

文章基本信息
Learning Intents behind Interactions with Knowledge Graph
WWW2021 CCF-A 论文地址: KGIN
Keywords:推荐系统、知识图谱、图神经网络
主要思想:在用户特征和知识图谱边上交流特征等信息来对朋友进行排行,进而进行朋友推荐
*
– 文章基本信息
– ABSTRACT
– 1 INTRODUCTION
– 2 PROBLEM FORMULATION
–
+ Interaction Data
+ Knowledge Graph
+ Task Description
– 3 METHODOLOGY
–
+ 3.1 User Intent Modeling
+
* 3.1.1 Representation Learning of Intents.
* 3.1.2 Independence Modeling of Intents.
+ 3.2 Relational Path-aware Aggregation
+
* 3.2.1 Aggregation Layer over Intent Graph.
* 3.2.2 Aggregation Layer over Knowledge Graph.
* 3.2.3 Capturing Relational Paths.
+ 3.3 Model Prediction
+ 3.4 Model Optimization
+ 3.5 Model Analysis
+
* 3.5.1 Model Size.
* 3.5.2 Time Complexity.
+ 4 EXPERIMENTS
+
* 4.1 Experimental Settings
*
– 4.1.1 Dataset Description.
– 4.1.2 Evaluation Metrics
– 4.1.3 Alternative Baselines
– 4.1.4 Parameter Settings.
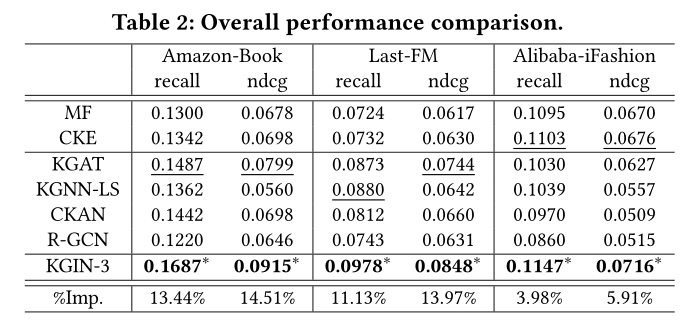
+ 4.2 Performance Comparison (RQ1)
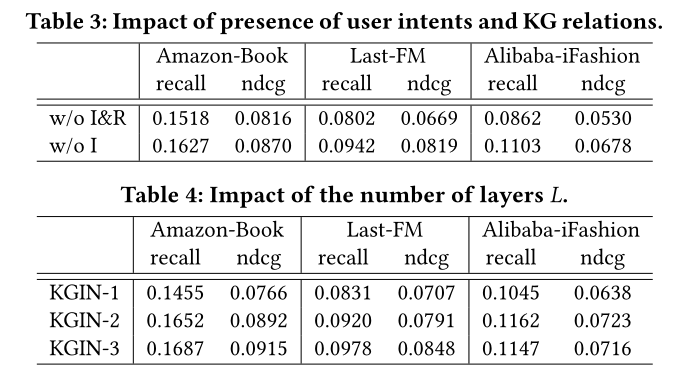
+ 4.3 Relational Modeling of KGIN (RQ2)
+ 4.4 Explainability of KGIN (RQ3)
ABSTRACT
目前的GNN-based模型在关系建模上属于粗粒度的建模。存在两个:
- 没有在细粒度的意图级别上识别用户-项目关系
- 未利用关系依赖性来保留远程连接的语义
文章提出了Knowledge Graph-based Intent Network(KGIN)
从技术上讲,我们将每个意图建模为 KG 关系的仔细组合,加强 不同项目的独立性,以获得更好的模型能力和可解释性。此外,我们为 GNN 设计了一种新的信息聚合方案,它递归地集成了远程连接的关系序列(即关系路径)。该方案允许我们提取有关用户意图的有用信息,并将其编码为用户和项目的表示。
在三个基准数据集上的实验结果表明,KGIN 比 KGAT 、KGNN-LS 和 CKAN 等最先进的方法取得了显着的改进。进一步的分析表明,KGIN 通过识别有影响的意图和关系路径为预测 提高了可解释性。实现可在 https://github.com/huangtinglin/Knowledge_Graph_based_Intent_Network 获得。
