

图表示学习入门知识
数学基础看文章理解图的拉普拉斯变换,解答了上一周文章公式中的L拉普拉斯矩阵是怎么来的
本文仅限我个人记录学习历程所用,目前是大一在读,刚刚接触AI领域。如有不足和错误欢迎指出
1.图学习是干什么的
所谓图表示学习就是,我们在研究某些对象的时候,研究对象之前存在一定的图结构。比如人脉可以构成网络,图学习就是对样本节点所形成的网络进行研究。我们需要做的是把一个复杂的(或者也可能是比较简单的)网络用向量表示出来,进行运算和研究(当研究一个样本集时,我们得到的是一个矩阵)
- 基于图结构的表示学习
- 基于图特征的表示学习
基于图结构的表示是单纯从图的拓扑结构映射到结点的表示向量
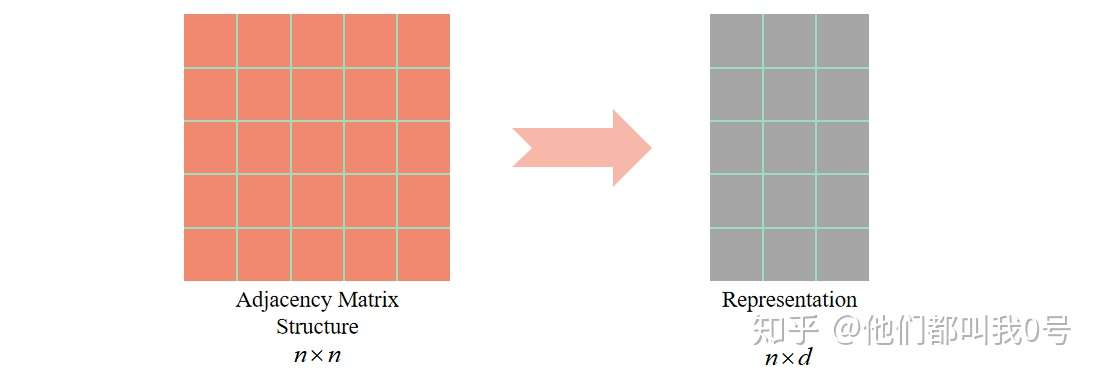

也就是只利用邻接矩阵去表示学习
但是基于图特征的表示学习,是结合了拓扑结构与特征信息
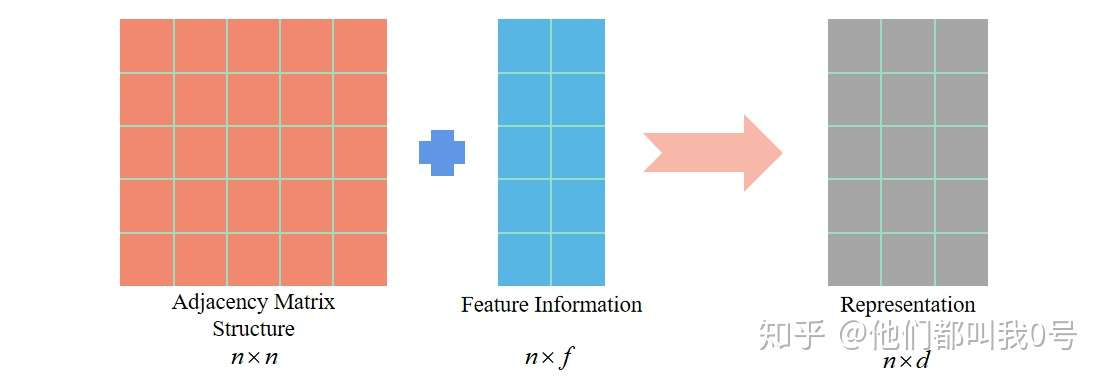
总之,经过表示,我们得到的是一个高维空间(R^D)中的样本数据集
这个提取向量的过程叫做embedding(嵌入)
embeding到底是什么???
