

一、慢SQL优化思路
- 慢查询日志记录慢SQL
- explain查询SQL的执行计划
- profile分析执行耗时
- Optimizer Trace分析详情
1、慢查询日志记录慢SQL
show variables like 'slow_query_log%';
show variables like 'long_query_time';
查看下慢查询日志配置,我们可以使用show variables like ‘slow_query_log%’命令。


如何启用慢查询日志呢?
临时开启:
set global slow_query_log='ON';
永久开启:
/etc/my.cnf中追加配置:
放到[mysqld]下:
slow_query_log=1
slow_query_log_file=/var/lib/mysql/localhost-slow.log
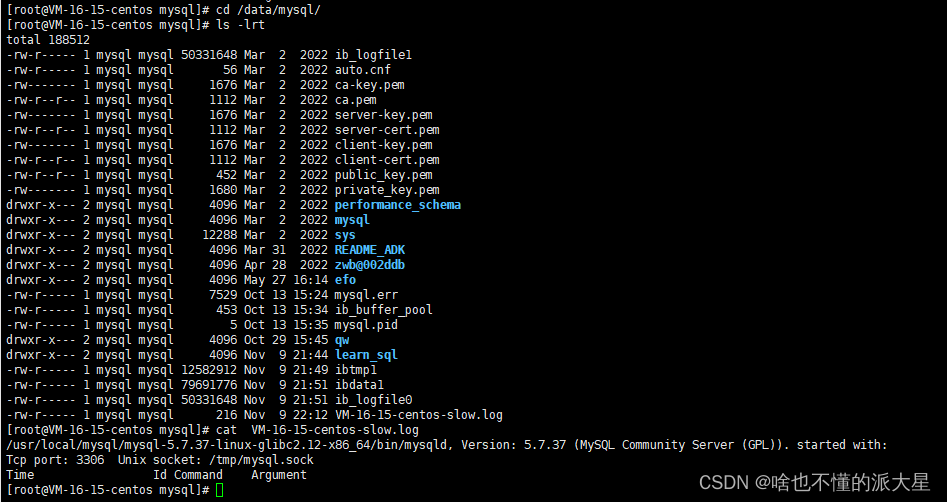
可以使用show variables like ‘long_query_time’命令,查看超过多少时间才记录到慢查询日志。

通过慢查日志定位执行效率较低的SQL语句,重点关注分析。
2、explain查看分析SQL的执行计划
一般来说,我们需要重点关注type、rows、filtered、extra、key。

type
type表示连接类型,查看索引执行情况的一个重要指标。
以下性能从好到坏依次:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:这种类型要求数据库表中只有一条数据,是const类型的一个特例,一般情况下是不会出现的。
const:通过一次索引就能找到数据,一般用于 主键或唯一索引作为条件,这类扫描效率极高,速度非常快。
eq_ref:常用于 主键或唯一索引扫描,一般指使用主键的关联查询
ref : 常用于 非主键和唯一索引扫描。
ref_or_null:这种连接类型类似于ref,区别在于MySQL会额外搜索包含NULL值的行
index_merge:使用了索引合并优化方法,查询使用了两个以上的索引。
unique_subquery:类似于eq_ref,条件用了in子查询
index_subquery:区别于unique_subquery,用于非唯一索引,可以返回重复值。
range:常用于范围查询,比如:between … and ,大于小于或 In 等操作
index:全索引扫描 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小;
ALL:全表扫描
实际sql优化中,最后达到ref或range级别。
rows
该列表示MySQL估算要找到我们所需的记录, 需要读取的行数。 对于InnoDB表,此数字是估计值,并非一定是个准确值。
filtered
该列是一个百分比的值, 表里符合条件的记录数的百分比。简单点说, 这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
extra
该字段包含有关MySQL如何解析查询的其他信息,它一般会出现这几个值:
Using filesort:表示按 文件排序,一般是在指定的排序和索引排序不一致的情况才会出现。一般见于order by语句
Using index :表示是否用了覆盖索引。
Using temporary: 表示是否使用了 临时表,性能特别差,需要重点优化。一般多见于group by语句,或者union语句。
Using where : 表示使用了where条件过滤. WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。 需要回表查询
Using index condition:MySQL5.6之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据。
key
该列表示实际用到的索引名称。一般配合 possible_keys列一起看。
; 3、profile分析执行耗时
explain只是看到SQL的预估执行计划,如果要了解SQL真正的执行线程状态及消耗的时间,需要使用profiling。开启profiling参数后,后续执行的SQL语句都会记录其资源开销,包括IO,上下文切换,CPU,内存等等,我们可以根据这些开销进一步分析当前慢SQL的瓶颈再进一步进行优化。
profiling默认是关闭,我们可以使用show variables like ‘%profil%’查看是否开启。