1 INTRODUCTION
知识图谱(KG)在 提高推荐的准确性和可解释性方面显示出巨大的潜力。 KG中丰富的实体和关系信息可以补充用户和物品之间的关系建模。它们不仅揭示了项目之间的各种 相关性(例如,由一个人共同导演),而且还可用于 解释用户偏好(例如,将用户对电影的选择归因于其导演)。
以前的工作使用KG三元组生成嵌入,并将其视为 先验或内容信息以补充项目表示。后续的一些研究通过 丰富用户和项目之间多跳路径,以此更好的表征用户-项目关系。然而,这些方法难以获得高质量的路径,遭受各种问题,如劳动密集型特征工程 、不同领域的可移植性差 和 性能不稳定。
最近,基于 GNN的端到端模型变成了一种技术趋势。关键思想是 利用信息聚合的思想,它可以有效地将 多跳邻居信息集成到表示中。受益于连接建模和表示学习的集成,这些基于 GNN 的模型在推荐方面取得了可喜的表现。
现在的GNN-based方法有两个不足:
(1)User Intent
目前研究 没有考虑更细粒度的意图级别的用户-项目关系。忽略了一个事实:一个用户可能会有多个意图,驱使用户去消费不同的产品。
(2)Relational Paths
目前的信息聚合机制都是 基于节点的,中心节点从邻居节点收集信息,但是没有区分这些信息来自于那一条关系路径(Relational Path),因此不能充分第捕获关系中的交互。
KGIN有两个组成部分来解决上述限制:
(1)User Intent Modeling
每个用户-项目交互都包含潜在的意图,并且可以用向量表示,但是难以解释。因此, 将每个意图与KG关系的分布相关联,说明关系组合的重要性。
技术上说,就是intent的嵌入表示,是关系嵌入表示的组合,其中更重要的关系占比更大。此外,还引入独立性约束,鼓励不同intent的差异性,以此得到更好地可解释性。
(2)Relational Path-aware Aggregation
与基于节点的聚合机制不同,文章将 关系路径视为信息通道,并将每个通道编成一个向量表示。因为user-intent-item和KG三元组是异构的,需要设置不同的聚合策略,以分别提取用户的行为模式和项目的相关性。
我们将这项工作的贡献总结为:
- 在基于 KG 的推荐中揭示交互背后的用户意图,以获得更好的模型容量和可解释性
- 提出了一种新模型KGIN,它在GNN 范式下以更细粒度的意图和关系路径的远程语义考虑用户-项目关系
- 对三个基准数据集进行实证研究以证明 KGIN 的优越性。
2 PROBLEM FORMULATION
我们首先介绍结构数据:用户-项目交互和知识图,然后制定我们的任务。
Interaction Data
U U U是users的集合, I I I是items的集合
O + = { ( u , i ) ∣ u ∈ U , i ∈ I } O^+={(u,i)|u∈U,i∈I}O +={(u ,i )∣u ∈U ,i ∈I }是观察到的反馈集合,
我们关注推荐中的 隐式反馈 ,其中用户提供的有关其偏好的信号是隐式的(例如,查看、点击、购买)。其中每个 ( u , i ) (u,i)(u ,i ) 对表示 用户 u u u 之前与项目 i i i 进行了交互。在之前的一些论文中,比如 KGAT,引入了一个 额外的交互关系来显式呈现用户-项目关系并将 ( u , i ) (u,i)(u ,i ) 对转换为( u , i n t e r a c t − w i t h , i ) (u,interact-with,i)(u ,i n t e r a c t −w i t h ,i ) 三元组。因此,用户-项目交互可以与 KG 无缝结合。
