

Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis
GitHub:https://github.com/CCChenhao997/DualGCN-ABSA
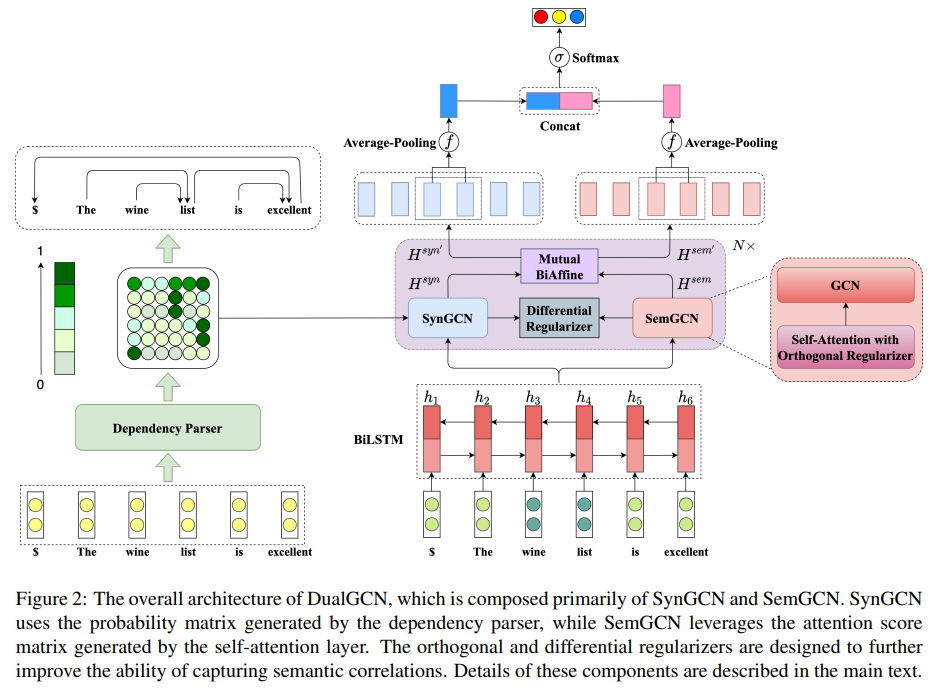

SynGCN:利用依赖弧概率矩阵,对比parser的最终输出包含更丰富的语法信息;
SemGCN:自注意力——捕获语义关联;
Mutual BiAffine:在SynGCN和SemGCN模块间有效交换相关特征;
两个Regularizer:
SemGCN里的.Orthogonal Regularizer:期望词间注意力分数不重叠→注意力矩阵正交,加入了正交正则化;
SynGCN和SemGCN之间的.Differential Regularizer:期望从 SynGCN 和 SemGCN 模块学习的两种特征表示能够包含语法、语义不同信息。
Multi-Label Few-Shot Learning for Aspect Category Detection;
Abstract:Aspect category detection (ACD) in sentiment analysis aims to identify the aspect categories mentioned in a sentence. In this paper, we formulate ACD in the few-shot learning scenario. However, existing few-shot learning approaches mainly focus on single-label predictions. These methods can not work well for the ACD task since a sentence may contain multiple aspect categories. Therefore, we propose a multi-label few-shot learning method based on the prototypical network. To alleviate the noise, we design two effective attention mechanisms. The support-set attention aims to extract better prototypes by removing irrelevant aspects. The query-set attention computes multiple prototype-specific representations for each query instance, which are then used to compute accurate distances with the corresponding prototypes. To achieve multi-label inference, we further learn a dynamic threshold per instance by a policy network. Extensive experimental results on three datasets demonstrate that the proposed method significantly outperforms strong baselines.
情感分析中的方面类别检测(Aspect category detection, ACD)的目的是识别句子中提到的方面类别。在本文中,我们提出了在few-shot学习场景下的ACD。然而,现有的few-shot学习方法主要集中在单标签预测。这些方法不能很好地用于ACD任务,因为一个句子可能包含多个方面类别。因此,我们提出了一种基于原型网络的多标签few-shot学习方法。为了减少噪音,我们设计了两种有效的注意机制。支持集关注的目的是通过移除不相关的方面来提取更好的原型。查询集注意力为每个查询实例计算多个特定于原型的表示,然后使用这些表示来计算与相应原型的精确距离。为了实现多标签推理,我们进一步通过策略网络学习每个实例的动态阈值。在三个数据集上的大量实验结果表明,该方法的性能明显优于强基线。
DynaSent: A Dynamic Benchmark for Sentiment Analysis
GitHub:https://github.com/cgpotts/dynasent
Abstract:We introduce DynaSent (‘Dynamic Sentiment’), a new English-language benchmark task for ternary (positive/negative/neutral) sentiment analysis. DynaSent combines naturally occurring sentences with sentences created using the open-source Dynabench Platform, which facilities human-and-model-in-the-loop dataset creation. DynaSent has a total of 121,634 sentences, each validated by five crowdworkers, and its development and test splits are designed to produce chance performance for even the best models we have been able to develop; when future models solve this task, we will use them to create DynaSent version 2, continuing the dynamic evolution of this benchmark. Here, we report on the dataset creation effort, focusing on the steps we took to increase quality and reduce artifacts. We also present evidence that DynaSent’s Neutral category is more coherent than the comparable category in other benchmarks, and we motivate training models from scratch for each round over successive fine-tuning.