embedding直接翻译意思是嵌入,但是你暂时可以不去理解这个直译,embedding可以是个名词或者动词,
当embedding作为名词时,他的意思类似于feature(特征),指的是 节点或者边的一些具体的信息,往往用tensor或者vector存储,这种 训练后得到的embedding可以用于神经网络的预测、分类等应用了;
embedding作为动词时,我觉得意思就是对于点和边来提取它的feature的这么一个动作。
然后,embedding我第一次见的时候出现在word2vec中,觉得也是一种理解的角度吧:就是把一个词转变为一个向量表示。那对于图来说,是不是可以理解为:图是一个高维度的数据结构,每个节点存储很多信息,包括他自身节点的信息,节点与节点直接是否有拓扑连接的关系等等一系列信息。那么这种高维信息现在我们想将它用一个向量表示,(用向量表示只是个例子),向量是一维的,那么从高维的图结构变成一维的向量,这种过程我觉得就是所谓的”嵌入”,你可以想象把一个立方体压平成一个薄片,对应高维度图结构信息压成一维度向量
2.基于图结构的表示学习
嵌入时,我们希望在图中接近的两个结点,被映射到向量空间时依然接近。那么怎么定义图中的”接近”呢
- 1-hop:两个相邻的结点就可以定义为临近;
- k-hop:两个 _k_阶临近的结点也可以定义为临近;
- 具有结构性:结构性相对于异质性而言。异质性关注的是结点的邻接关系;结构性将两个结构上相似的结点定义为”临近”。比方说,某两个点是各自小组的中心,这样的两个节点就具有结构性。
Deep walk模型
基于Randomwalk
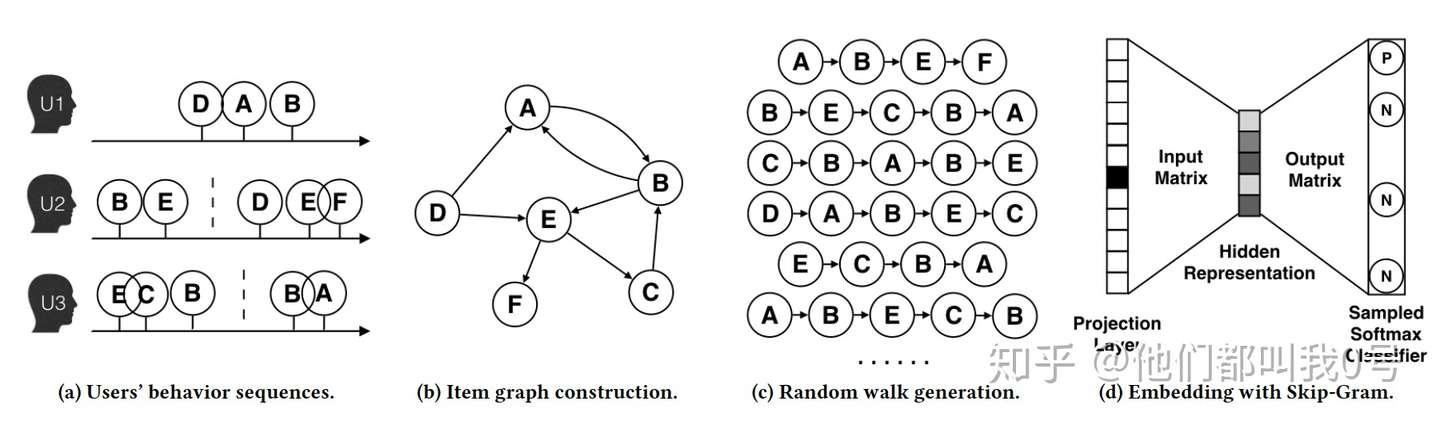
在结点处走向各个邻结点的概率相等
