

文章目录
- TBSL架构
* - step1:模板生成
- step2:模板匹配与实例化
- step3:排序打分
- TBSL的主要缺点
- 自动生成模板
* - QUINT架构
- step1:模板的定义与生成
- step2:模板的匹配和实例化
- step3:排序
- step4:复杂问题处理
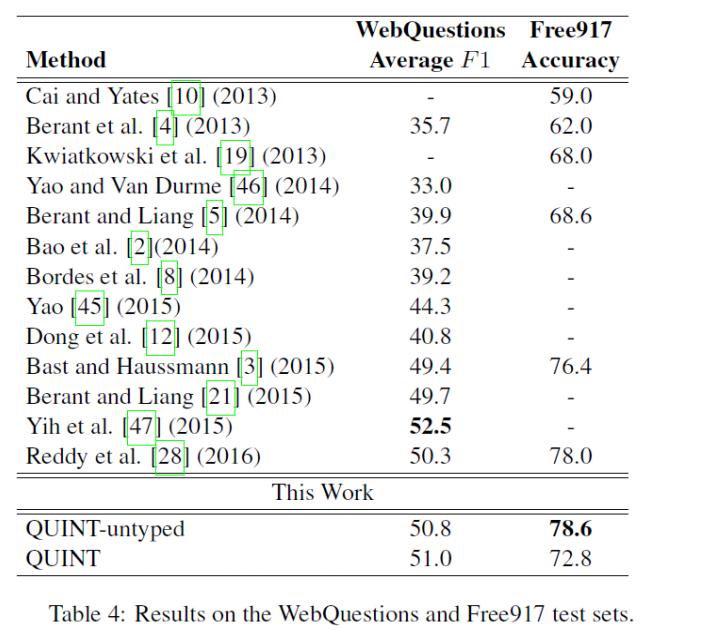
- 实验结果
- 方法的主要贡献点
- 模板方法的优缺点
基于模板的方法包含模板定义、模板生成,模板匹配三大部分。
论文:TBSL(Unger et al.2012)。
TBSL架构
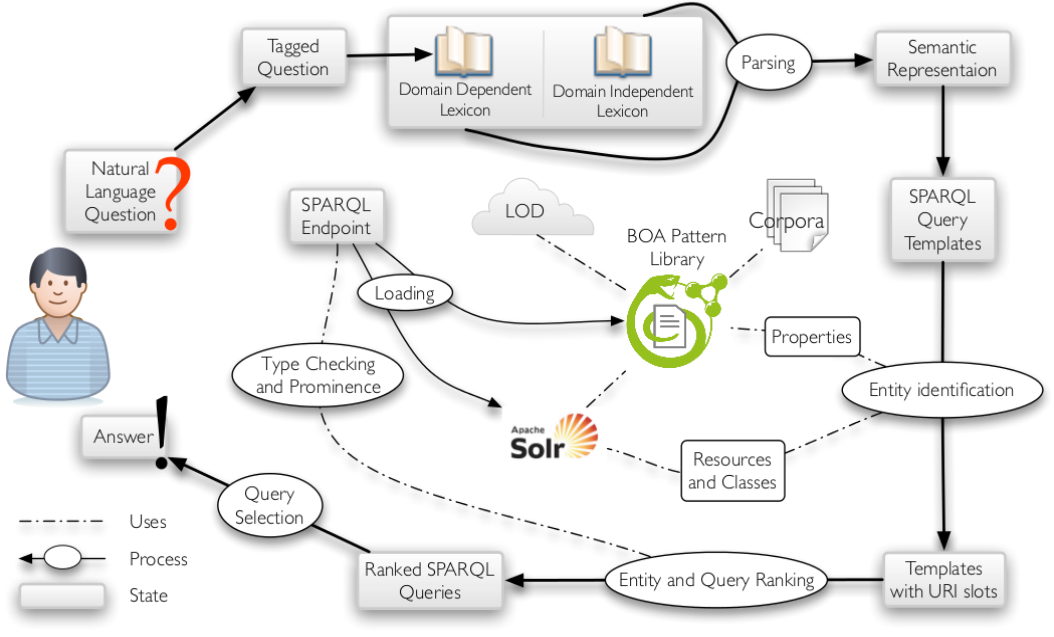

; step1:模板生成