我们引入了DynaSent (动态情绪),一个新的三元(正面/负面/中性)情绪分析基准任务。DynaSent 将自然出现的句子与使用开源的Dynabench平台创建的句子结合起来,该平台提供了人与循环中模型的数据集创建功能。DynaSent 总共有121634句话,每句话都经过了5个众包工人的验证,其开发和测试拆分旨在为我们所能开发的最好的模型提供机会表现;当未来的模型解决这个任务时,我们将使用它们来创建DynaSent 版本2,继续这个基准的动态演变。在这里,我们报告了数据集创建工作,重点是我们为提高质量和减少工件所采取的步骤。我们还提供了证据表明DynaSent 的中立类别比其他基准中的类别更连贯,我们在每一轮的连续微调中从头开始激励训练模型。
A Unified Generative Framework for Aspect-based Sentiment Analysis
GitHub:https://github.com/yhcc/BARTABSA
Abstract:Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA.
Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation. Based on the unified formulation, we exploit
the pre-training sequence-to-sequence model BART to solve all ABSA subtasks in an endto-end framework. Extensive experiments on four ABSA datasets for seven subtasks demonstrate that our framework achieves substantial performance gain and provides a real unified end-to-end solution for the whole ABSA subtasks, which could benefit multiple tasks.
基于方面的情感分析(ABSA)旨在识别方面术语及其对应的情感极性和方面术语。ABSA中有7个子任务。大多数研究只关注这些子任务的子集,导致了各种复杂的ABSA模型,难以在统一的框架下解决这些子任务。本文将每个子任务目标重新定义为一个由指针指标和情感类指标混合而成的序列,将所有ABSA子任务转化为一个统一的生成公式。在此基础上,我们利用训练前的序列到序列模型BART,在端到端框架下解决所有ABSA子任务。在4个ABSA数据集上对7个子任务进行的大量实验表明,我们的框架取得了显著的性能提高,并为整个ABSA子任务提供了一个真正的统一的端到端解决方案,可以使多个任务受益。
Deep Context- and Relation-Aware Learning for Aspect-based Sentiment Analysis
Abstract:Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect-opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
现有的基于方面的情感分析(ABSA)采用了统一的方法,允许子任务之间的交互关系。然而,我们发现这些方法倾向于基于方面和观点术语的字面意义来预测极性,并且主要考虑词层面上的子任务之间的隐性关系。此外,识别具有不同极性的多个方面观点对更具有挑战性。因此,ABSA还需要对语境信息的方面和观点有一个全面的了解。本文提出了深度情境化关系感知网络(Deep Contextualized relationship – aware Network, DCRAN),该网络基于Aspect和Opinion Propagation以及Explicit Self-Supervised Strategies两个模块,允许具有深度情境信息的子任务之间建立交互关系。特别地,我们为ABSA设计了新颖的自我监督策略,具有处理多个方面的优势。实验结果表明,在三种广泛使用的基准上,DCRAN的性能明显优于以前最先进的方法。
DNN-driven Gradual Machine Learning for Aspect-term Sentiment Analysis
Abstract:Recent work has shown that Aspect-Term Sentiment Analysis (ATSA) can be performed by Gradual Machine Learning (GML), which begins with some automatically labeled easy instances, and then gradually labels more challenging instances by iterative factor graph inference without manual intervention. As a non-i.i.d learning paradigm, GML leverages shared features between labeled and unlabeled instances for knowledge conveyance. However, the existing GML solution extracts sentiment features based on pre-specified lexicons, which are usually inaccurate and incomplete and thus lead to inadequate knowledge conveyance. In this paper, we propose a Deep Neural Network (DNN) driven GML approach for ATSA, which exploits the power of DNN in feature representation for gradual learning. It first uses an unsupervised neural network to cluster the automatically extracted features by their sentiment orientation. Then, it models the clustered features as factors to enable implicit knowledge conveyance for gradual inference in a factor graph. To leverage labeled training data, we also present a hybrid solution that fulfills gradual learning by fusing the influence of supervised DNN predictions and implicit knowledge conveyance in a unified factor graph. Finally, we empirically evaluate the performance of the proposed approach on real benchmark data. Our extensive experiments have shown that the proposed approach consistently achieves the state-of-the-art performance across all the test datasets in both unsupervised and supervised settings and the improvement margins are considerable.