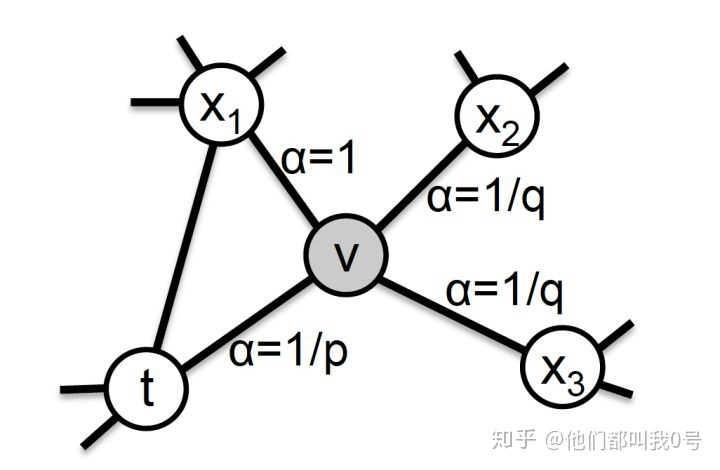
Node2vec
人为定义了一个结点向周围结点的跳转概率,控制概率的大小实现不同的效果
3.基于图特征的表示学习
加入了结点的特征矩阵,这一类的模型常常被叫做 图神经网络
GCN
- 图卷积网络GCN
CNN(卷积神经网络)在干的事就是一步一步聚合某个点周围的特征(局部感知和权值共享)
GCN中,思路相同,新的特征来自于上一层邻居结点特征的聚合
(H_{l}=\sigma(D^{-1/2}(A+I)D{-1/2}H^{l-1}W^l))
A是邻接矩阵,D是顶点的度矩阵,I为单位阵,W是神经网络层层间传播的系数矩阵H是该层的结点特征矩阵,第一层的(H^0=X),X是原始的结点特征矩阵
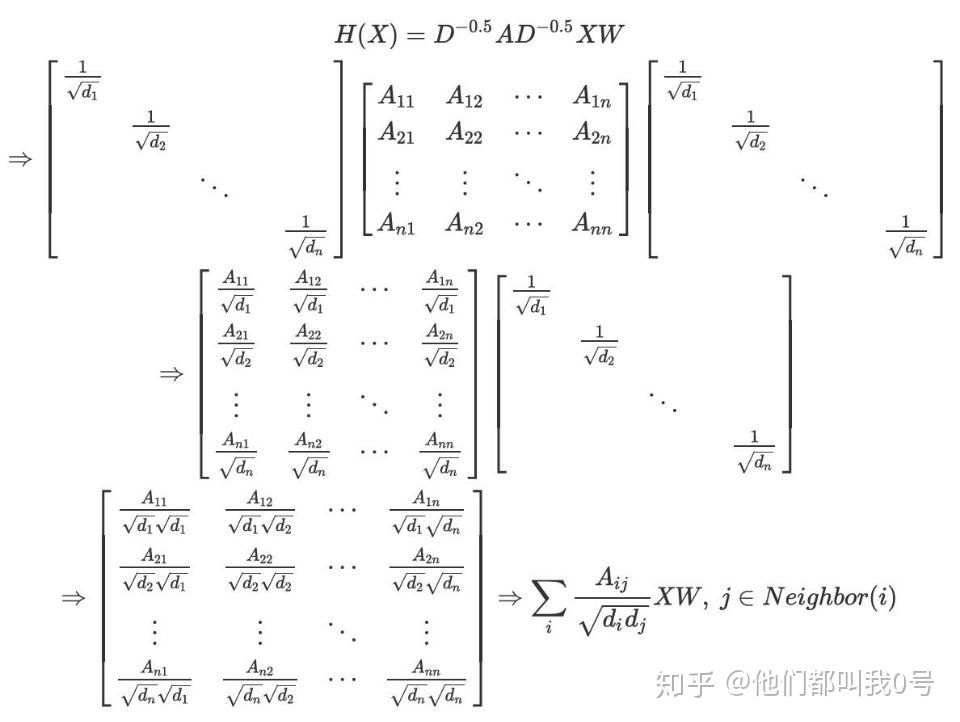
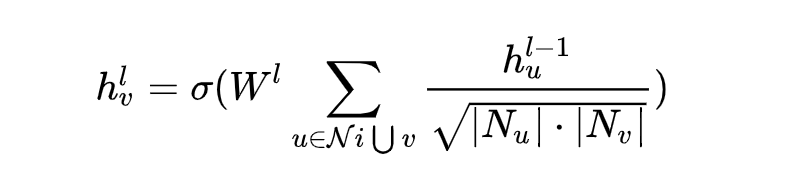
其中
是第 层网络中结点 的向量表示, 是第层网络上一结点的向量表示 表示的是结点 的邻居结点构成的集合。公式(3.1-1)、公式(3.1-2)和上面的一堆推导可以说是殊途同归。其核心的意思都表示的是” 邻居结点的聚合 “。
GraphSAGE
是一个基于空域的算法
特点:固定的采样倍率和不同的聚合方式
- 采样倍率
我们不去将每个结点的所有邻居进行聚合(那样一来计算量太大),而是设置一个定值(S_k),在第k层选择邻居时,最多选取(S_ k)个进行聚合。可以有效降低计算复杂度 - 聚合方式
(1): 对聚合结点的数量自适应 :向量的维度不应随邻居结点和总结点个数改变。
(2): 聚合操作对聚合结点具有 排列不变性 :e.g.
。
(3): 显然,在优化过程中,模型的计算要是 可导的。
也就是说图的拉普拉斯矩阵可求?
