

论文阅读笔记(三):Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering
“知识是基础,汗水是实践,灵感是思想火花,思想火花人人有,不要放弃它。Chance favors the prepared mind.”——袁隆平寄语青年人
文章目录
- 论文阅读笔记(三):Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering
- 关于论文
- 摘要
- 1 面临的问题
- 2 论文提出的模型
- 3 实验
- 4 论文做出的贡献
关于论文
收录于AAAI 2020
作者:Jian Wang1, Junhao Liu2, Wei Bi3,Xiaojiang Liu3, Kejing He1,, Ruifeng Xu4, and Min Yang2,
1South China University of Technology, Guangzhou, China,Shenzhen Institutes of Advanced Technology, 2Chinese Academy of Sciences, Shenzhen, China,3Tencent AI Lab, Shenzhen, China,4Harbin Institute of Technology (Shenzhen), China
摘要
本文研究如何自动生成描述知识图中事实的自然语言文本。考虑到镜头设置较少,论文充分利用了预训练语言模型(PLM)在语言理解和生成方面的强大能力。论文做出了三个主要的技术贡献,即用于弥合KG编码和PLM之间语义差距的表示对齐、用于生成更好的输入表示的基于关系的KG线性化策略和用于学习KG和文本之间对应关系的多任务学习。在三个基准数据集上的大量实验证明了该模型在文本生成任务中的有效性。特别是,论文的模型在完全监督和低资源设置下都优于所有的比较方法。
1 面临的问题
论文面临的主要问题有:如何将常知识融入到开放的对话系统。对于检索相关的事实和生成有意义的响应仅仅依靠单一的不充分的知识数据,特别是这个知识数据很短时,是困难的。
提出的模型:论文提出一个新的知识对话生成模型,有效的融合常知识库中的外部知识成为sequence-to-sequence模型。鉴于KBQA能促进话语理解和事实知识(事实以KB表示)的选择,通过将问题建模和知识匹配能力从KBQA中转移出来,生成信息对话。


; 2 论文提出的模型
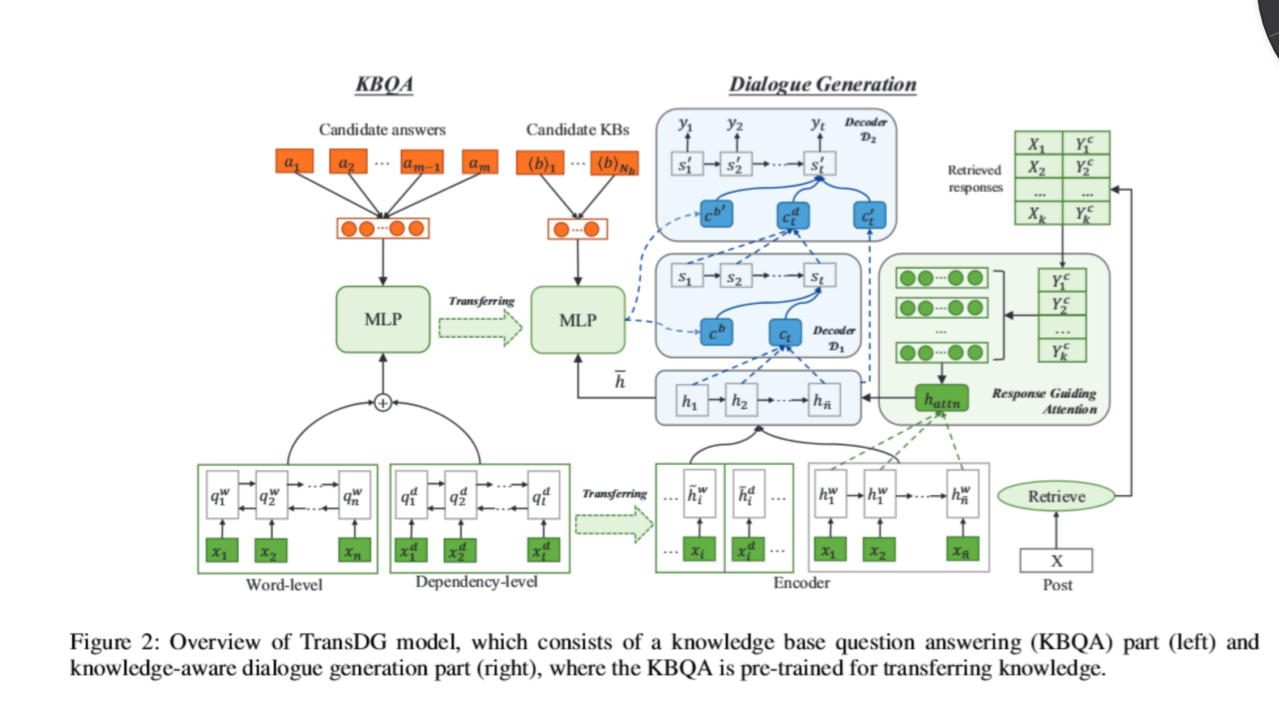
模型分为两部分:一个 KBQA模型和一个 对话生成模型。
KBQA模型:编码和解码阶段都被转换为对话生成。给定一个问题Q通过KBQA任务来从候选的答案A中选择一个恰当的答案。KBQA的一个 普遍思想是将KBs中的问题和事实编码成分布式表示,然后在问题和候选答案表示之间进行语义匹配以得到最终答案。论文利用 单词和单词之间关系的信息来表示问题。对于单词信息,论文将每个单词转换成词向量通过单词镶入矩阵。然后利用BiGRU去获得问题中的隐藏单词。为了捕获问题中单词间的大范围关系,论文使用依赖路径作为额外的表示,将单词和依赖标签与方向连接起来。