Knowledge Graph
KG 以 异构图或异构信息网络的形式存储现实世界事实的结构化信息,例如项目属性、分类法或外部常识知识 。
V V V是真实世界中实体的集合,
R R R是关系的集合,表示一些规范和反方向的关系,例如( e . g . , d i r e c t o r , d i r e c t e d − b y ) (e.g., director,directed-by)(e .g .,d i r e c t o r ,d i r e c t e d −b y )
G = ( h , r , t ) ∣ h , t ∈ V , r ∈ R G = {(h,r,t)|h,t∈V, r∈R}G =(h ,r ,t )∣h ,t ∈V ,r ∈R是三元组的集合,( h , r , t ) (h,r,t)(h ,r ,t )三元组表示从 头实体h到尾实体t存在r关系。通过项目和KG实体之间的映射( I ⊂ V ) (I ⊂ V)(I ⊂V ),KG能够分析项目并为交互数据提供补充信息。
Task Description
给定交互数据O + O^+O + 和知识图谱 G G G,我们的知识感知推荐任务是学习一个可以预测用户 采用某个项目的可能性的函数。
3 METHODOLOGY
我们现在提出基于知识图的意图网络(KGIN)。图 3 展示了 KGIN 的工作流程。它由两个关键组成部分组成:
(1) 用户意图建模,它使用多个潜在意图来描述用户-项目关系,并将每个意图表述为 KG 关系的注意力组合,同时鼓励不同意图相互独立;
(2) 关系路径感知聚合,突出了远程连接中的关系依赖性,从而保留了关系路径的整体语义。
KGIN 最终产生用户和项目的高质量表示。
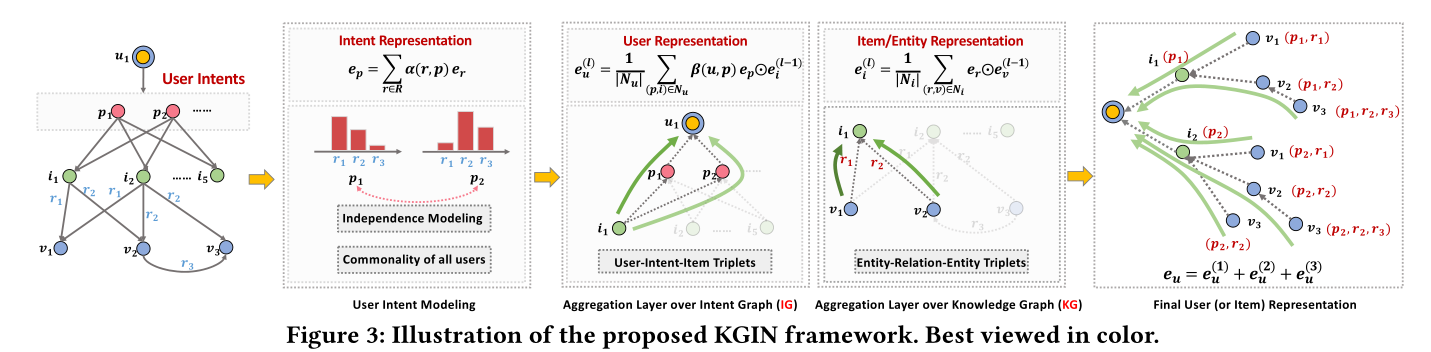

; 3.1 User Intent Modeling
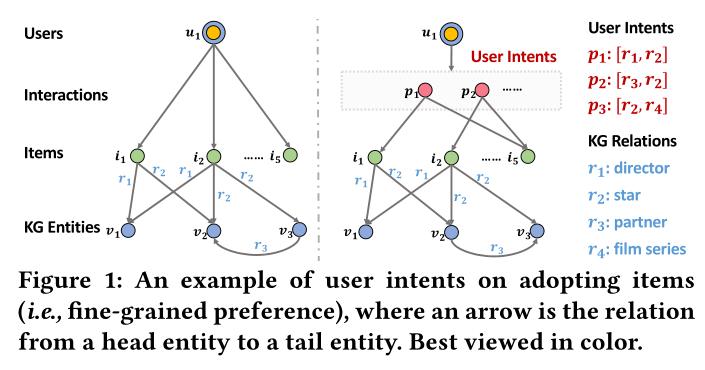
与之前基于 GNN 的研究不同,假设用户和物品之间 没有或只有一种交互关系,我们的目标是捕捉 用户行为受多种意图影响的直觉。
这里我们将意图定义为用户选择商品的原因,它反映了所有用户行为的共性。以电影推荐为例,可能的意图是对电影属性的不同考虑,例如明星和合作伙伴的组合,或者导演和类型的组合。
不同的意图抽象出不同的用户行为模式。这可以通过更细粒度的假设来增强广泛使用的协同过滤 效果——由 相似意图驱动的用户对项目有相似的偏好。
这种直觉促使我们 以意图的粒度对用户-项目关系进行建模。
P P P是所有用户共享的意图集合,以此可以将每个( u , i ) (u,i)(u ,i )分解为{ ( u , p , i ) ∣ p ∈ P } {(u,p,i)|p∈P}{(u ,p ,i )∣p ∈P }。因此,可以 将用户-项目交互数据重组为一个异构图,称为i n t e n t g r a p h ( I G ) intent graph(IG)i n t e n t g r a p h (I G ),这与以往工作中采用的同构协作图不同。