几种聚合方式
- 平均/求和聚合算子(mean/sum): (Agg^{sum}=\sigma(SUM{Wh_i+b,\forall v_j \in N(v_i)})) 其中W和b都是需要学习的参数
- 池化算子(pooling): (Agg^{pooling}=MAX\sigma({Wh_i+b,\forall v_j \in N(v_i)}))
MAX的含义是各元素上运用max算子计算
//这里补充另一个文章的内容知乎文章GraphSAGE解读
频域方法和空域方法
频域方法 :图的频域卷积是在傅里叶空间完成的,我们对图的拉普拉斯矩阵进行特征值分解,特征分解更有助于我们理解图的底层特征,能够更好的找到图中的簇或者子图,典型的频域方法有ChebNet,GCN等。但是图的特征值分解是一个特别耗时的操作,具有
的复杂度,很难扩展到海量节点的场景中。
空域方法 :空间方法作用于节点的邻居节点,使用
个邻居节点来计算当前节点的属性。基于空域的方法的计算量要比频域方法小很多,时间复杂度约为 ,GraphSAGE就是经典的基于空域的图模型。
归纳学习 :GraphSAGE是一个归纳学习的模型,所谓归纳学习是指可以对训练过程中见不到的数据直接计算而不需要重新对整个图进行学习。
转导学习 :与归纳学习对应的是转导学习(Transductive Learning),它是指所有的数据都可以在训练的时候拿到,学习的过程是在这个固定的图上进行学习,一旦图中的某些节点发生变化,则需要对整个图进行重新训练和学习。
显然相比于转导学习,归纳学习有更大的应用价值
GraphSAGE流程:
- 对邻居进行随机采样,每一跳抽样的邻居数不多于 个,如图1.2第一跳采集了3个邻居,第二跳采集了5个邻居;
- 生成目标节点的embedding:先聚合二跳邻居的特征,生成一跳邻居的embedding,再聚合一跳的embedding,生成目标节点的embedding;
(注意方向) - 将目标节点的embedding输入全连接网络得到目标节点的预测值。
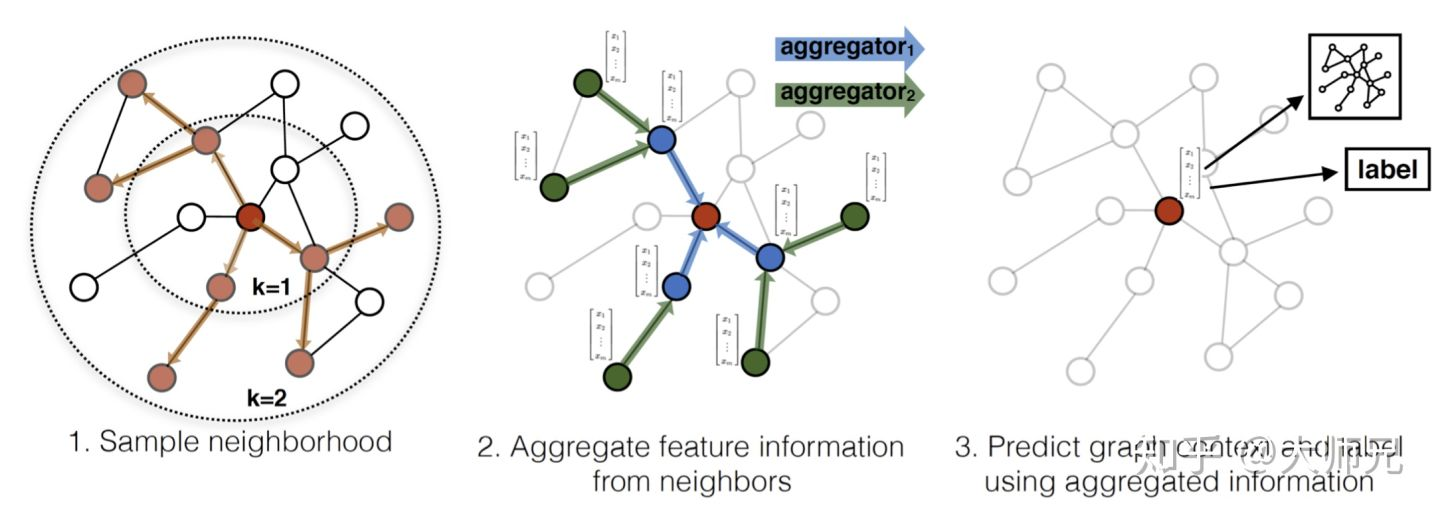
不断聚合邻居信息,然后迭代更新,迭代次数增加,每个节点上有全局的信息
GraphSAGE的伪代码:

1-7行对应采样过程,K是聚合的层数(不是采样的顺序,和采样顺序恰好反序,因为采样是从内到外,聚合是从外到内的,因此k的遍历是从K到1)
采样过程其对应的源码在 model.py的 sample函数,函数的入参 layer_infos是由 SAGEInfo元祖组成的list, SAGEInfo中的 neigh_sampler表示抽样算法,源码中使用的是均匀采样,因为每一层都会选择一组 SAGEInfo,因此每一层是可以使用不同的采样器的。 num_samples是当前层的采样的邻居数。采样过程的函数sample
def sample(self, inputs, layer_infos, batch_size=None):
""" Sample neighbors to be the supportive fields for multi-layer convolutions.
Args:
inputs: batch inputs
batch_size: the number of inputs (different for batch inputs and negative samples).