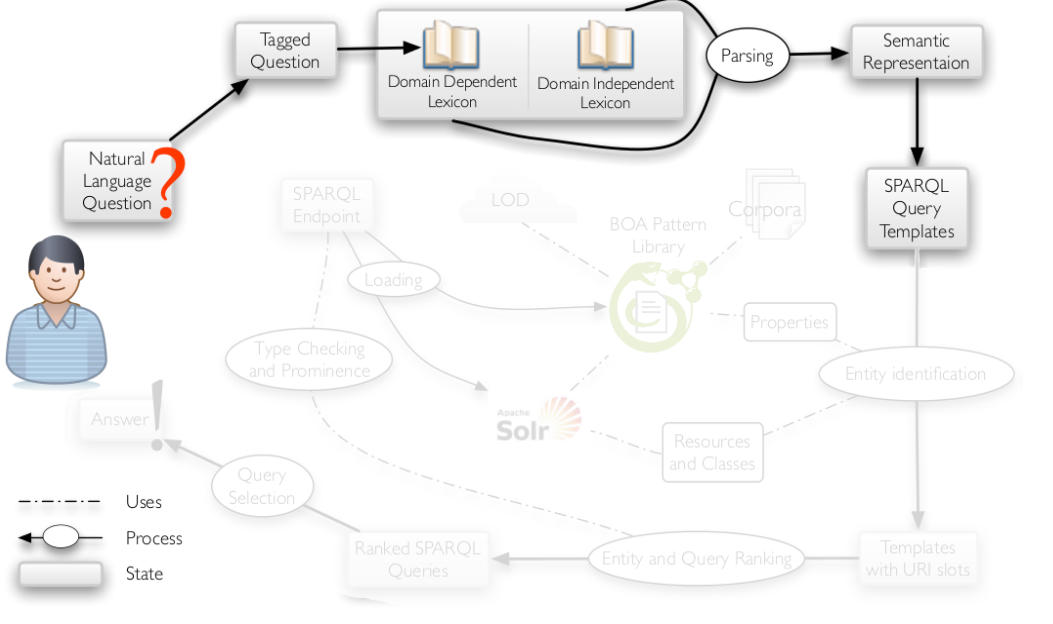
模板生成大致分为如下四个步骤:
- 获取自然语言问题的POS 标记信息
- 基于POS 标记、语法规则表示问句
- 利用领域相关或领域无关词汇辅助解决问题
- 最后将语义表示转化为一个SPARQL 模板
示例:who produced the most films?

step2:模板匹配与实例化
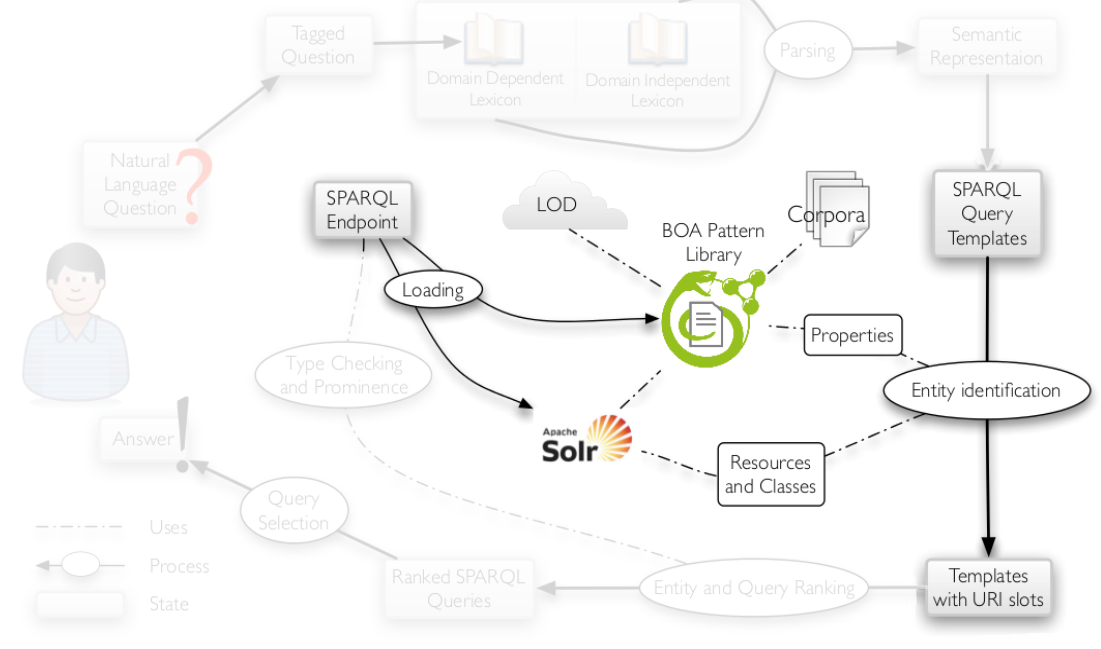
有了SPARQL模板以后,需要进行实例化与具体的自然语言 问句相匹配。即将自然语言问句与知识库中的本体概念相映射的过程。
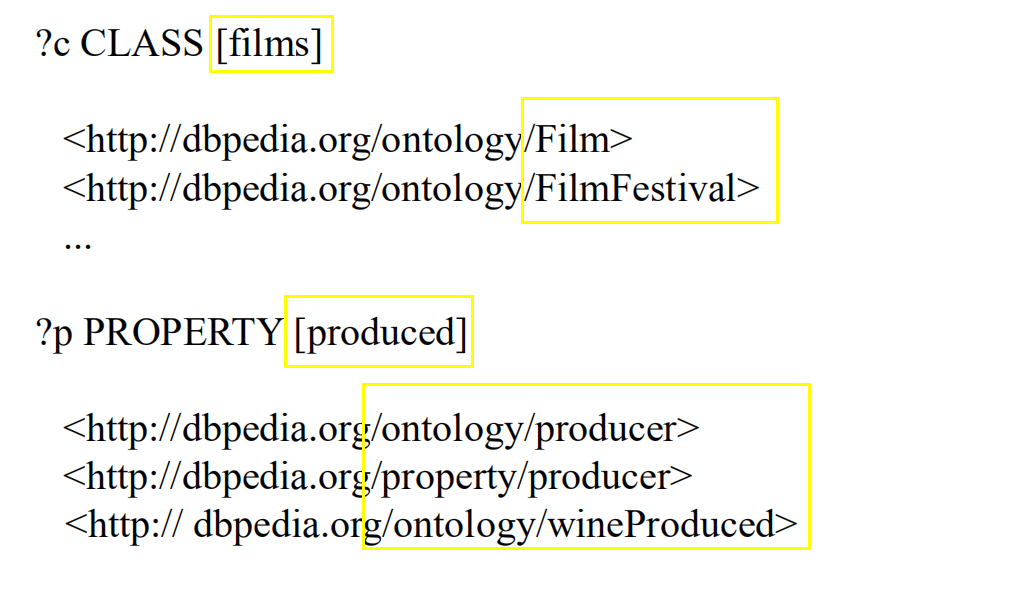