3.1.1 Representation Learning of Intents.
虽然我们可以用潜在向量表达这些意图,但 很难明确识别每个意图的语义。
一种直接的解决方案是将每个意图与一个 KG 关系耦合,这是由 KTUP提出的。然而,该方案仅孤立地考虑单个关系,没有考虑关系的交互和组合,从而无法提炼用户意图的高级概念。例如,关系 r1 和 r2 的组合对意图 p1 有影响,而关系 r3 和 r4 对意图 p2 的贡献更大。
因此,我们为每个意图 p ∈ P p ∈ P p ∈P 分配了 KG 关系的分布——从技术上讲,运用注意力策略来创建意图嵌入:
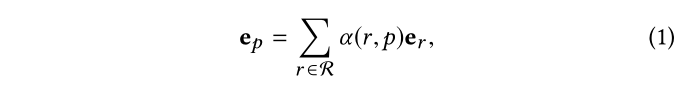
其中 e r e_r e r 是关系 r 的 ID 嵌入,它被分配了一个注意力分数 α ( r , p ) α(r,p)α(r ,p ) 以量化其重要性,形式上:
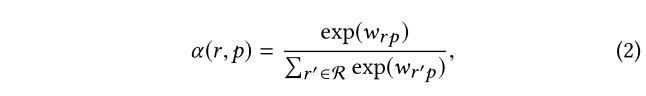
其中 w r p w_{rp}w r p 是特定于特定关系 r r r 和特定意图 p p p 的可训练权重。在这里,为了简单起见,我们使用权重,并在未来的工作中对复杂的注意力模块进行进一步探索。
值得一提的是,注意力并不是针对单个用户量身定制的,而是 提炼出所有用户的共同模式。
; 3.1.2 Independence Modeling of Intents.
不同的意图应该包含关于用户偏好的不同信息 。如果一个意图可以被其他意图推断出来,那么描述用户-项目关系可能是多余的并且信息量较少;相比之下,具有独特信息的意图将提供一个有用的角度来表征用户的行为模式。
因此,为了更好的模型容量和可解释性,我们鼓励意图的表示彼此不同。这里我们引入了一个 独立建模模块来指导 独立意图的表征学习。该模块可以通过应用统计度量(例如互信息、Pearson 相关 和距离相关)作为 正则化器来简单地实现。这里我们提供两种实现:
- Mutual information.
我们最小化任何两个不同意图的表示之间的互信息,以 量化它们的独立性。这种想法与对比学习不谋而合。更正式地说,独立性建模是:
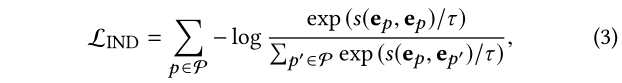
其中s ( ⋅ ) s(·)s (⋅)是测量任意两个意图表示的关联的函数,这里设置为余弦相似度函数;τ ττ是softmax函数中温度的超参数。
- Distance correlation.
它测量任何两个变量的线性和非线性关联,当且仅当这些变量独立时,其系数为零。
最小化用户意图的距离相关性使我们能够减少不同意图的依赖性,其公式为:
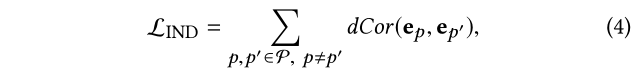
其中d C o r ( ⋅ ) dCor(·)d C o r (⋅) 是意图p p p 和p ′ p’p ′ 之间的距离相关性:
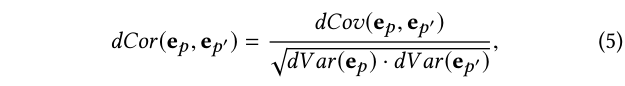
其中d C o r ( ⋅ ) dCor(·)d C o r (⋅) 是两个表示的距离协方差,d V a r ( ⋅ ) dV ar(·)d V a r (⋅) 是每个意图表示的距离方差。
优化这个损失允许我们鼓励不同意图之间的分歧,并使这些意图具有明显的边界,从而赋予用户意图更好的可解释性。
3.2 Relational Path-aware Aggregation
在对用户意图进行建模后,我们继续在基于 GNN 的范式下对用户和项目进行表示学习。
之前基于 GNN 的推荐模型已经表明,邻域聚合方案是一种很有效的端到端方式,可以将多跳邻居集成到表示中。更具体地说,自我节点的表示向量是通过递归聚合和转换其多跳邻居的表示来计算的。
文章中之处目前的聚合方式是基于节点的,会限制结构化知识的收益。原因有两个,如下:
- 聚合器注重于组合邻域信息,而没有区分它们来自于哪条路径。
- 基于当前结点,通过注意力机制来对KG关系进行建模,以控制邻居的传播,会限制KG关系对节点的贡献。并且没有显式地捕捉关系依赖。
我们旨在设计一种关系路径感知聚合方案来解决这两个限制。
3.2.1 Aggregation Layer over Intent Graph.
我们首先继续改进来自 IG 的协作信息。
如前所述,CF 效应通过假设行为相似的用户对项目有相似的偏好来表征用户模式是强大的。这激励我们将个人历史(即用户之前采用的项目)视为单个用户的预先存在的特征。此外,在我们的 IG 中,我们可以通过假设具有相似意图的用户对项目表现出相似的偏好,在用户意图的粒度级别上捕获更细粒度的模式。考虑 IG 中的用户 u,我们使用 N u = { ( p , i ) ∣ ( u , p , i ) ∈ C } N_u= {(p,i)|(u,p,i) ∈ C}N u ={(p ,i )∣(u ,p ,i )∈C } 来表示意图感知历史和围绕 u 的一阶连通性。从技术上讲,我们可以整合来自历史项目的意图感知信息来创建 用户 u u u 的表示:
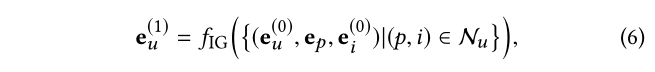
其中 e u ( 1 ) ∈ R d e^{(1)}u ∈ R^d e u (1 )∈R d 用户 u 的表示; f I G ( ⋅ ) f{IG}(·)f I G (⋅) 是聚合函数,用于表征每个一阶连接 ( u , p , i ) (u,p,i)(u ,p ,i )
这里我们将 f I G ( ⋅ ) f_{IG}(·)f I G (⋅) 实现为:
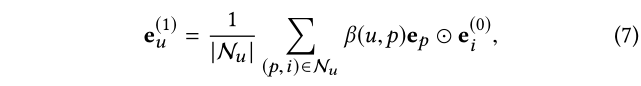
其中e i ( 0 ) e^{(0)}_i e i (0 ) 是项目 i i i 的 ID 嵌入; ⊙ ⊙⊙ 是元素积。我们通过两个见解来利用它。
(1)对于给定的用户,不同的意图激励贡献不同的行为。因此,我们引入了注意力分数 β ( u , p ) β(u,p)β(u ,p ) 来区分 p p p 的重要性:
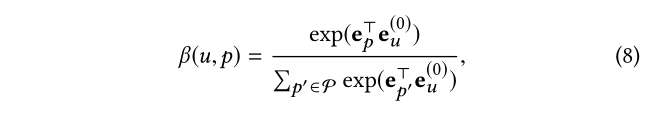
其中 e u ( 0 ) ∈ R d e^{(0)}_u ∈ R^d e u (0 )∈R d 用户 u 的 ID 嵌入,以使重要性得分个性化。
(2) 与之前研究中使用 衰减因子或正则化项的想法不同,我们强调了 意图关系在聚合过程中的作用。因此,我们通过逐元素乘积 β ( u , p ) e p ⊙ e i ( 0 ) β(u,p)e_p⊙ e^{(0)}_i β(u ,p )e p ⊙e i (0 ) 来构造项目 i 的消息。因此,我们能够在用户表示中明确表达一阶意图感知信息。
; 3.2.2 Aggregation Layer over Knowledge Graph.