"""
if batch_size is None:
batch_size = self.batch_size
samples = [inputs]
# size of convolution support at each layer per node
support_size = 1
support_sizes = [support_size]
for k in range(len(layer_infos)):
t = len(layer_infos) - k - 1
support_size *= layer_infos[t].num_samples
sampler = layer_infos[t].neigh_sampler
node = sampler((samples[k], layer_infos[t].num_samples))
samples.append(tf.reshape(node, [support_size * batch_size,]))
support_sizes.append(support_size)
return samples, support_sizes
SAGEInfo = namedtuple("SAGEInfo",
['layer_name', # name of the layer (to get feature embedding etc.)
'neigh_sampler', # callable neigh_sampler constructor
'num_samples',
'output_dim' # the output (i.e., hidden) dimension
])
伪代码8-15是聚合过程
11行是对该结点的邻结点使用聚合函数进行聚合
12行是将这些聚合的邻居特征与中心节点的上一层的特征进行拼接,然后送到一个单层MLP中得到新的特征向量
MLP–(多层感知机),也叫人工神经网络;若需要详细了解,参考MLP
13行是对特征向量做归一化处理
对应的源码是 model.py中的 aggregate函数
def aggregate(self, samples, input_features, dims, num_samples, support_sizes, batch_size=None,
aggregators=None, name=None, concat=False, model_size="small"):
""" At each layer, aggregate hidden representations of neighbors to compute the hidden representations
at next layer.
Args:
samples: a list of samples of variable hops away for convolving at each layer of the