最近的研究表明,可以通过逐步机器学习(GML)实现方面术语情感分析(ATSA),该方法首先自动标记一些容易的实例,然后通过迭代因子图推理逐步标记更具挑战性的实例,无需人工干预。在non-i.i学习范式中,GML利用标记和未标记实例之间的共享特性来传递知识。然而,现有的GML解决方案基于预设的词汇抽取情感特征,通常不准确、不完整,导致知识传递不足。在本文中,我们提出了一种由深度神经网络(DNN)驱动的GML方法来实现ATSA,该方法利用了DNN在特征表示方面的强大能力来实现逐步学习。首先利用无监督神经网络对情感倾向性特征进行聚类;然后将聚类特征建模为因子,实现隐性知识传递,在因子图中进行逐步推理。为了利用标记训练数据,我们还提出了一种混合解决方案,通过在统一的因子图中融合监督DNN预测和隐性知识传递的影响来实现逐步学习。最后,我们在实际的基准数据上对所提方法的性能进行了实证评估。我们的大量实验表明,所提出的方法在所有的测试数据集上,无论是无监督设置还是监督设置,都始终保持了最先进的性能,改善幅度是相当大的。
Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction
Abstract:Aspect Sentiment Triplet Extraction (ASTE) aims to extract triplets from sentences, where each triplet includes an entity, its associated sentiment, and the opinion span explaining the reason for the sentiment. Most existing research addresses this problem in a multi-stage pipeline manner, which neglects the mutual information between such three elements and has the problem of error propagation. In this paper, we propose a Semantic and Syntactic Enhanced aspect Sentiment triplet Extraction model (S3E2) to fully exploit the syntactic and semantic relationships between the triplet elements and jointly extract them. Specifically, we design a Graph-Sequence duel representation and modeling paradigm for the task of ASTE: we represent the semantic and syntactic relationships between word pairs in a sentence by graph and encode it by Graph Neural Networks (GNNs), as well as modeling the original sentence by LSTM to preserve the sequential information. Under this setting, we further apply a more efficient inference strategy for the extraction of triplets. Extensive evaluations on four benchmark datasets show that S3E2 significantly outperforms existing approaches, which proves our S3E2’s superiority and flexibility in an end-to-end fashion.
方面情感Triplet 提取(ASTE)的目的是从句子中提取Triplet ,其中每个Triplet 包括一个实体、与其相关的情感以及解释情感产生原因的意见范围。现有的研究大多采用多级管道的方式来解决这一问题,忽略了这三个要素之间的互信息,存在误差传播的问题。本文提出了一种语义和句法增强的方面情感三元组提取模型(S3E2),充分利用三元组元素之间的语法和语义关系,共同提取三元组元素。具体来说,我们设计一个Graph-Sequence表示和建模范式:我们用图表示句子中词对之间的语义和句法关系,并用图神经网络对其进行编码,并利用LSTM对原始句子进行建模,以保留序列信息。在此背景下,我们进一步采用了一种更有效的推理策略来提取Triplet 。对四个基准数据集的广泛评估表明,S3E2显著优于现有方法,这证明了我们的S3E2在端到端方式上的优越性和灵活性。
Exploiting Position Bias for Robust Aspect Sentiment Classification
GitHub:https://github.com/BD-MF/POS4ASC
Abstract:Aspect sentiment classification (ASC) aims at determining sentiments expressed towards different aspects in a sentence. While state-of-the-art ASC models have achieved remarkable performance, they are recently shown to suffer from the issue of robustness. Particularly in two common scenarios: when domains of test and training data are different (out-of-domain scenario) or test data is adversarially perturbed (adversarial scenario), ASC models may attend to irrelevant words and neglect opinion expressions that truly describe diverse aspects. To tackle the challenge, in this paper, we hypothesize that position bias (i.e., the words closer to a concerning aspect would carry a higher degree of importance) is crucial for building more robust ASC models by reducing the probability of mis-attending. Accordingly, we propose two mechanisms for capturing position bias, namely position-biased weight and position-biased dropout, which can be flexibly injected into existing models to enhance representations for classification. Experiments conducted on out-of-domain and adversarial datasets demonstrate that our proposed approaches largely improve the robustness and effectiveness of current models.
