

一、视频数据结果
今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至:
https://www.cnblogs.com/mashukui/p/16220254.html
这次呢,用python爬虫爬了李子柒B站的所有视频数据。
先看下,最终爬取到的视频数据:
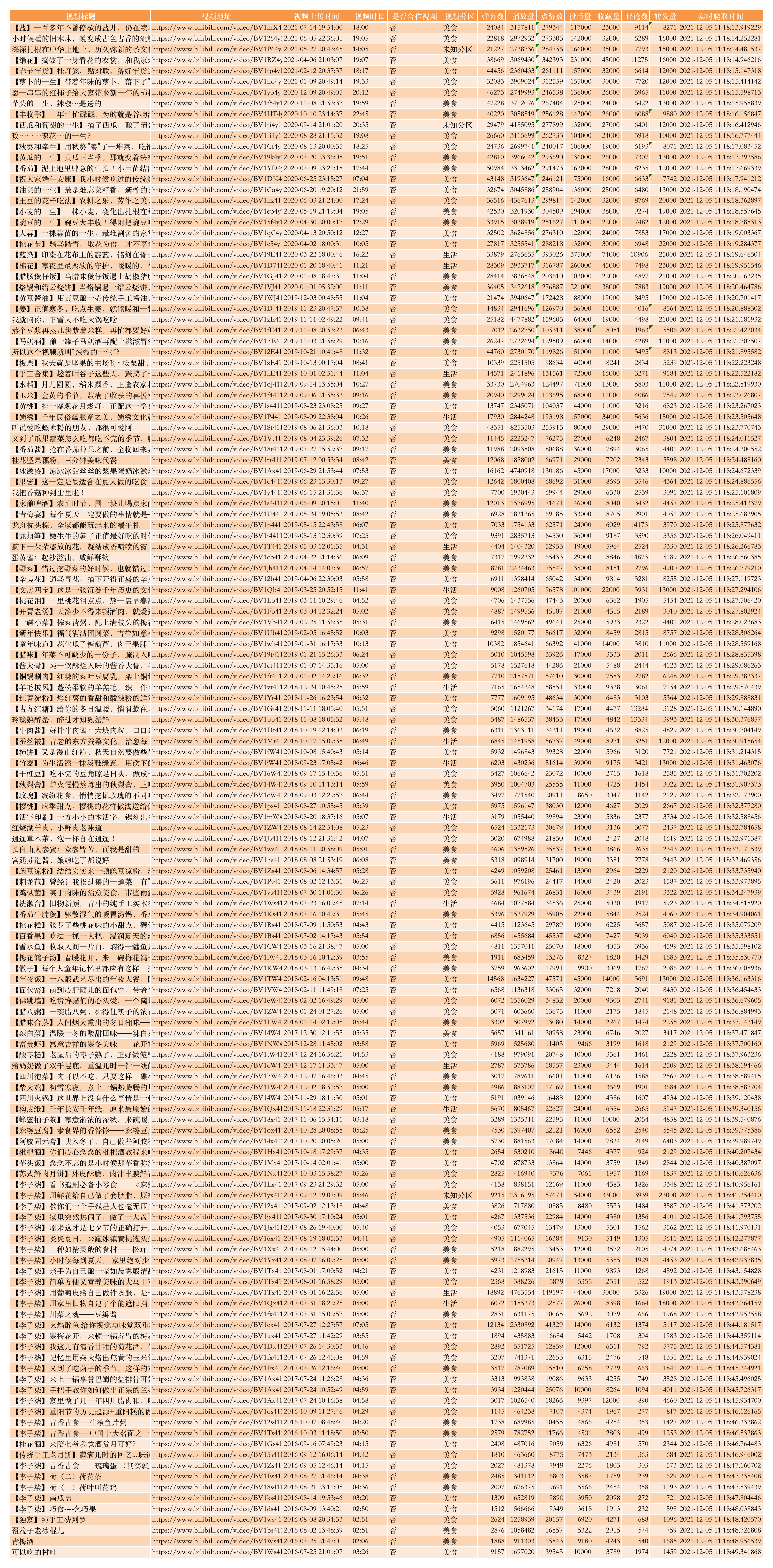

一共是142条视频数据(截至目前,李子柒在B站一共上传过142个视频)
每条数据包含的字段是:
视频标题,视频地址,视频上传时间,视频时长,是否合作视频,视频分区,弹幕数,播放量,点赞数,投币量,收藏量,评论数,转发量,实时爬取时间
基本上涵盖了视频的所有属性字段。
二、部分核心代码
这里,我分享下部分核心代码:
url_list = [] # 视频地址
title_list = [] # 视频标题
author_list = [] # UP主昵称
mid_list = [] # UP主UID
create_time_list = [] # 上传时间
play_count_list = [] # 播放数
length_list = [] # 视频时长
comment_count_list = [] # 评论数
is_union_list = [] # 是否合作视频
type_list = [] # 分区
danmu_count_list = [] # 弹幕数
for i in range(1, 10): # 前10页
url = 'https://api.bilibili.com/x/space/arc/search?mid=19577966&ps=30&tid=0&pn={}&keyword=&order=pubdate&jsonp=jsonp'.format(
str(i))
r = requests.get(url, headers=headers)
print(r.status_code) # 响应码200
json_data = r.json()
pprint(json_data)
video_list = json_data['data']['list']['vlist']
pprint(video_list)
for i in video_list:
bvid = i['bvid']
url = 'https://www.bilibili.com/video/' + bvid
url_list.append(url)
title = i['title']
title_list.append(title)
author = i['author']
author_list.append(author)
mid = i['mid']
mid_list.append(mid)
create_time = i['created']
create_time = trans_date(v_timestamp=create_time)
create_time_list.append(create_time)
play_count = i['play']
play_count_list.append(play_count)
length = i['length']
length_list.append(length)
comment = i['comment']
comment_count_list.append(comment)
is_union = '是' if i['is_union_video'] == 1 else '否'
is_union_list.append(is_union)
type_name = get_video_type(v_num=i['typeid'])
type_list.append(type_name)
danmu_count = i['video_review']
danmu_count_list.append(danmu_count)
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
其中,把url中的mid换成B站任意up主的对应mid,都可以进行爬取!!
三、同步讲解视频
代码逐行讲解:
https://www.zhihu.com/zvideo/1451862342237229056
四、获取python源码文件
爱学习的小伙伴,想获取完整python代码文件,关注我的微信公众号”老男孩的平凡之路”,后台回复关键字”李子柒B站爬虫”,即可获取完整python源码及数据!
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索”马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。
Original: https://www.cnblogs.com/mashukui/p/16221258.html
Author: 马哥python说
Title: 【Python爬虫案例】用Python爬取李子柒B站视频数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/591432/
转载文章受原作者版权保护。转载请注明原作者出处!