



; HOLE
Holographic Embeddings of Knowledge Graphs
基于向量的循环相关
任务
- 提出全息嵌入(holographic embeddings,HOLE)来学习整个知识图的组成向量空间表示。
- 在组合向量空间模型的框架内研究从知识图谱学习的问题。
方法(模型)
compositional vector space models
- 组合向量空间模型
P r ( ϕ p ( s , o ) = 1 ∣ Θ ) = σ ( η s p o ) = σ ( r p T ( e s ◦ e o ) ) Pr(\phi_p(s,o)=1|\Theta)=\sigma(\eta_{spo})=\sigma(\mathbf{r}_p^T(\mathbf{e}_s◦\mathbf{e}_o))P r (ϕp (s ,o )=1 ∣Θ)=σ(ηs p o )=σ(r p T (e s ◦e o ))
ϕ p ( s , o ) \phi_p(s,o)ϕp (s ,o ):特征函数
◦ :复合算子,从嵌入e s \mathbf{e}_s e s ,e o \mathbf{e}_o e o 创建( s , o ) (s,o)(s ,o )的复合向量表示。
- 通过最大限度地减少(正则化)logistic损失来实现最好地解释数据集的实体和关系的表示。
min ∑ i = 1 m l o g ( 1 + e x p ( − y i η i ) ) + λ ∣ ∣ Θ ∣ ∣ 2 2 \min\sum_{i=1}^mlog(1+exp(-y_i\eta_i))+\lambda||\Theta||_2^2 min i =1 ∑m l o g (1 +e x p (−y i ηi ))+λ∣∣Θ∣∣2 2
对于关系数据,最小化 logistic 损失具有额外的优势,它可以帮助为复杂的关系模式找到低维的嵌入。
- KGs只存储正确三元组,这种情况下可以使用 pairwise ranking loss。