然后我们专注于 KG 中的聚合方案。由于一个实体可以涉及多个 KG 三元组,因此它可以 将其他连接的实体作为其属性,反映 项之间的内容相似性。例如,电影《霍比特人》可以用其导演彼得杰克逊和明星马丁弗里曼来形容。
更正式地说,我们使用 N i = { ( r , v ) ∣ ( i , r , v ) ∈ G } N_i= {(r,v)|(i,r,v) ∈ G}N i ={(r ,v )∣(i ,r ,v )∈G } 来表示项目 i 的属性和一阶连通性,然后将来自连接实体的关系感知信息整合到生成项目 i 的表示:
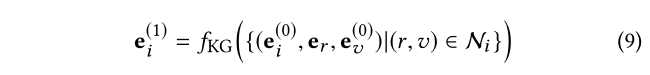
其中 e u ( 1 ) ∈ R d e^{(1)}u ∈ R^d e u (1 )∈R d 从一阶连通性中收集信息的表示; f K G ( ⋅ ) f{KG}(·)f K G (⋅) 是从每个连接( i , r , v ) (i,r,v)(i ,r ,v )中提取和整合信息的聚合函数。
在这里,我们考虑了聚合器中的关系上下文。直观地,每个 KG 实体在不同的关系上下文中具有不同的语义和含义。例如,实体 Quentin Tarantino 分别在两个三元组(Quentin Tarantino,director,Django Unchained)和(Quentin Tarantino,star,Django Unchained)中表达与导演和明星概念相关的信号。
然而,之前的研究仅通过注意力机制对衰减因子中的 KG 关系进行建模,以控制 Quentin Tarantino 对 Django Unchained 表示的贡献。相反,我们将聚合器中的关系上下文建模为:
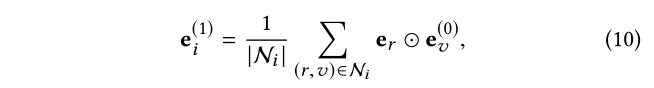
其中 e v ( 0 ) e_v^{(0)}e v (0 ) 与 实体v v v 的 ID 嵌入相对应。
对于每个三元组( i , r , v ) (i,r,v)(i ,r ,v ),我们通过将关系 r 建模为 投影或旋转算子来设计关系消息 e r ⊙ e v ( 0 ) e_r⊙ e_v^{(0)}e r ⊙e v (0 )。结果,关系消息能够揭示三元组携带的不同含义,即使它们得到相同的实体。类似地,我们可以获得每个 KG 实体 v ∈ V v ∈ V v ∈V 的表示e v ( 1 ) e_v^{(1)}e v (1 )
3.2.3 Capturing Relational Paths.
在对等式 (6) 和 (9) 中的一阶连通性进行建模后,我们进一步堆叠更多聚合层以收集来自高阶邻居的有影响的信号。从技术上讲,我们 递归地将 layer l l l 之后的 user u u u 和 item i i i 表示为:
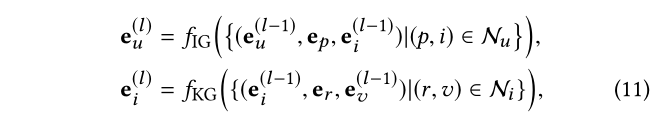
其中 e u ( l − 1 ) , e i ( l − 1 ) , e v ( l − 1 ) e^{(l−1)}_u, e^{(l−1)}_i, e^{(l−1)}_v e u (l −1 ),e i (l −1 ),e v (l −1 )分别表示 u s e r u 、 i t e m i 和 e n t i t y v user u、item i 和 entity v u s e r u 、i t e m i 和e n t i t y v的表示,存储了从它们的 ( l − 1 ) (l-1)(l −1 )跳邻居传播的关系信号。
受益于我们的关系建模,这些表示能够存储多跳路径的整体语义,并突出关系依赖性。设
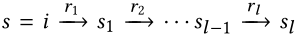
