。这些特征的信号被发送到他大脑的目标分类区域。毛克利需要将这幅图与他所见过的其他图像进行比较,然后将其与熟悉的概念进行匹配。他的大脑正在进行实时的相似性计算。
一旦毛克利的大脑将图像与老虎的概念相匹配,而老虎的概念又与”危险”的情绪相联系,在它杏仁体(deephub翻译组注:amygdala是产生情绪,识别情绪和调节情绪,控制学习和记忆的脑部组织)的恐惧中心,毛克利就会转身跑回村庄。这种快速反应甚至可能没有经过毛克利新大脑皮层的高阶逻辑处理,我们已经在大脑中进化出了数据结构,通过在1/10秒内分析来自眼睛视网膜的数以百万计的输入信息来促进我们的生存。
现在你可能会问,这和图的嵌入有什么关系?图嵌入是一种小型的数据结构,可以帮助我们的EKG中实时的相似性排序功能。它们的工作原理就像毛克利大脑中的分类部分。这些嵌入式设备可以从数百万个数据点中吸收关于我们心电图中每一项的大量信息。嵌入式将其压缩成数据结构,使用低成本的并行计算硬件(如FPGA)可以方便地进行实时比较。它们能够进行实时相似度计算,用于对图中的项目进行分类,并向用户进行实时推荐。
例如,一位用户来到我们的电子商务网站,想寻找一份礼物送给婴儿。我们应该推荐可爱的毛绒老虎玩具还是流行的火焰喷射器?我们能在十分之一秒内推荐合适的产品吗?我相信,在不久的将来,一个公司能够迅速响应客户的需求,并就下一步最好的行动提出建议,这对任何一个组织的生存都是至关重要的。EKG可以经济高效地存储有关客户历史记录的数万个数据点。 嵌入可以帮助我们离线分析此数据,并实时使用压缩后的数据进行嵌入更新。
既然我们知道了我们要嵌入的内容,我们就可以理解为什么它具有特定的结构。
什么是图嵌入?
在详细介绍如何存储和计算嵌入之前,让我们先介绍一下嵌入的结构以及使嵌入对实时分析有用的特征。
- 图嵌入是用于快速比较相似数据结构的数据结构。太大的图形嵌入会占用更多的RAM和更长的时间来进行比较。在这里,越小往往越好
- 图嵌入压缩了图中某个顶点周围数据的许多复杂特征和结构,包括该顶点的所有属性以及主顶点周围的边和顶点的属性。围绕一个顶点的数据称为”上下文窗口”,我们将在后面讨论。
- 图的嵌入使用机器学习算法计算。像其他机器学习系统一样,我们拥有的训练数据越多,我们的嵌入就越能体现一个项目的独特性。
- 创建一个新的嵌入向量的过程被称为”编码”或”编码一个顶点”。从嵌入中重新生成顶点的过程称为”解码”或”生成顶点”。在找到相似物体的过程中测量嵌入效果的度量被称为”损失函数”(就是loss function和NN中的名字一样)。
- 在嵌入中,可能没有与每个数字相关联的”语义”或意义。嵌入可以被认为是向量空间中一个项的低维表示。在嵌入空间中相邻的项被认为与现实世界中的项相似。嵌入关注的是性能,而不是可解释性。
- 嵌入是”模糊”匹配问题的理想选择。如果您有数百或数千行复杂的If -then语句来构建队列,那么图嵌入提供了一种方法,使此代码更小、更容易维护。
- 图嵌入与其他图算法一起工作。如果您正在进行集群或分类,则可以使用图嵌入作为附加工具来提高这些其他算法的性能和质量。
在我们讨论嵌入如何存储之前,我们应该回顾一下数学接近函数的概念。
嵌入空间中的邻近度
两个概念相似意味着什么? 让我们从地理地图的隐喻开始。
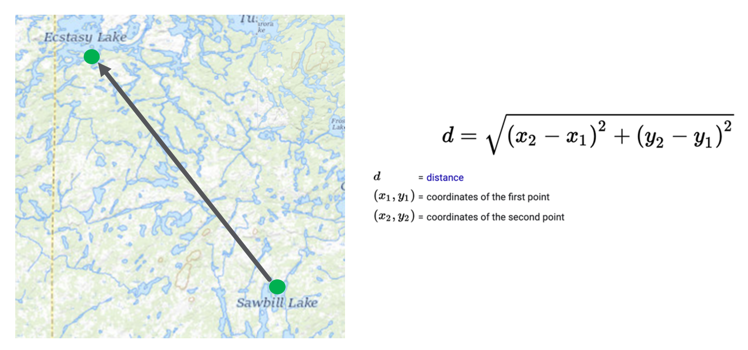
给定地图上的任意两个点,我们可以创建一个公式来计算两个点之间的距离。
给定地图上的两个点,我们可以使用距离公式来计算这两个点之间的距离。 输入只是两个点的坐标,用数字表示,例如其经度和纬度。 对于空间中的两个点,该问题也可以推广到三维中。但在三维空间中,距离的计算增加了一个附加项:高度或z轴。