论文利用Stanford CoreNPL 来获得关系级的代表。然后,论文使用另一个BiGRU网络获得依赖级问题表示。论文将每个事实都划分为单词级和路径级。对于 单词级,论文将每个单词转换成词向量通过单词镶入矩阵,计算出平均作为单词级答案表示。对于 路径级,论文对于每个关系都看为一个整体并且直接转换成向量代表通过一个KB的镶入矩阵。论文通过多层感知器计算问题和候选答案之间的语义相似度得分。在训练中,论文采用hinge损耗来最大化正答案集和负答案集的裕度。
对话生成模型:将知识从知识库质量保证任务中转移出来,促进知识层的对话理解和知识库中的事实选择。对话生成采用 基于序列对序列(Seq2Seq)的方法来生成给定成本的响应。Seq2Seq的编码器逐字读取数据 X,并通过GRU生成每个单词的隐藏表示。为了便于理解一篇文章。论文将KBQA任务中问题表示的能力转化为多层次的语义理解(即词级和依赖级)。形式上,论文使用KBQA任务学习的预先训练的双向GRU作为额外的编码器。为了丰富数据的表达以提高理解能力,论文提出了一种反应引导注意机制,该机制 利用检索到的相似数据的反应来引导模型只关注相关信息。
论文的知识多步解码利用 多步译码策略,将从预先训练的KBQA模型中学习到的知识选择能力进行转移,从而产生应答。第一步解码器通过整合与该 数据相关的外部知识生成一个响应草稿。第二步解码器根据 数据、 上下文知识和 第一步解码器产生的草稿响应生成最终响应。通过这种方法,多步解码器可以捕获文本与响应之间的知识联系,从而产生 更连贯、更详细的响应。第一步解码注意向量模型的提出是为了从预先训练的KBQA模型中迁移选择适当 常识知识的能力。具体地说,对于给定的文章,首先使用查询中的单词从知识库中检索所有相关的三元组。第二步解码可以生成 更合适和更合理的响应相对于帖子, 匹配相关的事实从KB为帖子和草稿响应由 第一步解码器产生。
3 实验
数据集: 论文使用SimpleQuestions数据集来绘制KBQA模型,该模型分别包含75910/10845/21687个实例,用于培训/验证/测试。每个实例都有一个知识三元组作为最佳答案。对话生成采用Reddit单轮对话数据集,其中包含3384185对、10000对验证对和20000对测试对,每个后响应对由一个或多个三元组概念4连接,用作常识KB。
实验评估 : 自动和人工评估指标都被用来衡量模型的性能。对于自动评估,论文采用困惑度和一致性得分作为评估指标,遵循之前的工作。复杂度被广泛地用来量化语言模型,当复杂度越小,模型的性能越好。实体分数用于衡量根据常识知识库生成每个响应的相关实体的能力。实体得分越高,通常表明一般反应越多样化。论文使用人工评价从三个方面来评价对话生成模型:流畅度,知识相关性和正确性。所有的分数都在0到3之间,分数越高,表现越好。具体来说,从测试集中随机选择500个帖子,结果TransDG和基线模型产生了3000个回应,用于人为评估。
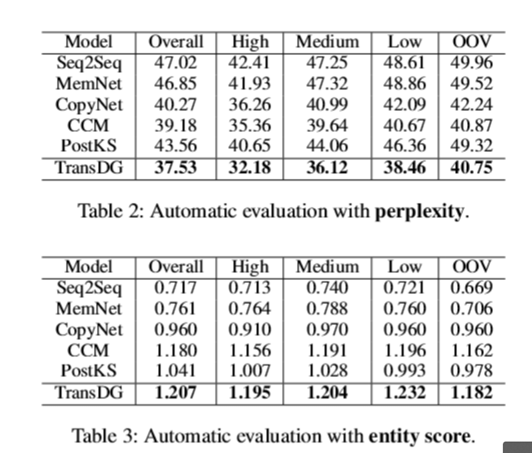