min Θ ∑ i ∈ D + ∑ j ∈ D − max ( 0 , γ + σ ( η j ) − σ ( η i ) ) \min_\Theta\sum_{i\in{D_+}}\sum_{j\in{D_-}}\max(0,\gamma+\sigma(\eta_j)-\sigma(\eta_i))Θmin i ∈D +∑j ∈D −∑max (0 ,γ+σ(ηj )−σ(ηi ))
例如将现有三元组的概率排序为高于不存在三元组的概率。
d+,d−:表示存在和不存在的三元组的集合。
η j > 0 \eta_j>0 ηj >0:指定边距的宽度。
Holographic Embeddings(HOLE)
为了将张量积的表达能力与TransE的效率和简单性结合起来,使用向量的循环相关来表示实体对。
在HOLE中,不只是存储关联,而是学习能最好地解释所观察到数据的嵌入。
1. 复合算子
a ◦ b = a ∗ b a◦b=a\ast b a ◦b =a ∗b
∗ \mathbf{*}∗:表示循环相关
- 三元组的概率模型
P r ( ϕ p ( s , o ) = 1 ∣ Θ ) = σ ( r p T ( e s ∗ e o ) ) Pr(\phi_p(s,o)=1|\Theta)=\sigma(\mathbf{r}_p^T(\mathbf{e}_s\ast \mathbf{e}_o))P r (ϕp (s ,o )=1 ∣Θ)=σ(r p T (e s ∗e o ))
使用复合算子相对于卷积的优点
- Non-commutative:对建模有向图的非对称性很有必要。
-
Similiarity Component:对实体相似性的关系建模有帮助。
-
SGD
使用随机梯度下降
e o t + 1 ← e o t − μ ∂ L ∂ f ∂ f ∂ η ( r p t ∗ e s t ) \mathbf{e}_o^{t+1}\leftarrow\mathbf{e}_o^{t}-\mu\frac{\partial L}{\partial f}\frac{\partial f}{\partial \eta}(\mathbf{r}_p^t\ast e_s^t)e o t +1 ←e o t −μ∂f ∂L ∂η∂f (r p t ∗e s t )
μ \mu μ:学习率
-
方法