network. Length is the number of layers + 1. Each is a vector of node indices.
input_features: the input features for each sample of various hops away.
dims: a list of dimensions of the hidden representations from the input layer to the
final layer. Length is the number of layers + 1.
num_samples: list of number of samples for each layer.
support_sizes: the number of nodes to gather information from for each layer.
batch_size: the number of inputs (different for batch inputs and negative samples).
Returns:
The hidden representation at the final layer for all nodes in batch
"""
if batch_size is None:
batch_size = self.batch_size
# length: number of layers + 1
hidden = [tf.nn.embedding_lookup(input_features, node_samples) for node_samples in samples]
new_agg = aggregators is None
if new_agg:
aggregators = []
for layer in range(len(num_samples)):
if new_agg:
dim_mult = 2 if concat and (layer != 0) else 1
# aggregator at current layer
if layer == len(num_samples) - 1:
aggregator = self.aggregator_cls(dim_mult*dims[layer], dims[layer+1], act=lambda x : x,
dropout=self.placeholders['dropout'],
name=name, concat=concat, model_size=model_size)
else:
aggregator = self.aggregator_cls(dim_mult*dims[layer], dims[layer+1],
dropout=self.placeholders['dropout'],
name=name, concat=concat, model_size=model_size)
aggregators.append(aggregator)
else:
aggregator = aggregators[layer]
# hidden representation at current layer for all support nodes that are various hops away
next_hidden = []
# as layer increases, the number of support nodes needed decreases
for hop in range(len(num_samples) - layer):
dim_mult = 2 if concat and (layer != 0) else 1
neigh_dims = [batch_size * support_sizes[hop],
num_samples[len(num_samples) - hop - 1],
dim_mult*dims[layer]]
h = aggregator((hidden[hop],
tf.reshape(hidden[hop + 1], neigh_dims)))
next_hidden.append(h)
hidden = next_hidden
return hidden[0], aggregators

具体是进行怎样的线性变换呢???
LSTM的具体算法又是什么???
模型训练
支持无监督训练和有监督训练2种方式
GraphSAGE的无监督学习的理论基于假设:节点(u)与其邻居(v)具有类似的的embedding,而与没有交集的节点(v_n)不相似,损失函数为:
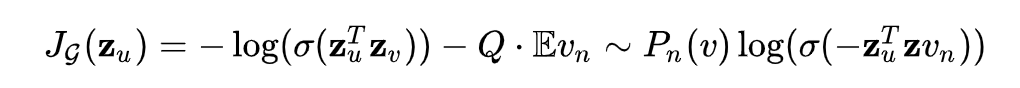
其中(z_u)为结点u通过GraphSAGE得到的embedding,v是结点u通过RandomWalk得到的邻居(v_n ~ P_n(v))表示负采样,Q为样本数
有监督学习比较简单,使用满足预测目标的任务作为损失函数,例如 交叉熵等。
归纳学习
GraphSAGE的一个强大之处是它在一个子集学到的模型也可以应用到其它模型上,原因是因为GraphSAGE的参数是共享的。如图3所示,在计算节点A和节点B的embedding时,它们在计算两层节点用的参数相同。
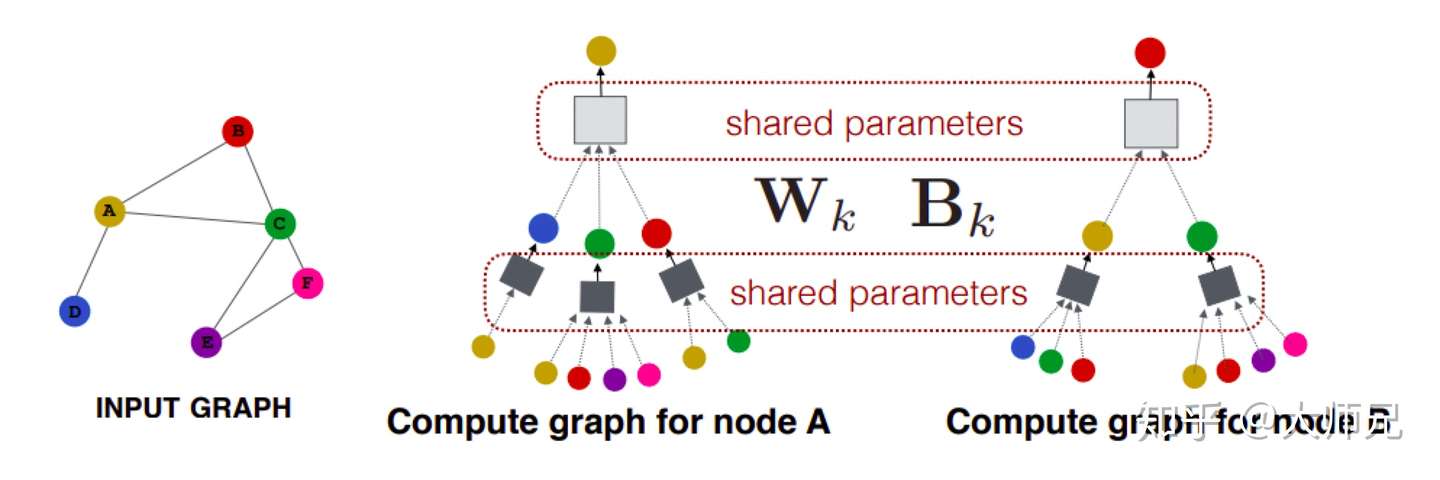
图3:GraphSAGE的归纳学习得益于它的参数共享
当有一个新的图或者有一个节点加入到已训练的图中时,我们只需要知道这个新图或者新节点的结构信息,通过共享的参数,便可以得到它们的特征向量。
理解图的拉普拉斯矩阵
微积分中,对一个多元函数,拉普拉斯算子是所有自变量的非混合二阶偏导数之和
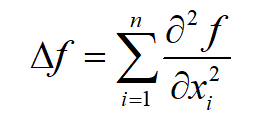
