

核化线性降维
线性降维方法假设从高维空间到低维空间的函数映射是线性的,然而,在不少现实任务中,可能需要非线性映射才能找到恰当的低维嵌入。
流行学习
“流形”是在局部与欧氏空间同胚的空间,换言之,它在 局部具有欧氏空间的性质,能用欧氏距离来进行距离计算。若低维流形嵌入到高维空间中,则数据样本在高维空间的分布虽然看上去非常复杂,但在局部上仍具有欧氏空间的性质,因此,可以容易地在局部建立降维映射关系,然后再设法将局部映射关系推广到全局
1.等度量映射
Isomap,认为低维流行嵌入到高维空间后,直接在高维空间中计算直线距离有误导性,因为高维空间中的直线距离在低维嵌入流行上不可达。
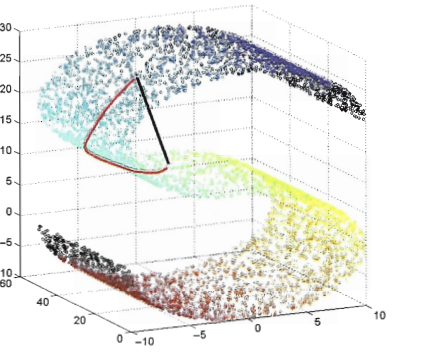

可以对每个点基于欧氏距离找临近点,建立临近连接图,然后挨个计算两点之间距离,再求和。可以利用Dijkstra算法或Floyd算法来求最短距离,这实际上就是求一个图上两点之间的最短路径。在数据结构课上已经学的很熟练了。
得到任意两点间的(最短)距离后,可以用MDS方法获得样本点在低维空间中的坐标,完成学习。

什么是MDS方法?
缓解维数灾难的一个重要途径是降维(dimension reduction), 亦 称 “维数
约 简 “,即通过某 种数学变换将原始高维属性空间转变为一个低维”子空间”(subspace),在这个子空间中样本密度大幅提高,距离计算也变得更为容易.为什么能进行降维?这是因为在很多时候,人们观测或收集到的数据样本虽是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的 一 个 低 维 “嵌入”embedding)
MDS(多维缩放):是一种经典的降维方法。若要求原始空间中样本之间的距离在低维空间中得以保持如图 10.2所示即得到”多维缩放”(Multiple Dimensional Scaling,简称 MDS)
推导过程手写如下:

注意,Isomap仅仅是得到了训练样本在低维空间中的坐标,如何把新样本映射到低维空间?常常是用训练数据训练一个回归学习器来对新样本的低维空间坐标进行预测,目前并无更好的方法。
对近邻图的构建通常有两种做法,一种是指定近邻点个数,例如欧氏距离
最 近 的 k 个点为近邻点,这样得到的近邻图称为k 近邻图;另一种是指定距离阈 值 c ,距离小于e 的点被认为是近邻点,这样得到的近邻图称为€近邻图.两种方式均有不足,例如若近邻范围指定得较大,则距离很远的点可能被误认为近邻,这 样 就 出 现 “短路”问题;近邻范围指定得较小,则图中有些区域可能与其他区域不存在连接,这 样 就 出 现 “断路”问题.短路与断路都会给后续的最短路径计算造成误导.
2.局部线性嵌入
想办法保留原样本空间中的线性关系
图嵌入一般框架
图嵌入的本质是利用数据的几何结构关系挖掘潜藏在数据中的局部、全局、判别等结构信息,以此来辅助下游的学习任务。
常见的图嵌入模式:
- 局部图
- 全局图
- 判别图
- 系数图
- 等等
PCA对应全连接的全局图(全联通?);
线性判别分析(LDA)对应判别图,这种图根据有标记样本连接同类。边的权值由其类别样本数确定。
局部保留投影(LPP)对应局部连接的局部图,边的权值通过核函数等方式确定。
graph TD A(图嵌入框架)–>B(图的构建) A–>C(图的权值) A–>D(图的优化)
1.一般性图嵌入框架的基本原则
原始数据上的平滑、流行、聚类等假设。然后通过构建的图谱特征逼近数据的流行结构信息,然后根据图学习的具体任务(降维、半监督分类、聚类等)对图嵌入优化。
图的顶点根据相似性测度对顶点相连接的边进行不同程度的权重赋值,以此突出不同顶点之间的结构关系,最后根据不同的学习与诊断仍无确定不同的优化目标和参数,输出训练好的模型。
2.图的构造
分为2步:
- 建立边的连接
- 边的权值赋值
全局图:描述数据空间任意两点的结构关系,反映数据整体结构
局部图:通过数据点之间的近邻等几何结构关系,反映数据空间局部几何结构关系
稀疏图:边与权值经过一定约束,弱化一些不重要的连接
判别图:利用先验的判别结构信息提取数据的判别性特征信息
全局图
容易构造且参数少,求解简单;缺点是计算量大
局部图
处理非线性数据时意义突出。常见的构造方式已经在上文中说明:
- k邻近图
- (\epsilon)-邻近图
k邻近图参数选择比较简单,使用更为广泛
稀疏图
与全连接的图相对,稀疏图其顶点只与一部分结点连接(即有的边权值为0),计算速度比全连接更快,但权重不能学习,权值超参数改变时,相应的邻近结构关系可能改变,优化过程有难度
判别图
在图嵌入先验判别信息。
综上可知,顶点之间的距离十分重要
常见的距离度量公式归纳为
(d(x_i,x_j)=(\sum^d_{k=1}{\Vert x_{ik}-x_{jk} \Vert}^{1/q}),q\ge 1)
q=1———–绝对值距离
q=2———–欧氏距离
$q=+ \infin $—切比雪夫距离
常见的边权值方法为高斯热核