可以使用set profiling=ON开启。开启后,可以运行几条SQL,然后使用show profiles查看一下。
set profiling=ON

show profiles会显示最近发给服务器的多条语句,条数由变量profiling_history_size定义,默认是15。
如果我们需要看单独某条SQL的分析,可以show profile查看最近一条SQL的分析,也可以使用show profile for query id(其中id就是show profiles中的QUERY_ID)查看具体一条的SQL语句分析。
除了查看profile ,还可以查看cpu和io。

4、Optimizer Trace分析详情
profile只能查看到SQL的执行耗时,但是无法看到SQL真正执行的过程信息,即不知道MySQL优化器是如何选择执行计划。这时候,我们可以使用Optimizer Trace,它可以跟踪执行语句的解析优化执行的全过程。
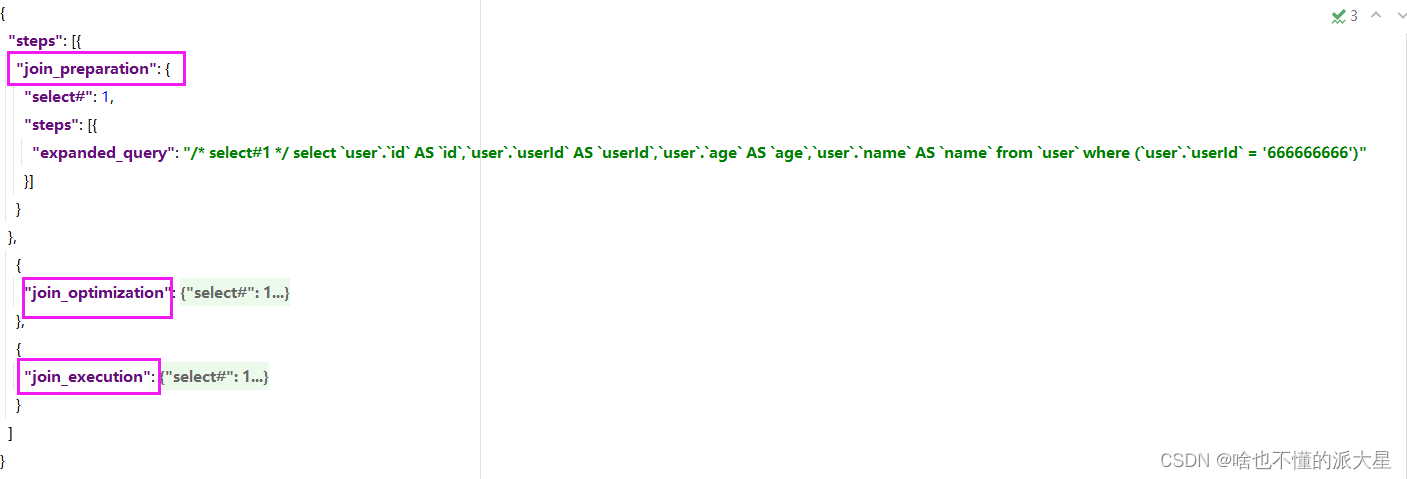
我们可以使用set optimizer_trace=”enabled=on”打开开关,接着执行要跟踪的SQL,最后执行select * from information_schema.optimizer_trace跟踪,如下:

大家可以查看分析其执行树,会包括三个阶段:
join_preparation:准备阶段
join_optimization:分析阶段
join_execution:执行阶段
查看json串
; 5、 确定SQL问题并采用相应的方案
最后确认问题,就采取对应的措施。
多数慢SQL都跟索引有关,比如不加索引,索引不生效、不合理等,这时候,我们可以优化索引。
优化SQL语句,load额外的字段,比如一些in元素过多问题(分批),深分页问题(基于上一次数据过滤等),进行时间分段查询。
SQl没办法很好优化,可以改用ES的方式,或者数仓。
如果单表数据量过大导致慢查询,则可以考虑分库分表。
如果数据库在刷脏页导致慢查询,考虑是否可以优化一些参数,跟DBA讨论优化方案。
如果存量数据量太大,考虑是否可以让部分数据归档。
二、慢查询案例
1、隐式转换
字段为字符串类型。

建立了B+Tree索引。

使用数值格式,没有走索引。

使用正确的格式,正常走索引。

字段为字串类型,是B+树的普通索引,如果查询条件传了一个数字过去,就会导致索引失效。
为什么第一条语句未加单引号就不走索引了呢?这是因为不加单引号时,是字符串跟数字的比较,它们 类型不匹配,MySQL会做隐式的类型转换,把它们转换为浮点数再做比较。隐式的类型转换,索引会失效。
; 2、最左匹配原则
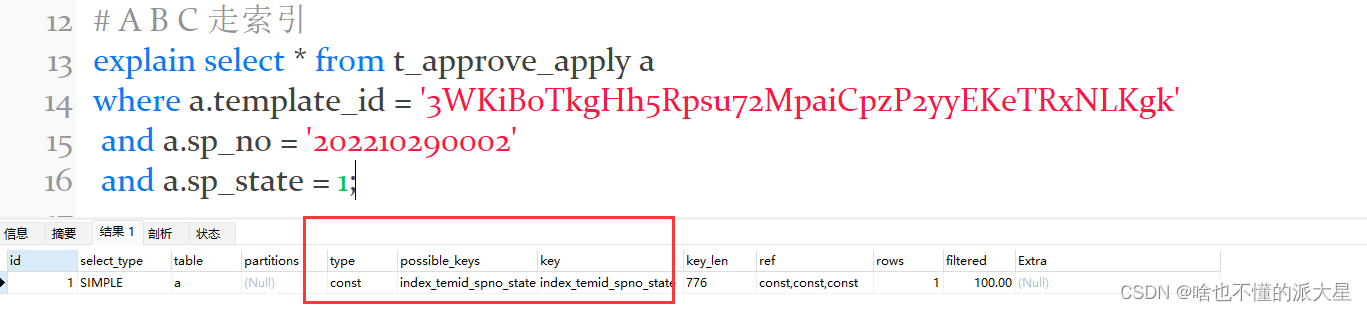
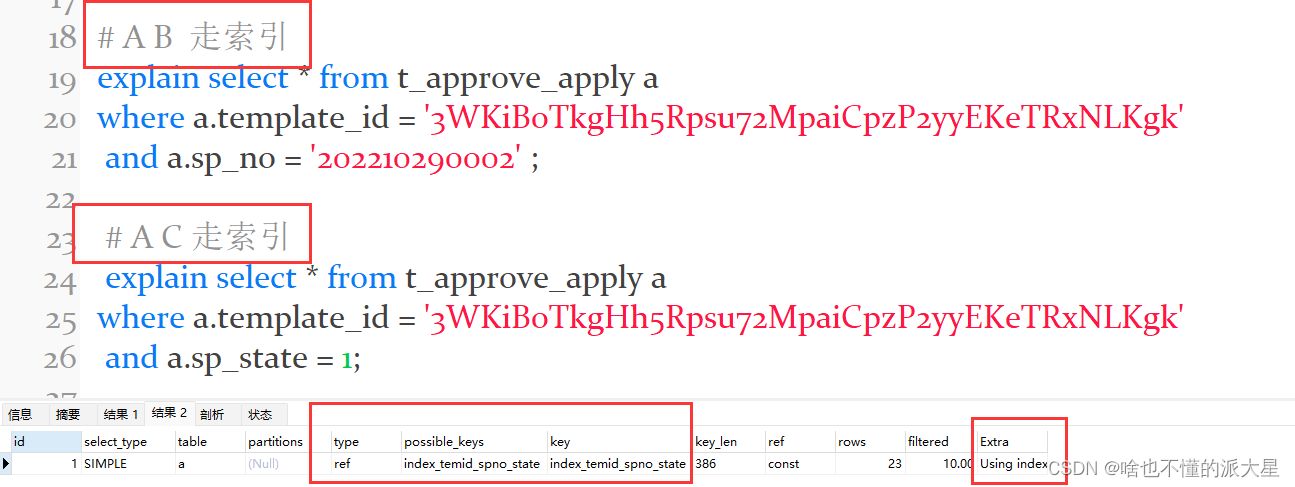
MySQl建立联合索引时,会遵循最左前缀匹配的原则,即最左优先。如果你建立一个(a,b,c)的联合索引,相当于建立了(A)、(A,B)、(A,C)、(A,B,C) 四个索引。
建立联合索引(A、B、C)。