嵌入工作中的距离计算以类似方式进行。 关键是我们可能只有200或300个维度,而不仅仅是两个或三个维度。 唯一的区别是为每个新维度添加一个距离项。
; 与词嵌入类似
我们在图嵌入运动中获得的许多知识都来自于自然语言处理领域。 数据科学家使用单词嵌入技术创建了英语中任意两个单词或短语之间的精确距离计算。 他们通过在数十亿个文档上训练神经网络,并考虑到周围所有其他单词时,使用特定单词出现在句子中的概率来做到这一点。 周围的单词成为”上下文窗口”。 由此,我们可以有效地对单词进行距离计算。
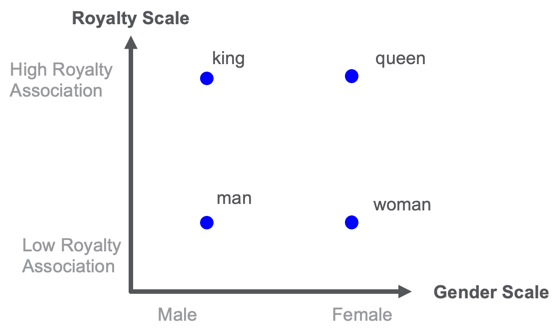
royalty 和gender的词嵌入示例
在上面的示例中,对将”国王”,”皇后”,”男人和女人”一词放在二维地图上进行了想象。一个方面与royalty有关,而一个方面与gender有关。一旦您在这些量表上给每个单词评分后,您就可以找到类似的单词。例如,单词”公主”在皇室性别空间中可能最接近单词”女王”。
这里的挑战是,在这些维度中手动给每个单词评分会花费很长时间。但是通过使用机器学习并设定好一个良好的错误判断函数,该函数可以知道何时可以用一个单词替换另一个单词或在另一个单词之后衔接其他单词。我们可以训练一个神经网络来计算每个单词的嵌入。请注意,如果我们有一个以前从未见过的新词,则此方法将行不通。
英语大约有40000个单词在日常讲话中使用。我们可以将每个单词放入一个知识图谱中,并在每个单词和每个其他单词之间创建成对链接。链接上的权重就是距离。但是,这样效率很低,因为通过使用嵌入,我们可以快速重新计算边缘和权重。
通过以上介绍,就像句子在概念图中的单词之间穿梭一样,我们需要随机遍历我们的EKG,以了解我们的客户,产品等之间的关系。
图形嵌入如何存储?
图形嵌入存储为与我们的EKG的顶点或子图相关联的数字向量。
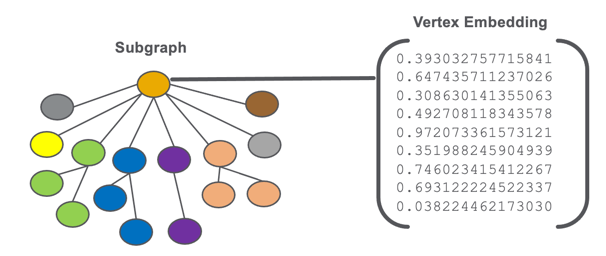
图的一个子图的顶点嵌入的图解。
我们不会在嵌入内容中存储字符串,代码,日期或任何其他类型的非数字数据。存储中只包含数字。
嵌入的大小
图嵌入通常有大约100到300个数值。单个值通常是32位的十进制数,但是在某些情况下,您可以使用更小或更大的数据类型。精度和向量的长度越小,您就可以更快地将该项与类似项进行比较。
大多数比较在嵌入中实际上不需要超过300个数字。如果机器学习算法很强,我们可以把顶点的许多方面压缩成这些值。
每个值都没有语义
数字可能并不代表我们可以直接绑定到图形的单个属性或形状的东西。 我们可能有一个称为”客户年龄”的功能,但是嵌入功能不一定会为年龄功能提供一个数字。 年龄可能会混合成一个或多个数字。
任何顶点都可以嵌入
嵌入可以与EKG中的许多事物相关联。 任何重要的项目,例如客户,产品,商店,供应商,托运人,网络会话或投诉,可能都有其自己的嵌入向量。
我们通常也不会将嵌入与单个属性相关联。 单个属性通常没有足够的信息来证明创建嵌入的工作的合理性。
也有一些项目正在为边和路径创建嵌入,但是它们不像顶点嵌入那么常见。
计算嵌入的上下文窗口
如前所述,用于编码嵌入的顶点周围区域称为上下文窗口。不幸的是,没有简单的算法来确定上下文窗口。有些嵌入可能只查看去年的客户购买来计算嵌入。其他算法可能会查看自客户第一次访问网站以来的终身购买和搜索。理解时间对嵌入(称为时间分析)的影响可能需要额外的规则和调优。很明显,20年前在你的网站上购买过婴儿尿布的顾客和上个月才开始购买的顾客可能会大不相同。
嵌入式与手工编码的特性工程
