

DDD分为战略部分跟战术部分,相信大家都认同DDD的核心在战略而非战术。而战略方面的核心我认为在业务建模,领域划分、统一语言等都在为业务建模服务。
为什么业务建模重要?
以前的开发流程有什么问题?
先说结论,开发人员交付的程序对业务方,产品人员,测试人员来说就是一个黑盒子。除了开发人员自己,没人知道盒子里有什么。当新的需求加入来,需求方,产品人员,甚至测试人员都认为可行,开发人员却给出相反结论。
回顾一下以前的开发流程 大致可以归结为以下步骤:(开发跟测试人员最好能参与需求分析)
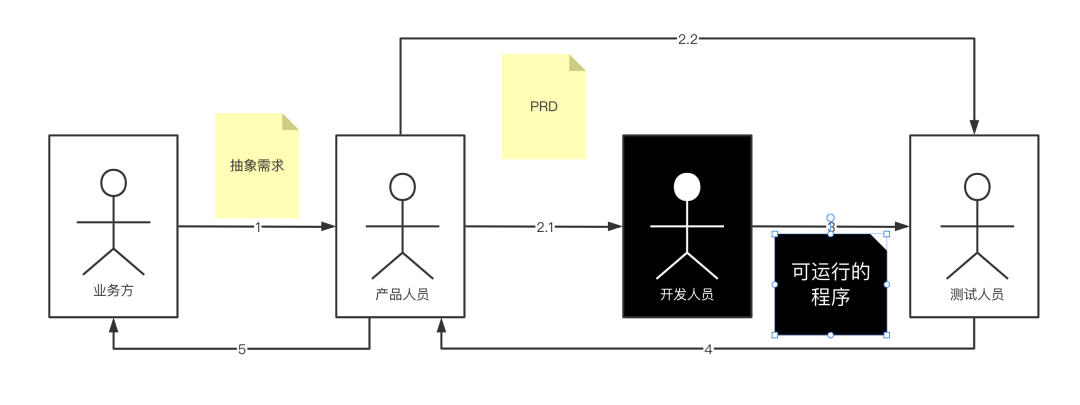

1.业务方描述抽象需求
2.产品将需求转化为可落地的产品(需求具像化,PRD)
3.开发人员根据产品的PRD开发
4.测试人员根据产品的PRD测试
5.产品人员验收
6.业务方验收
依照经验来说,在整个流程中开发人员是耗时最长的。与此同时测试人员可能在编写测试用例,而业务方跟产品人员在这段时间内是阻塞的。最终的程序质量靠测试人员来保障。
开发人员完成开发后:
测试人员关注测试用例是否通过。
产品人员确认展现出来的功能是否符合当初的PRD。
业务方确认程序是否符合预期。
举一个我开发项目的例子
一个审批系统
产品的PRD描述了一个三层模型:
流程实例,流程节点,审批任务。流程实例启动创建审批节点,审批节点触发审批任务,任务完成创建下一个节点…。
我是这样做的:
流程实例,审批任务。流程实例启动创建(一批)审批任务,任务被完成后创建后续任务或者流程结束。至于流程节点不存在,不是问题,从任务中提取信息虚拟一个出来。
第一版交付完成。
产品在第一版后追加需求
流程节点可以被非审批人评论。
我….
当时业务方,产品,测试都认为这是一个合理的需求。只有我一脸懵,因为我的程序中没有流程节点这个东西,需求又不能拒绝,无奈给出一个远超他们预期的开发计划。
gap就出在 他们认为流程节点是一个确实存在的东西,而只有我知道这节点是虚拟的,没有标识,不能跟其他信息做关联。
业务建模怎么解决这个黑盒子问题?
DDD引入了业务专家这个角色(在我看来就是业务方,产品)。
1.假设业务专家听不懂 什么叫类,什么是方法,设计模式,他只知道他的业务,两方人马完全不在同一频道,这个时候就需要”明确上下文”,”统一语言”了。(不仅仅开发人员与业务专家达成了共识,也包含整个开发团队达成共识)
2.业务建模,用例分析法、事件风暴、四色建模等看看开始整上。最终达到划分领域,识别聚合的目的。
3.业务建模落地。开发人员开发过程中,应遵守已经建立的业务模型来编写代码。
至此终于实现了,业务专家可通过业务模型窥探到开发人员的代码实现。统一语言、业务模型在业务专家跟开发人员中间充当了沟通的桥梁。(有点像适配器)
当追加新的需求时,业务专家能合理评估需求的可行性。
让非开发人员参与到开发中
统一语言,业务建模,模型充血(OOP)。这一系列手段都是为了实现让非开发人员参与到开发中这一最终目的。与其说DDD是一种架构,不如认为他是指导开发的方法论。
好比盖房子,以前只要把房子交付了能住人就行。现在业务专家是设计师,业务模型是设计图,代码则是建材,程序员就是工地搬砖的,盖起来的房子得跟设计师给出的设计图一样。
业务模型落地的问题?