对于resource 和 class实体识别,用WordNet 定义知识库中标签常用方法或计算字符串相似度。对于property标签,将还需要与存储在BOA 模式库中的自然语言进行比较,最高排位的实体将作为填充查询槽位的候选答案。
示例:who produced the most films?
; step3:排序打分
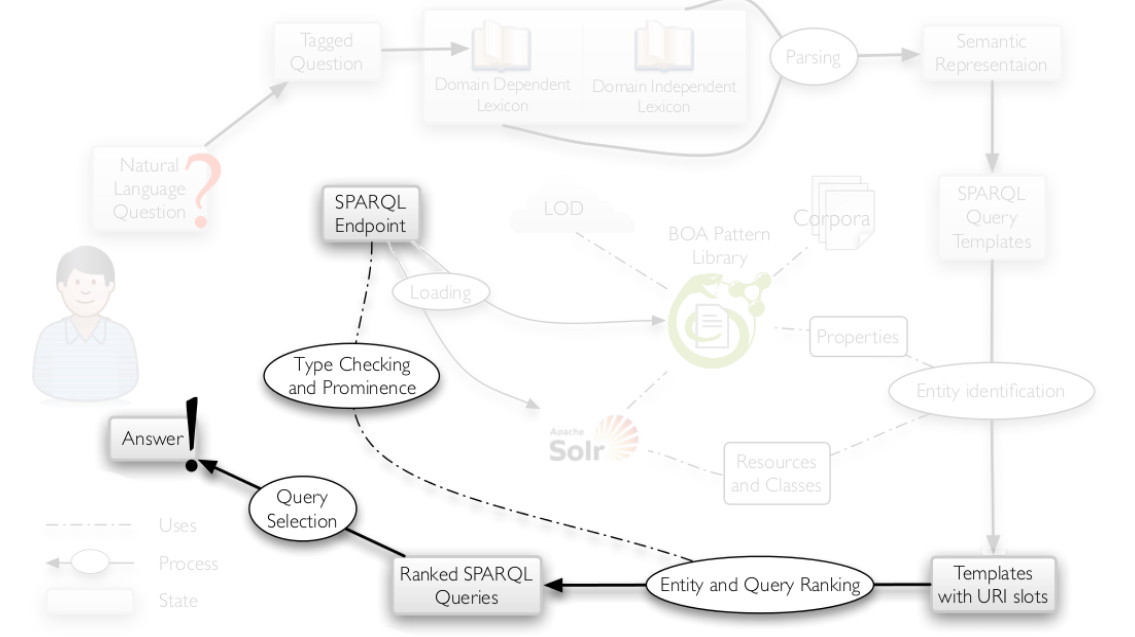
步骤:
- 首先每个entity 根据 string similarity 和 prominence 获得一个打分。
- 一个query模板的分值根据填充slots 的多个entities 的平均打分。
- 检查type 类型。
- 对于全部的查询集和,仅返回打分最高的。
示例:who produced the most films?