方面情感分类(Aspect sentiment classification, ASC)旨在确定句子中对不同方面表达的情感。虽然最先进的ASC模型取得了卓越的性能,但它们最近被证明存在鲁棒性问题。特别是在两种常见的场景中:当测试数据和训练数据的域不同(out-of-domain scenario)或测试数据受到相反的干扰(adversarial scenario)时,ASC模型可能会关注不相关的词语,忽视真正描述不同方面的意见表达。为了应对这一挑战,本文假设位置偏差(即,与关注方面更接近的词语具有更高的重要性)对于通过减少出错的概率来构建更稳健的ASC模型至关重要。据此,我们提出了两种捕获位置偏差的机制,即 position-biased weight和position-biased dropout,可以灵活地应用到现有模型中,以增强分类表示。在域外和对抗数据集上进行的实验表明,我们提出的方法大大提高了现有模型的鲁棒性和有效性。
Exploring the Efficacy of Automatically Generated Counterfactuals for Sentiment Analysis
Abstract:While state-of-the-art NLP models have been achieving the excellent performance of a wide range of tasks in recent years, important questions are being raised about their robustness and their underlying sensitivity to systematic biases that may exist in their training and test data. Such issues come to be manifest in performance problems when faced with out-of-distribution data in the field. One recent solution has been to use counterfactually augmented datasets in order to reduce any reliance on spurious patterns that may exist in the original data. Producing high-quality augmented data can be costly and time-consuming as it usually needs to involve human feedback and crowdsourcing efforts. In this work, we propose an alternative by describing and evaluating an approach to automatically generating counterfactual data for data augmentation and explanation. A comprehensive evaluation on several different datasets and using a variety of state-of-the-art benchmarks demonstrate how our approach can achieve significant improvements in model performance when compared to models training on the original data and even when compared to models trained with the benefit of human-generated augmented data.
近年来,当最先进的自然语言处理模型在各种任务中取得优异的表现时,人们提出了一些重要的问题,即它们的鲁棒性及其对训练和测试数据中可能存在的系统偏差的潜在敏感性。当在该领域中面对未分配的数据时,这些问题在性能问题中表现出来。最近的一种解决方案是使用反事实增强数据集,以减少对原始数据中可能存在的虚假模式的依赖。产生高质量的增强数据可能是昂贵和耗时的,因为它通常需要人力反馈和众包工作。在这项工作中,我们提出了一个替代方案,通过描述和评估一种方法,自动生成反事实数据的数据扩充和解释。综合评价在不同的数据集和使用各种先进的基准说明我们的方法可以实现显著改善模型性能相比,模型训练的原始数据,甚至相比,模型训练的好处,人为增强数据。
Structured Sentiment Analysis as Dependency Graph Parsing
GitHub:https://github.com/jerbarnes/sentiment_graphs.
Abstract:Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
结构化情感分析试图从文本中提取完整的观点元组,但随着时间的推移,这一任务被细分为越来越小的子任务,例如,目标提取或目标极性分类。我们认为,这种划分产生了反作用,并提出一个新的统一框架来纠正这种情况。将结构化情感问题转换为依赖图解析,其中节点为情感持有者、目标和表达的跨度,弧线为情感持有者、目标和表达之间的关系。我们在4种语言(英语、挪威语、巴斯克语和加泰罗尼亚语)的5个数据集上进行了实验,表明这种方法比最先进的基线有了很大的改进。我们的分析表明,细化情感图与语法依赖信息进一步改善结果。
Bridge-Based Active Domain Adaptation for Aspect Term Extraction
Aspect-Category-Opinion-Sentiment Quadruple Extraction with Implicit Aspects and Opinions
Learning Span-Level Interactions for Aspect Sentiment Triplet Extraction
Towards Generative Aspect-Based Sentiment Analysis
Dynamic and Multi-Channel Graph Convolutional Networks for Aspect-Based Sentiment Analysis
Making Flexible Use of Subtasks: A Multiplex Interaction Network for Unified Aspect-based Sentiment Analysis
CTFN: Hierarchical Learning for Multimodal Sentiment Analysis Using Coupled-Translation Fusion Network
Towards Generative Aspect-Based Sentiment Analysis
Cross-Domain Review Generation for Aspect-Based Sentiment Analysis
Original: https://blog.csdn.net/baidu_28820009/article/details/118607598
Author: 小皮肚鼓嘟嘟
Title: ACL-IJCNLP 2021-Sentiment Analysis相关论文整理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/547985/
转载文章受原作者版权保护。转载请注明原作者出处!