当然还有其它形式的权重赋值方式
下面看核函数
核函数
在现实任务中,训练样本可能是线性可分的,即存在一个划分超平面能将训练样本正确分类;也可能原始样本空间不存在这样能正确划分的超平面,例如”异域”:
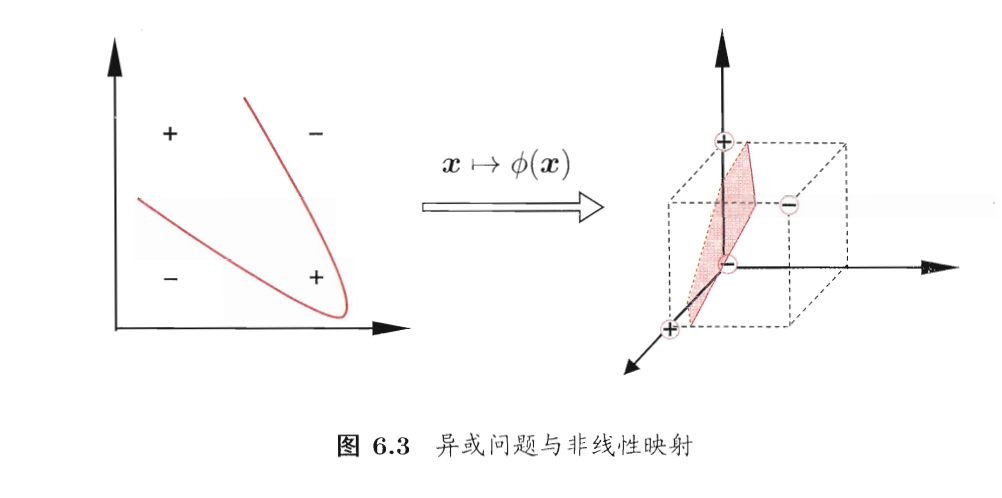
这时就需要将样本映射到一个更高维的空间,使得它线性可分。因为有定理: 如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分.
令(\phi(x))表示将(x)映射后的特征向量,于是特征空间中划分超平面对应的模型为:
(f(x)=\omega^T\phi(x)+b)
而核函数就是用来表示这个映射的(\phi)的,引入核函数是为了方便计算。相关的引入原因要用到支持向量机的理论,待补充。
3.图优化
基于图的降维任务
目的是将数据从高维空间映射到低维空间。图的连接方式与权重赋值确定后,要找到优化最优投影与映射方向。
我的理解是,根据需要,选择不同的侧重点去优化(降维)
文章中介绍的是线性判别分析(LDA),该算法希望保持数据总体协方差最小。在此基础上的MFA算法弥补了LDA假设数据需要服从高斯分布的局限性。用到了本征图缩小同类标记样本间的距离,用惩罚图增加异类样本间的距离
基于图的半监督分类
嵌入过程需要满足2个条件:
- 在对标记样本进行映射时,其嵌入或分类不得偏离现有标签
- 保持所构建的关系图上数据与流行结构尽可能平滑,即保持相似样本的低维映射或分类过程尽可能接近彼此。
基于图的半监督学习可以表示为:
(min\sum i^L(f(x_i)-y)^2+\sum^{L+U}{i,j}w_{i,j}(f(x_i)-f(x_j)))
其中(y)为实际输出标签值
Original: https://www.cnblogs.com/Ztyu279/p/16393160.html
Author: Ztyu279
Title: 机器学习入门笔记02–流行学习与图嵌入理论基础
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/577613/
转载文章受原作者版权保护。转载请注明原作者出处!