TBSL的主要缺点
- 创建的模板未必和知识图谱中的数据建模相契合
- 考虑到数据建模的各种可能性,对应到一个问题的潜在模板数量会非常多,同时手工准备海量模板的代价也非常大。
自动生成模板
QUINT架构
- 能够根据utterance- answer对,根据 依存树自动学习utterance-query模板
- 利用自然语言的组成特点,可以使用从 简单问题中学到的模板来解决 *复杂问题
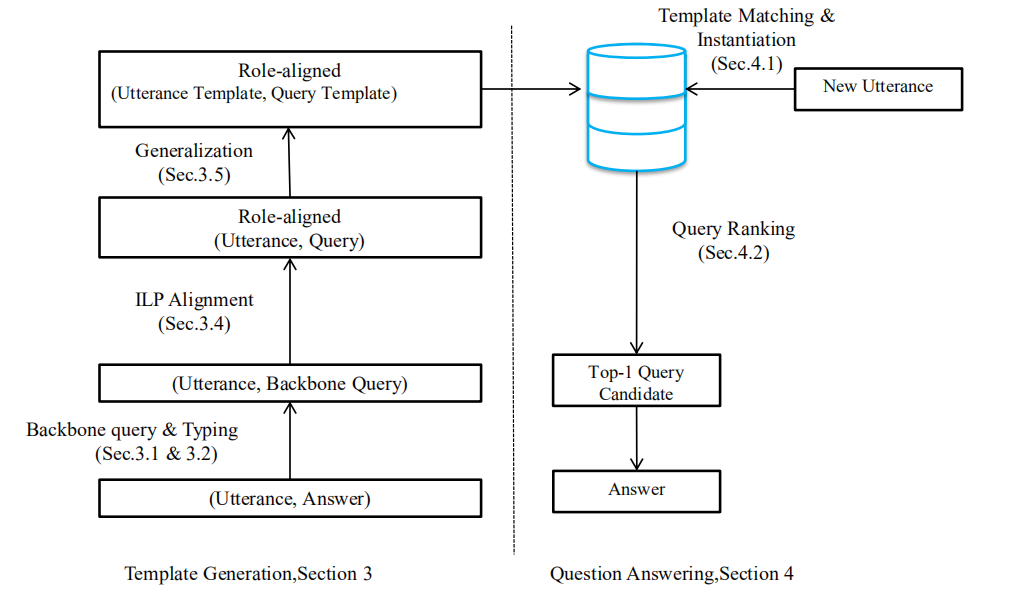
; step1:模板的定义与生成
定义一个三元组的模板:(ut,qt,mt):其中
ut为问题模板
qt为query模板
mt为问题和query映射方法模板
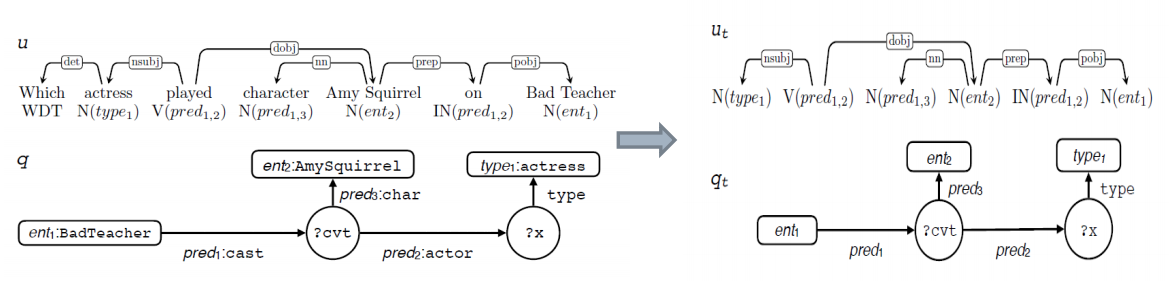
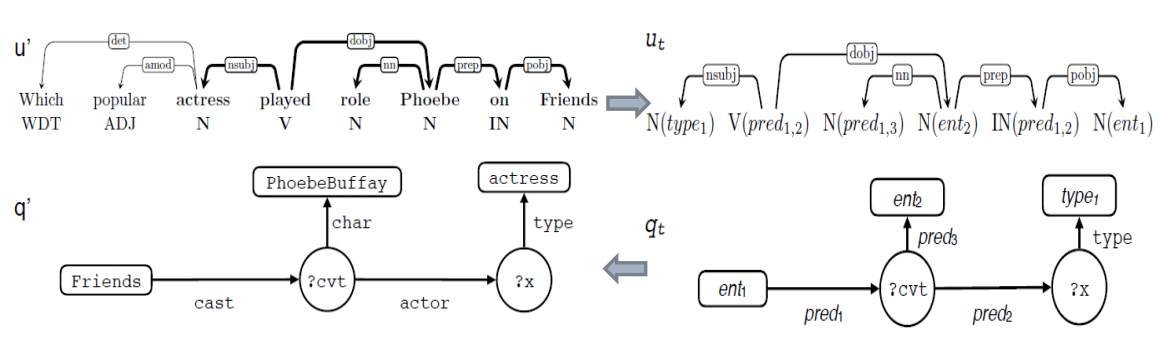
step2:模板的匹配和实例化
- 对于新问题进行依存分析,并使用工具S-MART进行NERL (freebase)
- 去模板库中进行匹配(u’中加粗的黑线与ut,匹配,使用子图同构匹配)
- 再使用词典L对mt, (mt为utterance和query对齐关系)进行实例化
; step3:排序
- 从问题产生多个候选query的原因
- 模板可能匹配多个
- NER L
- 使用Random Forest进行学习两个query对之间的顺序