-
把实体和关系都表示为向量。给定一个事实( h , r , t ) (h,r,t)(h ,r ,t ),首先使用循环相关操作将实体表示形式组成h ∗ t ∈ R h*t∈R h ∗t ∈R。
- 然后将组合向量与关系表示形式匹配,以对事实进行评分。
数据集
- WN18
- FB15K
性能水平
公平起见,评价时使用相同的损失和优化方法对参与比较的模型重新训练。
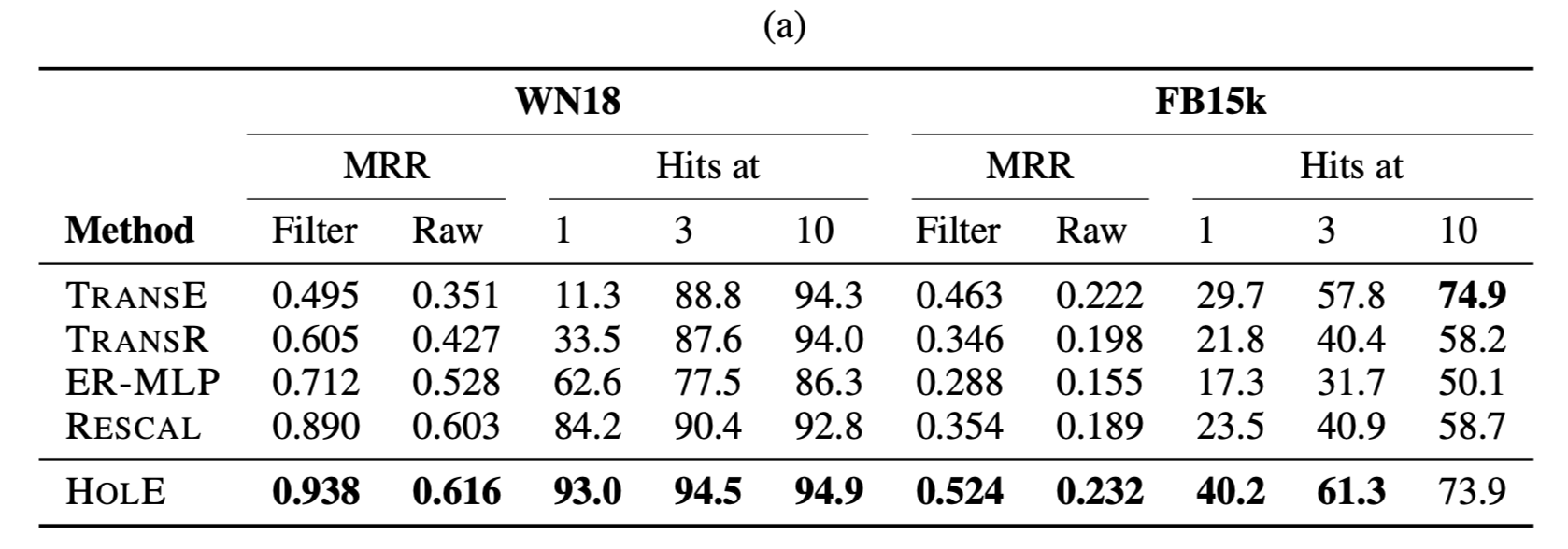
Filter:由于对于给定的 predicate-object,测试集中可以存在多个正确的三元组,因此从R p ( s ′ , o ) = 1 R_p(s^{‘},o)=1 R p (s ′,o )=1 and $ s\neq s{‘}$的排序中删除所有实例,只考虑测试实例在所有错误实例中的排序。同理从$R_p(s,o{‘})=1$ and $ o\neq o^{‘}$的排序中删除所有实例。
- 在WN18数据集的测试中,HOLE的表现都最为出色。
- 在FB15k数据集表现也优于其他模型,但是效果不是很显著。
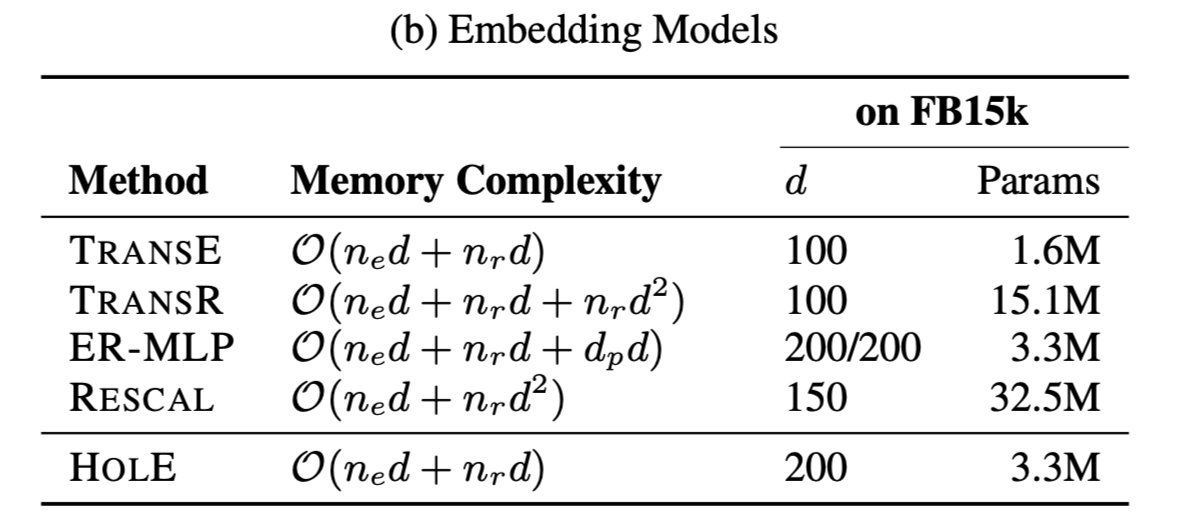
- 与Rescal相比,HOLE的参数减少很多。尽管embedding的维数d比rescal的大,但由于其存储复杂度仅线性地依赖于d,所以总体参数数目显著减少。
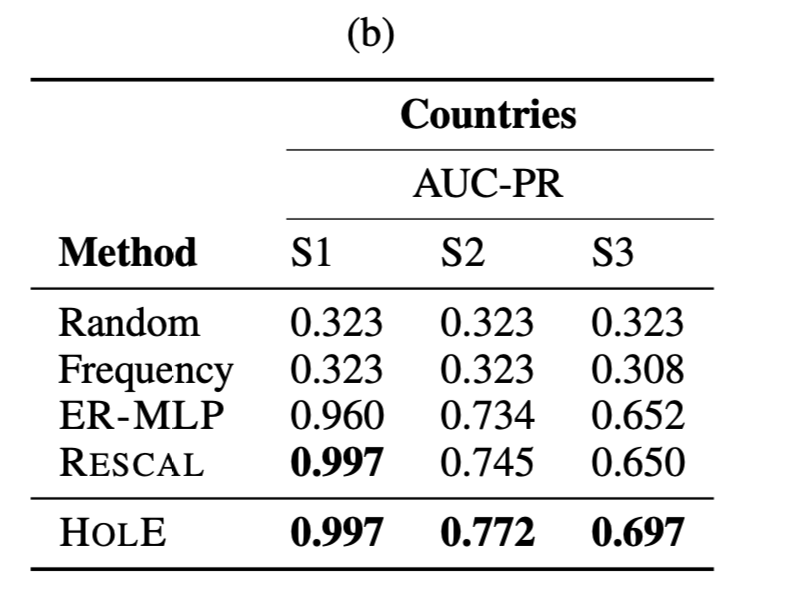
l o c a t e d I n ( c , r ) locatedIn(c,r)l o c a t e d I n (c ,r ):c:countries(国家),r:regions(地区)。
l o c a t e d I n ( c , s ) locatedIn(c,s)l o c a t e d I n (c ,s ):s:subregions(次区域)。
- 任务S1 设置:对于test/valid中,只将l o c a t e d I n ( c , r ) locatedIn(c,r)l o c a t e d I n (c ,r )的countries设置为missing。 性能:丢失的三元组几乎可以完美预测。