对于那些熟悉标准图形相似度算法(例如余弦相似度计算)的人,我们希望进行快速比较。 余弦相似度还会创建特征向量,这些特征也是简单的数值。 关键区别在于,手动创建这些特征需要花费时间,而特性工程师需要根据自己的判断来衡量这些值,从而使权重具有相关性。 例如年龄和性别对于衡量一个人对巧克力或香草冰淇淋偏好的是一个很重要的特征,但是与购买一般用途的商品基本上没有关系。
嵌入式软件试图使用机器学习来自动找出与预测某一物品相关的特征。
权衡创建嵌入
在设计EKG时,我们努力不将数据加载到没有价值的内存中。 但嵌入式确实会占用宝贵的内存。所以我们不想疯狂地为那些我们很少比较的东西创建嵌入。 我们希望关注于相似性计算如何实时响应我们用户。
同构图与异构图
关于图嵌入的许多早期研究论文都集中于每个顶点具有相同类型的简单图。这些被称为齐次图或单图。最常见的例子之一是引文图,其中每个顶点都是一篇研究论文,所有链接都指向该论文引用的其他研究论文。社交网络中的每个顶点都是一个人,唯一的链接类型是”跟随”或”好友”,这是另一种同构图。单词嵌入(每个单词或短语都有嵌入)是同构图的另一个示例。
但是,知识图谱通常具有许多不同类型的顶点和许多类型的边。这些被称为多部分图。而且它们使嵌入的计算过程更加复杂。客户图可能具有诸如客户,产品,购买,Web访问,Web搜索,产品评论,产品退货,产品投诉,促销响应,优惠券使用,调查响应等类型。从复杂数据集创建嵌入可能需要花费一些时间设置和调整机器学习算法。
; 如何计算知识图嵌入(EKG)
在本文中,我们假设您的EKG比较大。根据定义,EKG不能放在单个服务器节点的内存中,必须分布在数十或数百台服务器上。这意味着像创建邻接矩阵这样的简单技术是不可能的。我们需要在分布式图簇上缩放和工作的算法。
大约有1400篇关于谷歌学术的论文提到了”知识图嵌入”的主题。我并不是所有算法方面的专家。一般来说,他们分为两类。
- 图卷积神经网络(GCN)
- 随机游走(random walk)
下面将简要介绍这两种方法。
图卷积神经网络(GCN)
GCN算法借鉴了卷积神经网络在图像处理中所做的工作。这些算法通过观察一个给定像素周围的像素来得出网络的下一层。由于像素之间的距离是均匀且可预测的,因此图像被称为”欧几里得”空间。 GCNs使用大致相同的方法来查看当前的顶点,但是概念上的距离是不均匀的和不可预测的。
随机游走(random walk)
这些算法倾向于遵循自然语言处理方面的研究。它们的工作原理是从一个目标节点开始随机遍历所有节点。这些路径有效地形成了关于目标顶点的句子,然后这些序列就像NLP算法一样被使用。
总结
这篇文章中的故事和隐喻解释了什么是图形嵌入以及如何使用它们来加速实时分析。 尽管现阶段计算嵌入的产品还不成熟,但我认为从已发表的大量研究中您会看到这是一个活跃的研究领域。 我认为,就像AlexNet在图像分类中取得突破并且BERT为NLP设定新标准一样,在接下来的几年中,我们将看到图形嵌入将在创新分析领域占据中心地位。
对于今年参加NeurIPS 2020会议人,有114个与嵌入相关可以看出嵌入显然是深度学习中的热门话题。
作者:Dan McCreary
deephub翻译组
Original: https://blog.csdn.net/m0_46510245/article/details/110110976
Author: deephub
Title: 10分钟了解图嵌入
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595742/
转载文章受原作者版权保护。转载请注明原作者出处!