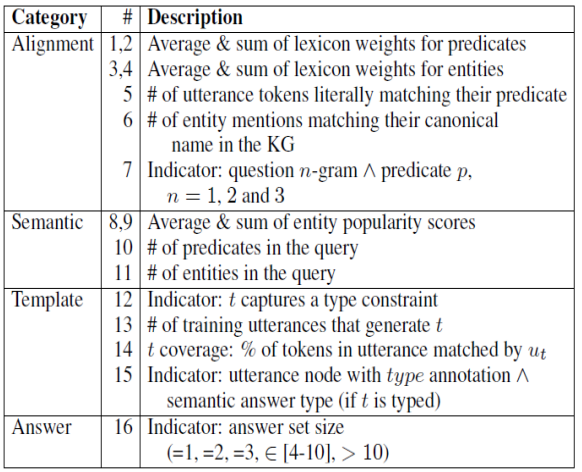
step4:复杂问题处理
; 实验结果
方法的主要贡献点
- 提出了QUINT能够根据utterance-answer pair,使用 依存树自动学习utterance-query模板。模板的学习使用 远程监督的方法。模板支持自动识别问题答案的类型
- 利用自然语言的组成特点,可以使用从简单问题中学到的模板来解决复杂问题(多个predicate)复杂问题解决流程:
- 将问题分解为子句
- 使用模板回答每一个子句
- 结合子句答案获取最终答案
模板方法的优缺点
优点:
- 模板 查询响应速度 快
- 准确率较高,可以回答相对复杂的 复合问题
缺点:
3. 人工定义的模板结构经常 无法与真实的用户问
题进行 匹配。
4. 如果为了尽可能匹配上一个问题的多种不同表述,则需要建立庞大的模板库, 耗时耗力且查询起来效率降低。
参考资料:王昊奋知识图谱教程
Original: https://blog.csdn.net/qq_37953072/article/details/109205404
Author: ling….
Title: 基于模板的知识问答方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/568723/
转载文章受原作者版权保护。转载请注明原作者出处!