- 任务S2 设置:将l o c a t e d I n ( c , s ) locatedIn(c,s)l o c a t e d I n (c ,s )中countries和subregions设置为missing。 性能:相对于其他数据集表现最好。
- 任务S3 设置:将l o c a t e d I n ( n , r ) locatedIn(n,r)l o c a t e d I n (n ,r )中countriesn的neighbors,regions设置为missing。 性能:预测难度最大,但相对于其他数据集表现较好。
RESCAL和ER-MLP较差的结果很可能是过拟合导致。
; 结论
- HOLE 它利用向量的循环相关性来创建二元关系数据的组合表示。通过使用相关性作为组合算子,可以捕获丰富的交互,同时保持高效的计算,易于训练,并可扩展到非常大的数据集。
- 循环相关对成对的相互作用进行压缩。因此,HolE对每个关系只需要O ( d ) O(d)O (d )参数,并且循环相关是不符合交换律的,即h ∗ t ht h ∗t不等于t ∗ h th t ∗h。所以HolE能够 对不对称关系进行建模。
思考
- 循环相关的优势:
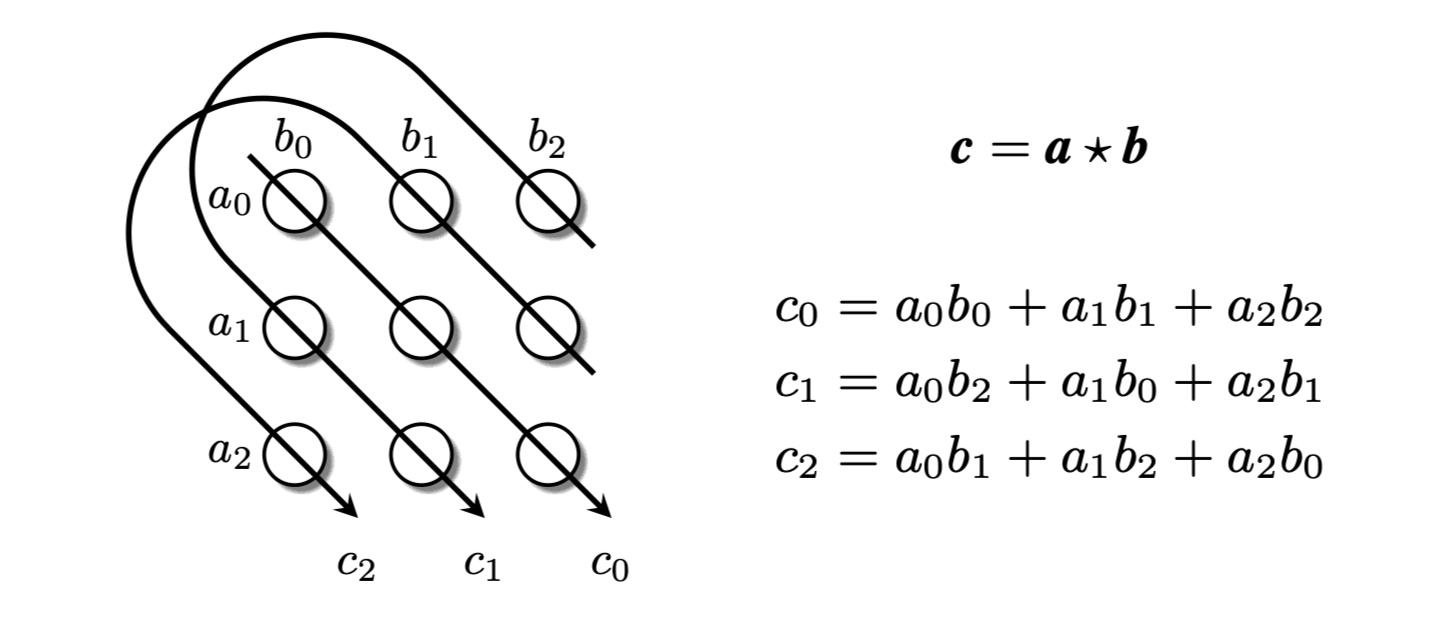
- 与张量积相比,循环相关具有不增加复合表示的维数的重要优点。
- 空间复杂度在实体表示的维度d中是线性的,运行时复杂度在d中是对数线性的。对总体参数的数量和运行效率都有显著影响。
- 组合表示与其构成的表示具有相同的维数。
Original: https://blog.csdn.net/qq_39827677/article/details/109491663
Author: 没有胡子的猫
Title: 【HOLE】论文浅读:Holographic Embeddings of Knowledge Graphs
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568817/
转载文章受原作者版权保护。转载请注明原作者出处!