是以项目i为根的l-hop路径,它包含一系列连接的三元组。其关系路径仅表示为关系序列,即( r 1 , r 2 , ⋅ ⋅ ⋅ , r l ) (r1,r2,···,rl)(r 1 ,r 2 ,⋅⋅⋅,r l )。我们可以将表示 e i ( l ) e^{(l)}_i e i (l ) 改写如下:
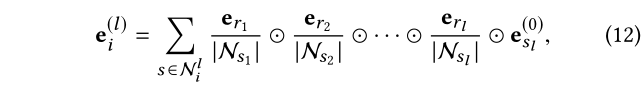
其中 N i l N^l_i N i l 是 所有 i 的 l − h o p i的l-hop i 的l −h o p 路径的集合。显然,这种表示反映了关系之间的相互作用并保留了路径的整体语义。这与当前知识感知推荐中采用的聚合机制有很大不同,后者忽略了 KG 关系的重要性,因此无法捕获关系路径。
; 3.3 Model Prediction
在 L L L 层之后,我们获得u s e r u user _u u s e r u 和 i t e m i item _i i t e m i 在不同层的表示,然后将它们总结为最终的表示:
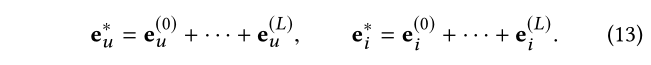
通过这样做,路径的意图感知关系和 KG 关系依赖被编码在最终表示中。
此后,我们在用户和项目表示上使用内积来预测用户采用该项目的可能性:
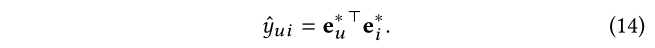
3.4 Model Optimization
我们选择成对 BPR 损失来重建历史数据。
具体来说,它认为对于给定的用户,她的历史项目应该比未观察到的项目分配更高的预测分数:
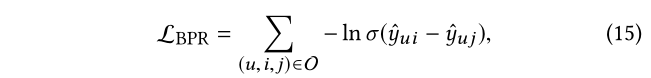
其中 O = { ( u , i , j ) ∣ ( u , i ) ∈ O , ( u , j ) ∈ O − } O = {(u,i,j)|(u,i) ∈ O ,(u,j) ∈ O^−}O ={(u ,i ,j )∣(u ,i )∈O ,(u ,j )∈O −}是由观察到的相互作用O O O和未观察到的对应项O − O^−O −组成的训练数据集; σ ( ⋅ ) σ(·)σ(⋅) 是 sigmoid 函数。
通过结合独立性损失和 BPR 损失,我们最小化以下目标函数来学习模型参数:
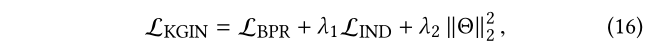
其中 Θ = { e u ( 0 ) , e v ( 0 ) , e r , e p , w ∣ u ∈ U , v ∈ V , p ∈ P } Θ ={e^{(0)}_u, e^{(0)}_v,e_r,e_p,w|u ∈ U,v ∈ V,p ∈ P}Θ={e u (0 ),e v (0 ),e r ,e p ,w ∣u ∈U ,v ∈V ,p ∈P }为模型参数集(注意项目集 I ⊂ V I ⊂ V I ⊂V, λ 1 λ_1 λ1 和λ 2 λ_2 λ2 分别是控制独立性损失(等式6)和L 2 L_2 L 2 正则化项的两个超参数。
; 3.5 Model Analysis
3.5.1 Model Size.
最近的研究 表明,使用非线性特征变换可能会使 GNN 难以训练。因此,在 KGIN 的聚合方案中,我们丢弃了非线性激活函数和特征变换矩阵。因此,KGIN 的模型参数包括
(1) 用户的 ID 嵌入、KG 实体(包括项目)和 KG 关系 { e u ( 0 ) , e v ( 0 ) , e r ∣ u ∈ U , v ∈ V } {e^{(0)}_u,e^{(0)}_v,er|u ∈ U,v ∈ V}{e u (0 ),e v (0 ),e r ∣u ∈U ,v ∈V };