注意
B/C不是中的第一个列,不满足最左匹配原则,所以索引不生效。
在联合索引中,只有查询条件满足最左匹配原则时,索引才正常生效。


3、深分页问题
limit深分页问题,会导致慢查询。
batch_code字段建立索引。

select a.id,a.sp_no,a.sp_name,a.sp_result,a.sp_status from t_approve_record a
where a.batch_code = '20221029133216' limit 100000,10;
这个SQL的执行流程:
通过普通二级索引树idx_batch_code,过滤batch_code条件,找到满足条件的主键id。
通过主键id,回到id主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)。
扫描满足条件的100010行,然后扔掉前100000行,返回。
如何优化深分页问题?
我们可以通过减少回表次数来优化。一般有 标签记录法和延迟关联法。
标签记录法
就是标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描。就好像看书一样,上次看到哪里了,你就折叠一下或者夹个书签,下次来看的时候,直接就翻到啦。
假设上一次记录到100000,则SQL可以修改为:
select a.id,a.sp_no,a.sp_name,a.sp_result,a.sp_status from t_approve_record a
where a.id > 100000 limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了id索引。
但是这种方式有局限性:需要一种类似连续自增的字段。
延迟关联法
延迟关联法,就是把条件转移到主键索引树,然后减少回表。
select a.id,a.sp_no,a.sp_name,a.sp_result,a.sp_status from t_approve_record a
inner join
(select a.id from t_approve_record a WHERE a.batch_code = '20221029133216' limit 100000, 10) b
on a.id= b.id;
优化思路就是,先通过idx_batch_code二级索引树查询到满足条件的主键ID,再与原表通过主键ID内连接,这样后面直接走了主键索引了,同时也减少了回表。
explain看一下:

4、in元素过多
如果使用了in,即使后面的条件加了索引,还是要注意in后面的元素不要过多哈。in元素一般建议不要超过200个,如果超过了,建议分组,每次200一组进行哈。
oracle数据库有的版本还有数量限制,只能用exist替换或者临时表、in() or in()等方案。
Oracle 9i 中个数不能超过256,Oracle 10g个数不能超过1000个。
in查询为什么慢呢?
这是因为in查询在MySQL底层是通过 n*m的方式去搜索,类似 union。
in查询在进行cost代价计算时(代价 = 元组数 * > IO平均值),是通过将in包含的数值,一条条去查询获取元组数的,因此这个计算过程会比较的慢,所以MySQL设置了个 临界值(eq_range_index_dive_limit),5.6之后超过这个临界值后该列的cost就不参与计算了。因此会导致执行计划选择不准确。默认是200,即in条件超过了200个数据,会导致in的代价计算存在问题,可能会导致Mysql选择的索引不准确。
5、order by 走文件排序
如果order by 使用到文件排序,则会可能会产生慢查询。
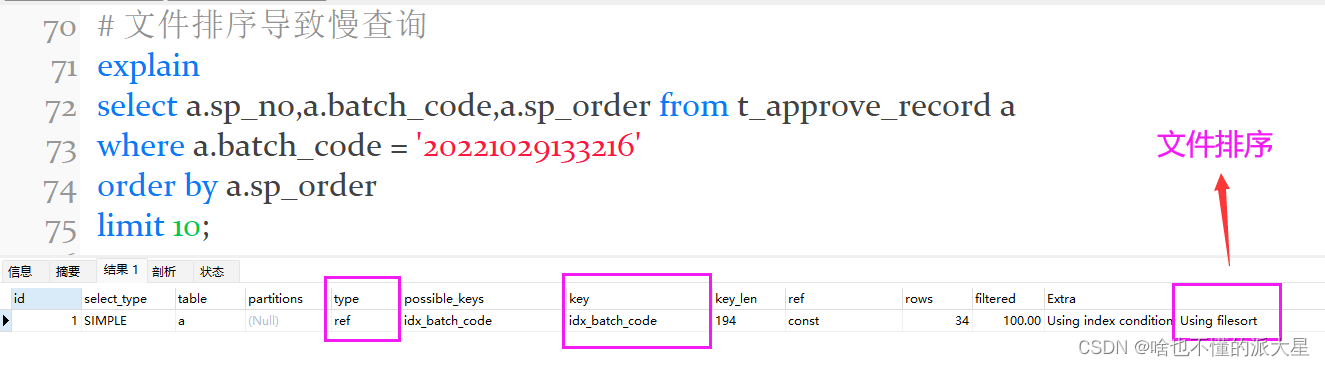
order by文件排序效率为什么较低?

order by排序,分为全字段排序和rowid排序。
它是拿max_length_for_sort_data和结果行数据长度对比,如果结果行数据长度超过max_length_for_sort_data这个值,就会走rowid排序,相反,则走全字段排序。
; 5.1 rowid排序
rowid排序,一般需要回表去找满足条件的数据,所以效率会慢一点。以下这个SQL,使用rowid排序,执行过程是这样:
explain
select a.sp_no,a.batch_code,a.sp_order from t_approve_record a
where a.batch_code = '20221029133216'
order by a.sp_order
limit 10;
- MySQL为对应的线程初始化sort_buffer,放入需要排序的sp_order字段,以及主键id;
- 从索引树idx_batch_code, 找到第一个满足batch_code=’20221029133216’条件的主键id,假设id为X;
- 到主键id索引树拿到id=X的这一行数据, 取sp_order和主键id的值,存到sort_buffer;
- 从索引树idx_batch_code拿到下一个记录的主键id,假设id=Y;
- 重复步骤 3、4 直到batch_code的值不等于’20221029133216’为止;
- 前面5步已经查找到了所有batch_code=’20221029133216’的数据,在sort_buffer中,将所有数据根据sp_order进行排序;遍历排序结果,取前10行,并按照id的值回到原表中,取出sp_no,batch_code,sp_order几个字段返回给客户端。
5.2 全字段排序
同样的SQL,如果是走全字段排序是这样的:
- MySQL 为对应的线程初始化sort_buffer,放入需要查询的sp_no,batch_code,sp_order字段;
- 从索引树idx_batch_code, 找到第一个满足 batch_code=’20221029133216’条件的主键 id,假设找到id=X;
- 到主键id索引树拿到id=X的这一行数据, 取sp_no,batch_code,sp_order三个字段的值,存到sort_buffer;
- 从索引树idx_batch_code拿到下一个记录的主键id,假设id=Y;
- 重复步骤 3、4 直到batch_code的值不等于’20221029133216’为止;
- 前面5步已经查找到了所有batch_code=’20221029133216’的数据,在sort_buffer中,将所有数据根据sp_order进行排序;
- 按照排序结果取前10行返回给客户端。
sort_buffer的大小是由一个参数控制的: sort_buffer_size。
如果要排序的数据小于sort_buffer_size,排序在sort_buffer内存中完成
如果要排序的数据大于sort_buffer_size,则借助磁盘文件来进行排序。
借助磁盘文件排序的话,效率就更慢一点。因为先把数据放入sort_buffer,当快要满时。会排一下序,然后把sort_buffer中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件。
5.3 如何优化order by的文件排序?
因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过 建立索引来优化order by语句。
我们还可以通过 调整max_length_for_sort_data、sort_buffer_size等参数优化;
6、索引字段上使用(!= 或者 < >),索引可能失效
虽然age加了索引,但是使用了 != 或者<>,not in 这些时,索引如同虚设。