实际我们只能近似计算导数值,也就是数值微分,在(\Delta x)的值很小时
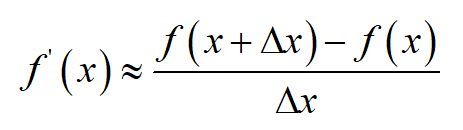
对于二阶导数有:
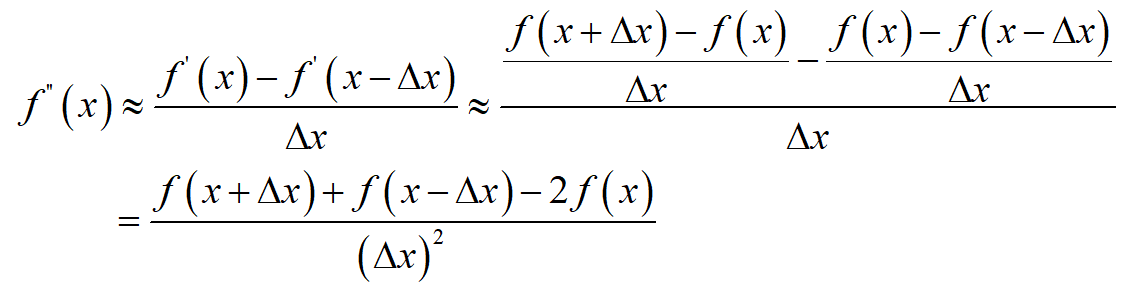
若是二元函数,
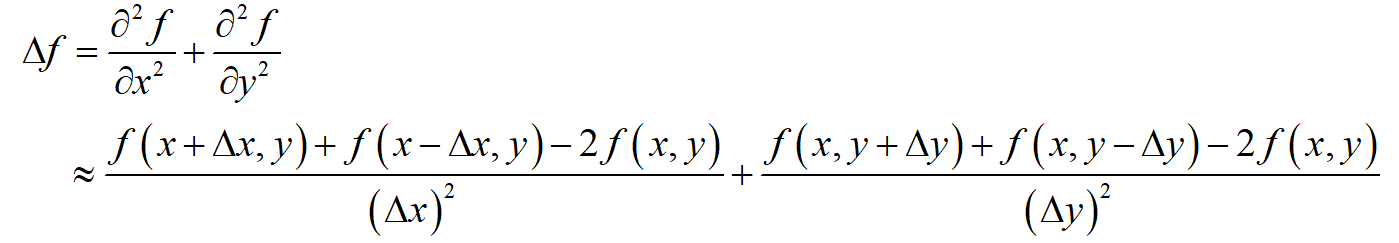
为了简化,做出如下假设
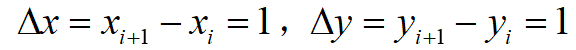
于是,在对二元函数进行采样,使之离散化之后,我们可以得到拉普拉斯算子的计算公式
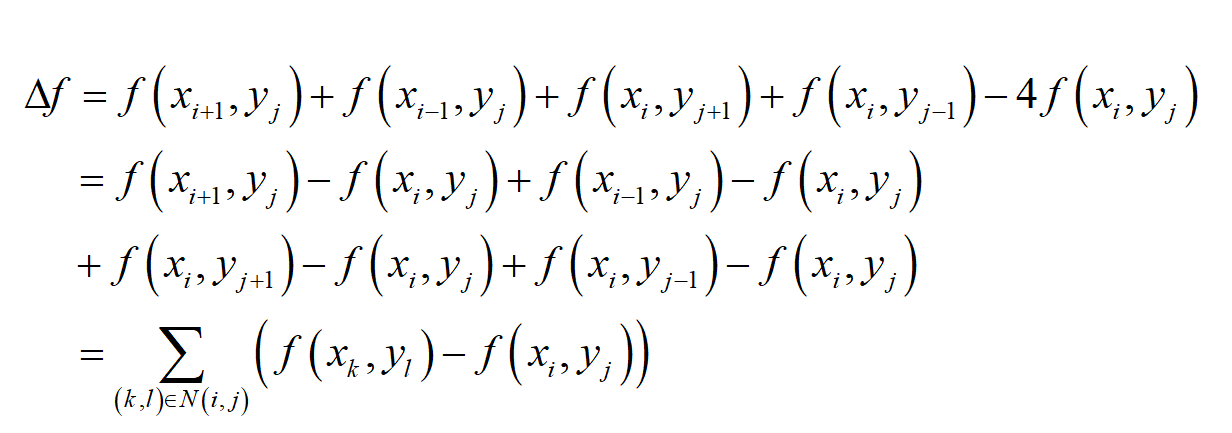
N(i, j)是点(xi, yj)的所有邻居点的集合。
我们将图的顶点看作函数值,则可以得到图的拉普拉斯算子。在这里调换2个f的位置,与之前相比多一个负号。然后我们把边的权重也考虑进去,得:
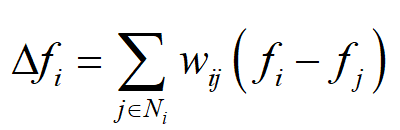
Ni是结点i的邻结点的集合
若j不属于Ni,则(w_{ij}=0), 因此可以把j的范围扩到V,然后进行如下运算:
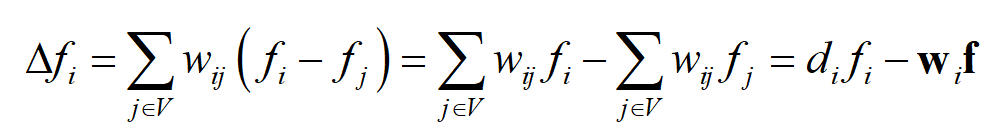
f是所有结点的函数值构成的列向量
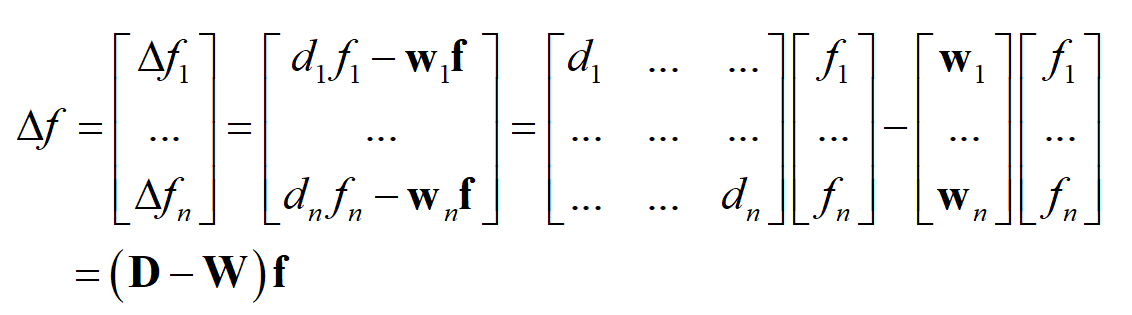
D为加权度矩阵,W是邻接矩阵,共有n个结点,定义拉普拉斯矩阵为:(L=D-W)
D和W都是对称矩阵,因此L也是对称的。
同时我们规定,每个结点与其自身的权值为0.所以W的主对角线上的元素均为0.也就是说L的对角线上都是D对角线上的元素,即每个结点的加权度。
拉普拉斯矩阵的性质

证明:
- 直接根据L的定义,L=D-W,直接计算得到
- 由于权均非负,立刻由1得到
- 将特征值为0带入,去验证特征多项式,发现成立;
- 由2和3可以得到4(对称半正定矩阵所有特征值非负)
可以证明L的特征值0的重数k等于图G的连通分量的个数
归一化拉普拉斯矩阵
有2种归一化方法,目的都是让L的主对角线上的元素为1
1.对称归一化
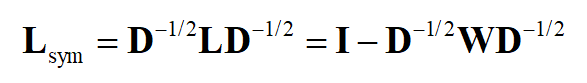
计算过程:
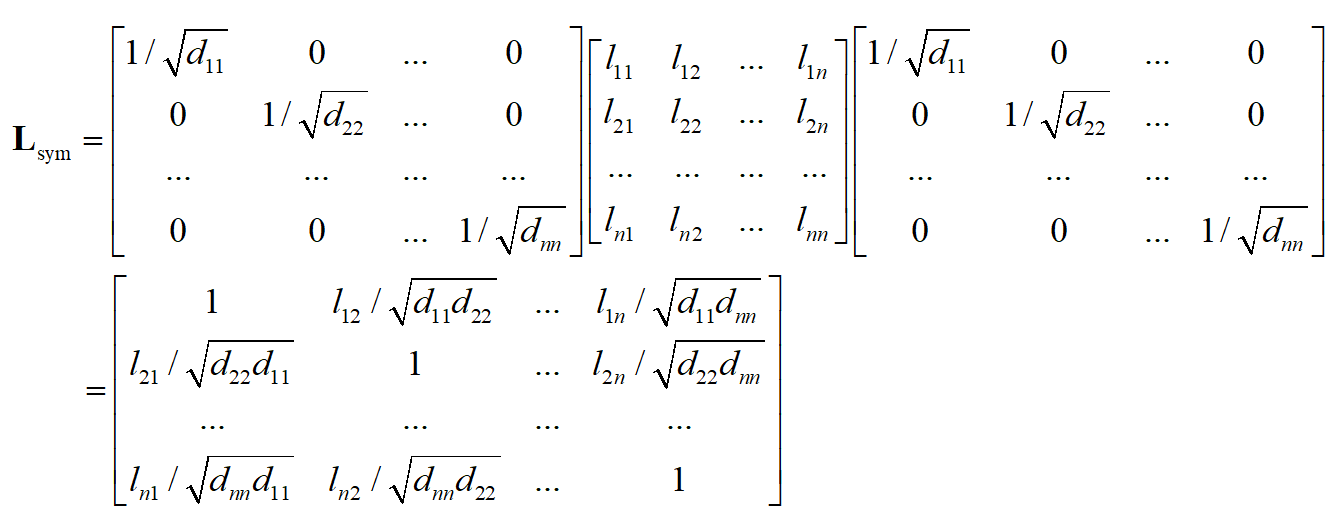
2.随机漫步归一化
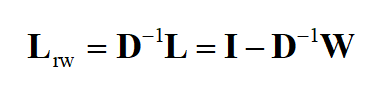
计算过程:
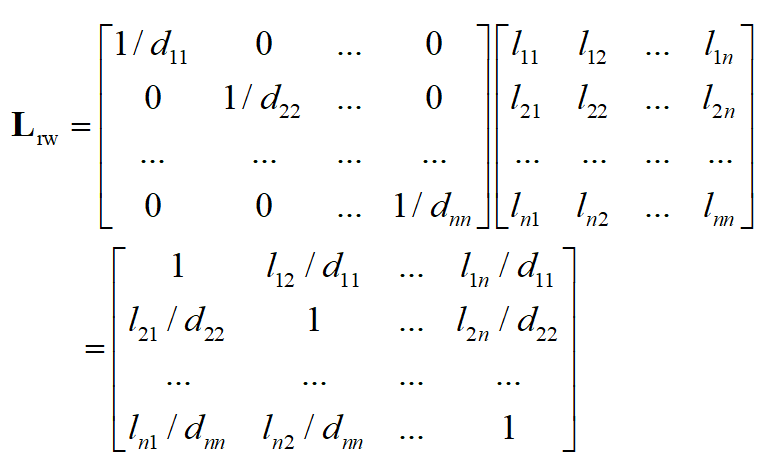
Original: https://www.cnblogs.com/Ztyu279/p/16379645.html
Author: Ztyu279
Title: 机器学习入门–图学习基础01
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/577615/
转载文章受原作者版权保护。转载请注明原作者出处!