定量结果: 如表2所示,TransDG在所有数据集上的复杂度最低,表明生成的响应更符合语法。表3表明,与标准的Seq2Seq模型相比,该模型在生成有意义的实体词和不同的回答方面取得了更好的效果。特别是,我们的模型在最高实体分数上显著优于所有基线。验证了KBQA任务传递环知识对事实知识选择的有效性。表4所示的BLEU值说明了单词级重叠的比较结果。在大多数情况下, TransDG倾向于产生比基线更类似于最佳响应。这可能是因为我们的模型利用检索到的候选响应来提供指导。此外,我们还观察到,CopyNet在BLEU评分方面也表现良好,因为它将复制机制引入到解码过程中,可以从输入数据和KB中复制单词或子序列。
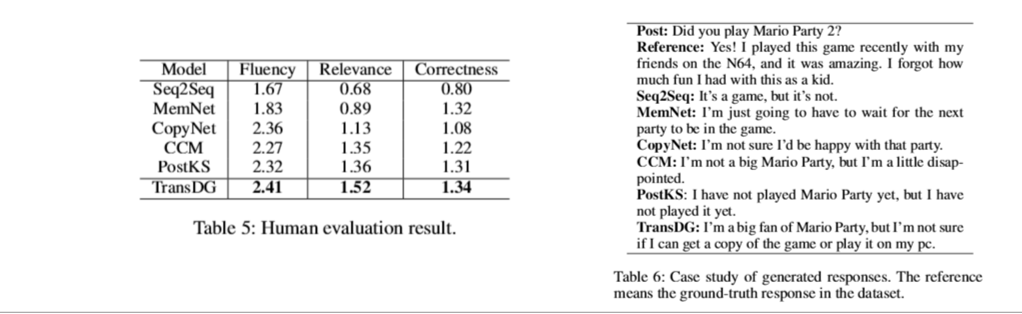
误差分析:为了更好地理解TransDG的局限性,我们还对TransDG的错误进行了分析。我们随机选择100个由transdg产生的反应,获得较低的人类评价分数。我们揭示了人类评价分数低的几个原因,可分为以下几类。
不合逻辑(36%):最重要的错误类别是不合逻辑的,包括与新发布的帖子相矛盾或冲突的响应。例如,回答”我不确定他是阿戈德的球员,特别是他是一个好球员”的得分为0,因为它缺乏逻辑上的连续性。这种错误很难用当前技术来处理,尤其是在构建端到端模型时
杂项(32%):第二个最常见的错误类别是杂项,包括由多义词引起的信息量较少或不合理的回答。例如,有一个帖子”你生活在岩石下?那句话比泥土还古老”,得到的回答是”我不喜欢摇滚乐”
不相关(20%):第三类错误包括流利但与文章不相关的回答,或者过于笼统而无法正确回答文章,当模型没有包含适当的知识时就会发生。因为在立场上,一般的回答是”我不知道,我很高兴我能建立一个好的!”是为寻求帮助而生成的帖子”这里有你在任何地方使用的设计教程吗?或者有什么能帮我建的?”
不合语法(12%):另一类错误包括语法错误的回答(例如,”它不是单一颜色”)。这可能是因为模型未能阻止重复单词的生成。
; 4 论文做出的贡献
论文对KBQA模型进行了预训练,该模型由一个 用于表示问题和候选答案编码层和一个 用于从知识库中选择最合适的答案的知识选择层组成。
(1)论文使用选通递归单元(GRU)对输入接口进行编码,并将从KBQA模型中学习到的问题表示层作为对话编码器进行扩充。
(2)论文利用多步译码策略,将知识选择层从KBQA模型中学习出来,整合常识知识,生成信息响应。
第一步,译码器通过 相关接口的事实(实体)来生成初步的响应。
第二步,译码器通过参考第一步译码器学习的 上下文知识来生成最终响应,并提高所生成响应的整体正确性。
写在最后:
本人研究方向和兴趣点大致为自然语言处理、医疗问答系统、Rasa框架,刚开始学习研究,本专题翻译一些顶会期刊,希望能坚持做下去,欢迎有兴趣或者研究方向差不多的朋友一起交流讨论,需要论文原文可私信。
Original: https://blog.csdn.net/weixin_43576804/article/details/119333221
Author: -海绵海绵大海绵-
Title: 论文阅读笔记(三):Improving Knowledge-aware Dialogue Generation via Knowledge Base Question Answering
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/595120/
转载文章受原作者版权保护。转载请注明原作者出处!