这是一个让我纠结的问题。我感觉还没有找到符合我期望的答案。
业务模型具现到代码中,就是一个个聚合。这些聚合符合OOP的思想,通过聚合根,实体,值对象的组合来表达业务模型。
以网络上常见的demo为例:
//订单明细实体
public class OrderItemEntity {
//id
private Long id;
//商品(值对象)
private Product product;
//数量(值对象)
private Count count;
// item总价(值对象)
private ItemAmount itemAmt;
public void modifyCount(Count count) {
this.count = count;
this.itemAmt = new ItemAmt(this.product.getPrice()*count.get());
}
}
//订单聚合根
public class OrderAggregate {
//聚合唯一标识
private Long id;
//订单号(值对象)
private OrderNo orderNo;
//总价 (值对象)
private Amount amt;
//订单明细
private List items;
public void modifyItemCount(Product product,Count count) {
//找到商品
this.items.stream().filter(product::equals).findAny().get();
//修改数量 返回Item总价
item.modifyCount(count);
ItemAmount itemAmt = item.getItemAmt();
//修改订单总价
this.amt = new Amount(this.amt.get()+itemAmt.get());
}
}
//要订单明细中 名称叫电脑的商品数量修改100
Product product = new Product("电脑");
Count count = new Count(100);
Amount amt = orderAggregate.modifyItemCount(product, count);
理论与现实的矛盾
从代码上可以看出这一段1:n关系的代码完全基于内存,非常的OOP,也就是说,我们在获得orderAggregate时,已经加载整个聚合(包括List
假设OrderItemEntity的量级是十万级,百万级,明显这段代码是不能上线的,理论与现实出现了矛盾。
咨询了很多大佬+个人理解(以下方法为我自己命名)
模型提升法(无限套娃)
大佬建议:
“如果真有这种场景,就需要调整聚合,比如:将OrderItem提升为Order, Order提升为BatchOrder”
思路:
创建BatchOrderAggregate,BatchOrderAggregate持有OrderEntity。
创建OrderAggregate持有部分OrderItemEntity,通过分治的方式化整为零。
思考:
整体上符合业务模型,而且没有上限,即如果BatchOrderAggregate不能解决问题,那就祭出BatchBatchOrderAggregate。
BatchBatchOrderAggregate持有BatchOrderEntity。
BatchOrderAggregate持有OrderEntity。
OrderAggregate持有部分OrderItemEntity。
持有仓储法
(隐藏了数据库查询,但是直觉上有点反模式)
大佬建议:
“聚合中构建索引,需要时再加载置换”
思路:
聚合根持有存储引用,需要时加载到内存中。
可以加入一层接口隔离。
public class OrderAggregate {
//聚合唯一标识
private Long id;
//订单号(值对象)
private OrderNo orderNo;
//总价 (值对象)
private Amount amt;
//关联对象接口(接口实现在基础服务层,在实现中操作数据库)
private OrderItemRel orderItemRel;
public void modifyItemCount(Product product,Count count) {
List items = orderItemRel.find(product);
//找到商品
OrderItemEntity item = items.stream().filter(product::equals).findAny().get();
//修改数量 返回Item总价 这里有分支,item修改是否应该在modifyCount中持久化
//1.modifyCount中持久化item那么数据库事务将被加载AppcationService层,容易产生大事务问题。
//2.modifyCount中不持久化item
//2.1写入消息总线,当OrderAggregate通过Reponsitory持久化时刷出消息持久化
//2.2 OrderAggregate中增加List items,modifyCount将item加入items。
item.modifyCount(count);
ItemAmount itemAmt = item.getItemAmt();
