

解决argmax不可导,无法进行反向传播的问题
出现的原因: argmax(x,y)不可导的根本原因是其向量空间不是光滑的,有尖锐的点和面;而是某些任务中,argmax会被插入到反向传播的计算图中。
解决: 在解决上个问题的基础上,我们可以获得one_hot形式的符合模型输出概率分布的采样值 y = onehot(argmax[log§ + G]), 但是其中的 one(argmax()) 还是不可导的操作,所以可以使用softmax 来近似 one(argmax()), 并增加一个温度函数 tau 来控制最后的结果和 真实onehot的近似程度。为什么softmax操作是可导的,其实softmax 就是 one(argmax()) 的光滑化。
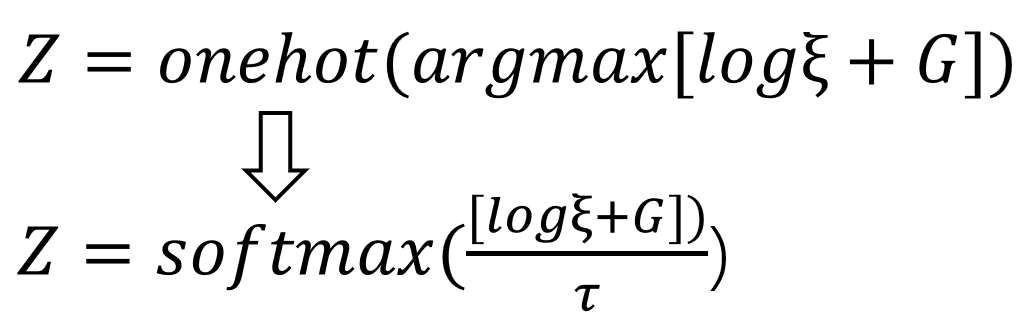

当 tau 足够小时,采样出来的向量十分接近 onehot 形式(类onehot但是不是真实的onehot), 而 tau 比较大时,采样的值接近于均匀分布。一般在训练初期,设置较大的tau,保证模型的充足的探索性;而在训练后期,一般设置较小的tau,生成比较稳定的 类似onehot向量。
下图是原论文[https://arxiv.org/pdf/1611.01144.pdf] 中对于 tau 参数大小的实验结果。
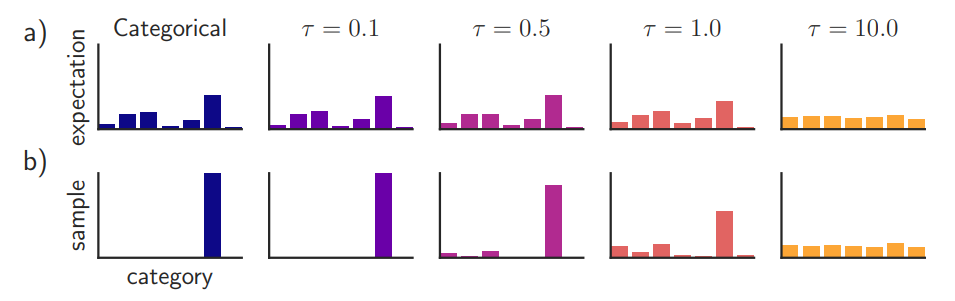
可以看出随着温度参数的增大采样值的分布逐渐由类onehot分布转换为均匀分布。
在 pytorch的 gumbel_softmax 的源码中可以对于其实现原理有一个清晰的认识。
其中有一个 hard 参数,当hard = False,函数直接返回采样值,当 hard = True, 函数是对采样值进行了一个 max 的操作,最后再和采样值组合在一起。这样的操作使得,在 forward 阶段, 传播的是 onehot值 y_hard; 而在 backpropagation 阶段,传播的是 y_soft 的梯度信息,因为 detach() 函数截断了其余的梯度传播。
def gumbel_softmax(logits: Tensor, tau: float = 1, hard: bool = False, eps: float = 1e-10, dim: int = -1) -> Tensor:
#########
gumbels = (
-torch.empty_like(logits, memory_format=torch.legacy_contiguous_format).exponential_().log()
) # ~Gumbel(0,1)
gumbels = (logits + gumbels) / tau # ~Gumbel(logits,tau)
y_soft = gumbels.softmax(dim)
if hard:
# Straight through.
index = y_soft.max(dim, keepdim=True)[1]
y_hard = torch.zeros_like(logits, memory_format=torch.legacy_contiguous_format).scatter_(dim, index, 1.0)
ret = y_hard - y_soft.detach() + y_soft
else:
# Reparametrization trick.
ret = y_soft
return ret
Original: https://www.cnblogs.com/jack-nie-23/p/16565036.html
Author: jacknie23
Title: Gumbel_Softmax 概要
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/582370/
转载文章受原作者版权保护。转载请注明原作者出处!