其实这个也是跟mySQL优化器有关,如果优化器觉得即使走了索引,还是需要扫描很多很多行的哈,它觉得不划算,不如直接不走索引。平时我们用!= 或者< >,not in的时候注意下。
; 7、索引字段上使用is null, is not null,索引可能失效
is null 不走索引。


and或者or连接起来,索引照样失效。

很多时候,也是因为数据量问题,导致了MySQL优化器放弃走索引。同时,平时我们用explain分析SQL的时候,如果type=range,要注意一下哈,因为这个可能因为数据量问题,导致索引无效。
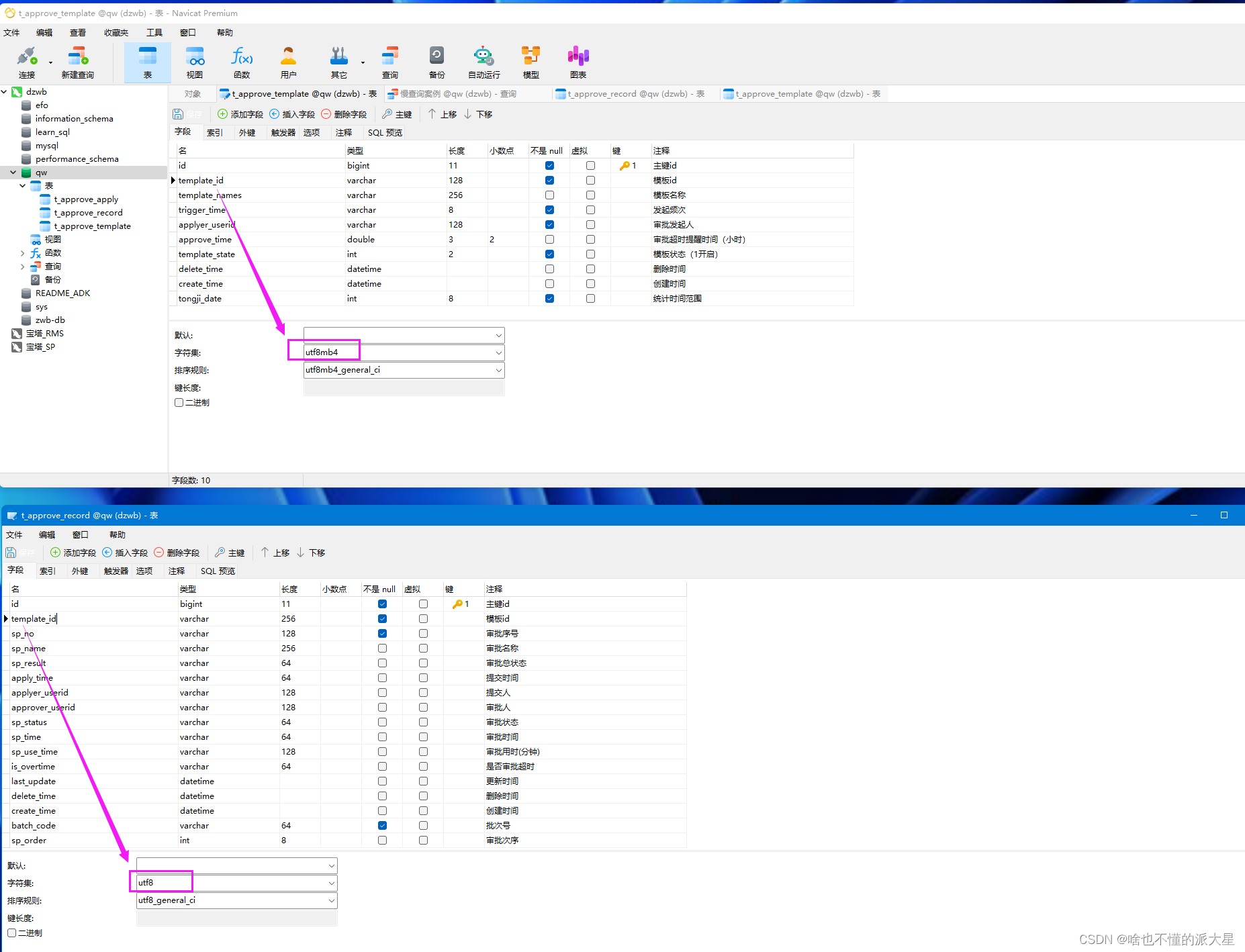
8、左右连接,关联的字段的编码格式不一样
2张表建立索引。
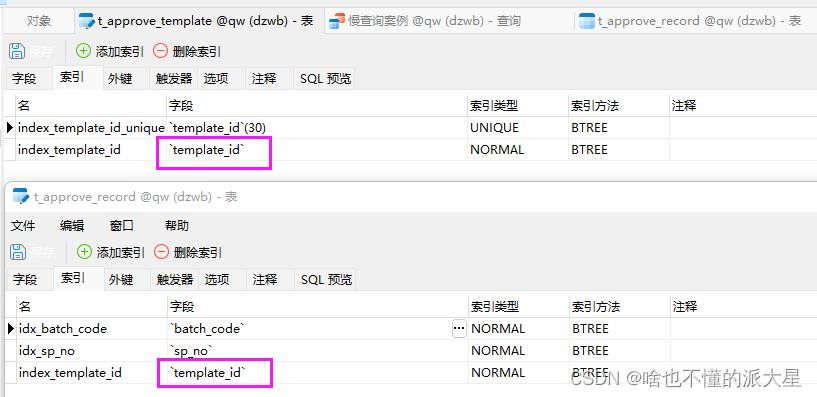
表1的 字段是utf8编码,表2的字段是utf8mb4编码。
连接查询,走了全表扫描