//修改订单总价
this.amt = new Amount(this.amt.get()+itemAmt.get());
return this.amt;
}
}
自我催眠法
思考:
“持有仓储法”思路,实现也一致,觉得反模式的原因是:聚合中含有数据库操作,有耦合基础服务的嫌疑。
但是换个方向去想:
内存也是存储介质,数据库也是存储介质,二者本来没有质的区别。二者相比只是对于内存操作,编程语言直接提供了API,而数据库访问需要依赖第三方库进行额外编码,假使能将数据库操作封装至跟内存操作一样自然,那么不是不可以让人接受。
Id关联法
(感觉上不太符合我的预期,有代码实现跟业务建模脱钩,耦合基础服务的嫌疑。容易退化为MVC,此句属于本人主观臆断)
大佬建议:
“对ddd理解,不能固化。聚合,本意是解决业务操作的一致性。大量文章,都表述为一次性加载,实操中是不现实的。解决 “业务操作一致性”,走 “id关联+内聚到一个函数+事务控制”,就很好。”
“没有必要强行ddd,拆分开也没有什么问题,通过id关联就可以。”
“业务建模时按照在同一聚合去建,落地时考虑现实,拆分聚合,通过id关联。”
思考:
跟”持有仓储法”很像,区别可能是在于代码写在哪里,但是这种方法总感觉不是OOP。
聚合拆分法
(我觉得applicationService中应该是跨领域的流程编排,Order,OrderItem有相同的生命周期不能算跨领域,只能算夸聚合。至于domainService,做为领域的一部分,理论上不应该涉及基础服务,只是存放业务相关但是不适合放在聚合中,也非跨域的代码)
大佬建议:
“如果OrderItem超过10万,20万, 这种情况一般大概率不需要一次性加载出来所有OrderItem,而是分页加载OrderItem, 这和聚合的特点冲突,建议设计成两个领域对象单独管理”
思路:
建立 OrderAggregate跟 OrderItemAggregate两个聚合,通过领域事件 实现最终一致。
灵活场景法(聚合拆分法Plus)
(感觉还是反模型,代码好理解,业务专家不一定认可,不像自然语言那样自然,为了性能做出妥协)
如demo中我们要修改OrderItem的数量,这样一个场景,场景主体是OrderItem而不是Order,Order被修改可以认为是副作用。
明确场景的情况下(明确上下文) 可以建模为OrderItemAggregate和OrderEntity 将1:n的关系转化为1:1。
//订单明细聚合
public class OrderItemAggregate {
//id
private Long id;
//商品(值对象)
private Product product;
//数量(值对象)
private Count count;
// item总价(值对象)
private ItemAmount itemAmt;
//Order实体
private OrderEntity orderEntity;
public void modifyCount(Count count) {
this.count = count;
ItemAmt itemAmt = new ItemAmt(this.product.getPrice()*this.count.get());
//order总价
Amt amt = this.orderEntity.getAmt();
//总价-item总价+新item总价
amt = new Amt(amt.get() - this.ItemAmt.get() + itemAmt.get());
//变更订单总价
this.orderEntity.modifyAmt(amt);
this.itemAmt = itemAmt;
}
}
//订单实体
public class OrderEntity {
//聚合唯一标识
private Long id;
//订单号(值对象)
private OrderNo orderNo;
//总价 (值对象)
private Amount amt;
public Amount modifyAmt(Amt amt) {
//修改订单总价
this.amt = amt;
}
}
//要订单明细中 名称叫电脑的商品数量修改100
orderItemAggregate.modifyCount(count);
删除/添加订单明细同理。
而,订单支付(订单被支付)的场景,业务主体是Order(这个场景下OrderItem甚至不会出现修改,当然也就没有必要加载OrderItem)。
总结
感谢各位大佬提供自己的思路为我解惑。
对与聚合落地,因为最后一种灵活场景变化聚合的思路,完全无关于基础服务,保持了聚合内的一致性,符合DDD领域只关注业务的思想,而且勉强符合OOP,且落地成本低,从心里上我更倾向于最后一种方式。唯一的难点在于说服自己他是一个正常的业务模型。
作 者 | 李宇飞(菜尊)
Original: https://www.cnblogs.com/88223100/p/Talking-about-Aggregation-in-DDD.html
Author: 古道轻风
Title: 浅谈DDD中的聚合
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/585392/
转载文章受原作者版权保护。转载请注明原作者出处!