(2) 用户意图的 ID 嵌入 { e p ∣ p ∈ P } {e_p|p ∈ P}{e p ∣p ∈P } 和注意力权重 w w w。
3.5.2 Time Complexity.
KGIN 的时间成本主要来自用户意图建模和聚合方案。在 IG 上的聚合中,用户表示的计算复杂度为 O ( L ∣ C ∣ d ) O(L|C|d)O (L ∣C ∣d ),其中 L 、 ∣ C ∣ L、|C|L 、∣C ∣ 和 d d d 分别表示层数、IG 中的三元组数和嵌入大小。
在 KG 上的聚合中,更新实体表示的时间成本是 O ( L ∣ G ∣ d ) O(L|G|d)O (L ∣G ∣d ),其中 |G|是 KG 三胞胎的数量。对于独立建模,距离相关的代价是 O ( ∣ P ∣ ( ∣ P ∣ − 1 ) / 2 ) O(|P |(|P | − 1)/2)O (∣P ∣(∣P ∣−1 )/2 ),其中 ∣ P ∣ |P|∣P ∣是用户意图的数量。
总的来说,整个训练时期的时间复杂度为 O ( L ∣ C ∣ d L ∣ G ∣ d ∣ P ∣ ( ∣ P ∣ − 1 ) / 2 ) O(L|C|d L|G|d |P |(|P | − 1)/2)O (L ∣C ∣d L ∣G ∣d ∣P ∣(∣P ∣−1 )/2 )。在相同的实验设置(即不同层的表示大小)下,KGIN 具有与 KGAT 和 CKAN 相当的复杂性。
4 EXPERIMENTS
我们提供了实证结果来证明我们提出的 KGIN 的有效性。实验旨在回答以下研究问题来证明KGIN的有效性:
(1)和soat知识型推荐系统相比,KGIN表现怎么样
(2)KGIN的设计(用户intent的数量和独立性,关系路径的深度)对KGIN模型的影响
(3)KGIN能够提供对用户intent的洞察力,并有更直观的可解释性
4.1 Experimental Settings
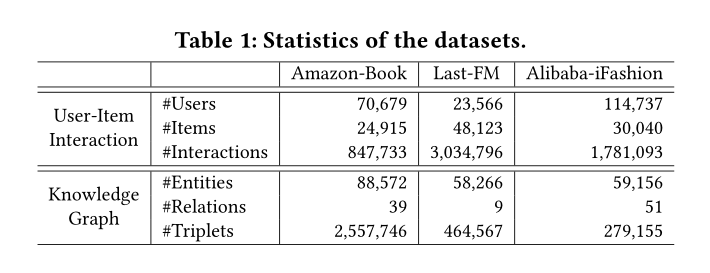
4.1.1 Dataset Description.
我们在实验中使用三个基准数据集进行书籍、音乐和时尚服装推荐:
(1)我们使用 KGAT 发布的 Amazon-Book 和 Last-FM 数据集;
(2)我们进一步引入阿里巴巴-iFashion 数据集 [8] 来研究项目知识的有效性。这是从阿里巴巴网上购物系统收集的时尚服装数据集。服装被视为被推荐的项目
为了保证数据质量,将丢弃交互少于是个的用户和项目,过滤掉少于是个三元组的KG实体。
在表一总结了数据集的统计数据,如下
; 4.1.2 Evaluation Metrics
使用recall@K和ndcg@K
默认K是20,报告测试集中所有用户的平均指标。
4.1.3 Alternative Baselines
将KGIN与SOTA方法进行比较,包括MF,CKE,KGAT,KGNN-LS,CKAN和RGCN。
4.1.4 Parameter Settings.
我们在 PyTorch 中实现了我们的 KGIN 模型,并发布了我们的实现(代码、数据集、参数设置和训练日志)以促进可重复性。为了公平比较,我们将所有方法的 ID embedding的大小固定为 64,优化器为 Adam,批大小为 1024。

; 4.2 Performance Comparison (RQ1)
4.3 Relational Modeling of KGIN (RQ2)
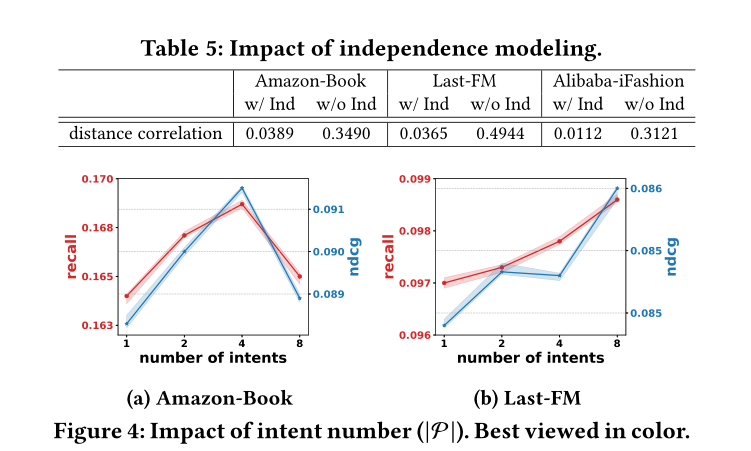
; 4.4 Explainability of KGIN (RQ3)

Original: https://blog.csdn.net/qq_41101762/article/details/119795926
Author: 天南浅蓝
Title: 【paper笔记】Learning Intents behind Interactions with Knowledge Graph
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595124/
转载文章受原作者版权保护。转载请注明原作者出处!