换回相同的编码后

如果把它们的template_id字段改为编码一致,相同的SQL,还是会走索引。

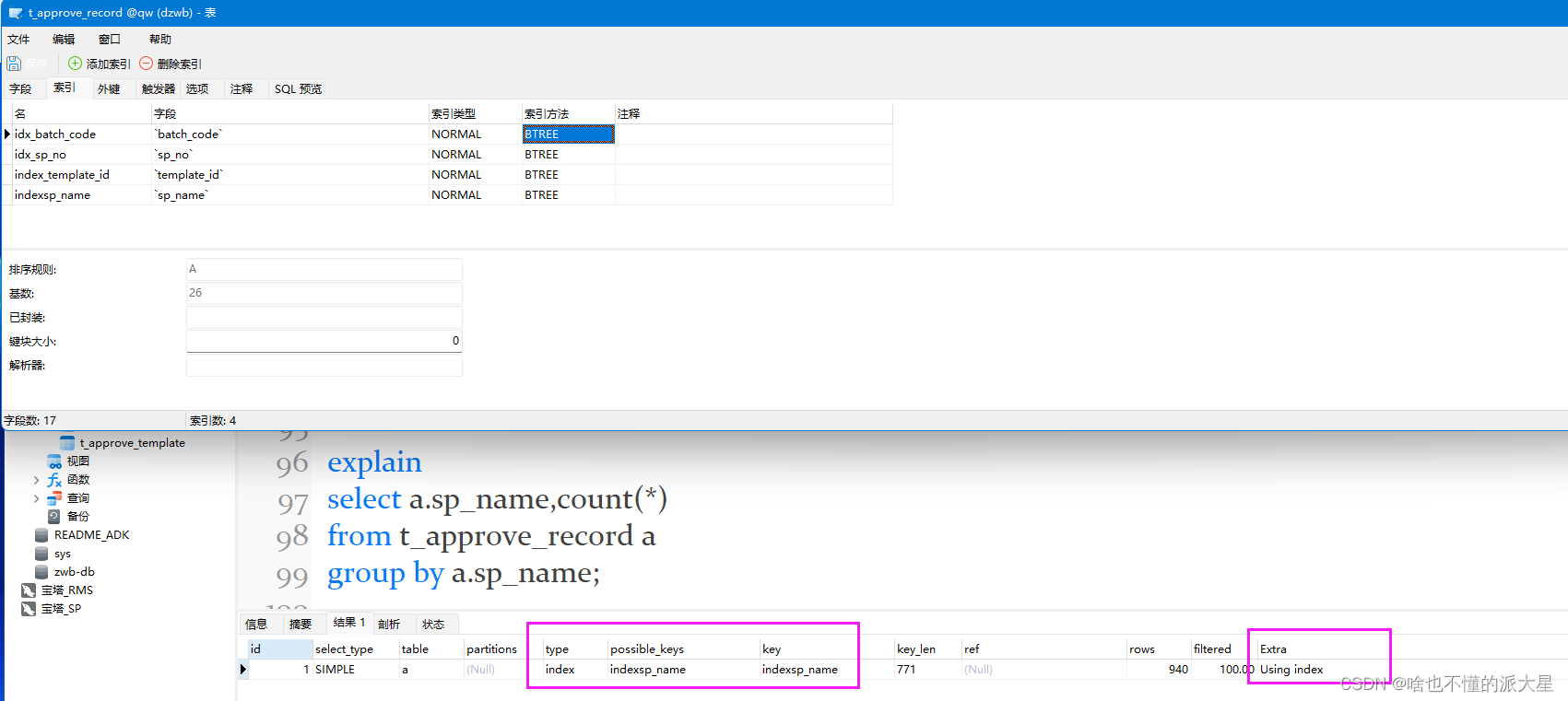
; 9、group by使用临时表
sp_name字段未建索引。

Extra 这个字段的Using temporary表示在执行分组的时候使用了 临时表。
Extra 这个字段的Using filesort表示使用了 文件排序
原因与group by的执行过程有关。
可以有这些优化方案:
group by 后面的字段加索引。
order by null 不用排序。
尽量只使用 内存临时表。
使用SQL_BIG_RESULT。
建立索引后的执行计划:
10、delete + in子查询不走索引
查看执行计划,发现不走索引。

把delete换成select,就会走索引。

查看最终执行的sql:

select qw.t_approve_record.id AS id,qw.t_approve_record.template_id AS template_id,qw.t_approve_record.sp_no AS sp_no,qw.t_approve_record.sp_name AS sp_name,qw.t_approve_record.sp_result AS sp_result,qw.t_approve_record.apply_time AS apply_time,qw.t_approve_record.applyer_userid AS applyer_userid,qw.t_approve_record.approver_userid AS approver_userid,qw.t_approve_record.sp_status AS sp_status,qw.t_approve_record.sp_time AS sp_time,qw.t_approve_record.sp_use_time AS sp_use_time,qw.t_approve_record.is_overtime AS is_overtime,qw.t_approve_record.last_update AS last_update,qw.t_approve_record.delete_time AS delete_time,qw.t_approve_record.create_time AS create_time,qw.t_approve_record.batch_code AS batch_code,qw.t_approve_record.sp_order AS sp_order
from qw.t_approve_template
join qw.t_approve_record
where (qw.t_approve_record.template_id = qw.t_approve_template.template_id)
可以发现,实际执行的时候,MySQL对select in子查询做了优化,把子查询改成join的方式,所以可以走索引。
但是很遗憾,对于delete in子查询,MySQL却没有对它做这个优化。
11、其它索引失效场景,如InnoDB下like ‘%xxx’索引失效


索引失效

Original: https://blog.csdn.net/zwb_dzw/article/details/127778909
Author: 啥也不懂的派大星
Title: MySql学习之慢SQL优化和慢SQL案例
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/661159/
转载文章受原作者版权保护。转载请注明原作者出处!