

Bag of Visual Words (Bag of Features)
采用k -means 聚类方法对所提取的大量特征进行无监督聚类,将具有相似性较强的特征归入到一个聚类类别里,定义每个聚类的中心即为图像的”单词”,聚类类别的数量即为整个视觉词典的大小。这样,每个 图像就可以由一系列具有代表性的视觉单词来表示, 在得到每类图像的视觉单词袋表示之后,便可以应用这些视觉单词来构造视觉词典,然后对待分类图像进行同样方法的特征提取和描述,最后将这些特征对应到视觉词典库中进行匹配,去寻找每个特征所对应的最相似的视觉单词,得到直方图统计表示,然后应用分类器进行分类。这样就将应用于文档处理的BOW模型思想成功地移植到了图像处理领域。
Steps:
- Feature extraction 特征提取
- Learn “visual vocabulary” 学习”视觉词汇
- Quantize features using visual vocabulary 使用视觉词汇量化特征
- Represent images by frequencies of “visual words” 用”视觉单词”的频率表示图像

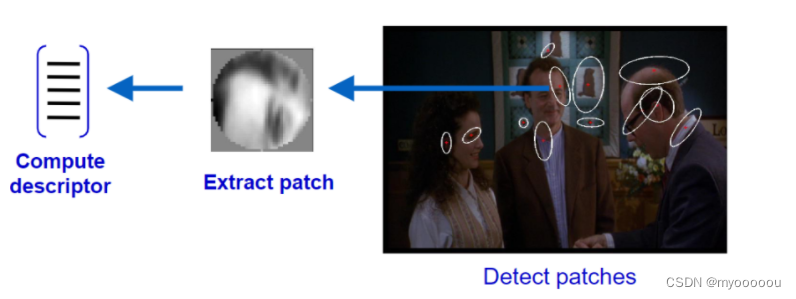
; Feature extraction 局部特征提取
通过分割、密集或随机采集、关键点或稳定区域、 显著区域等方式使图像形成不同的patches,并获得各patches处的特征。
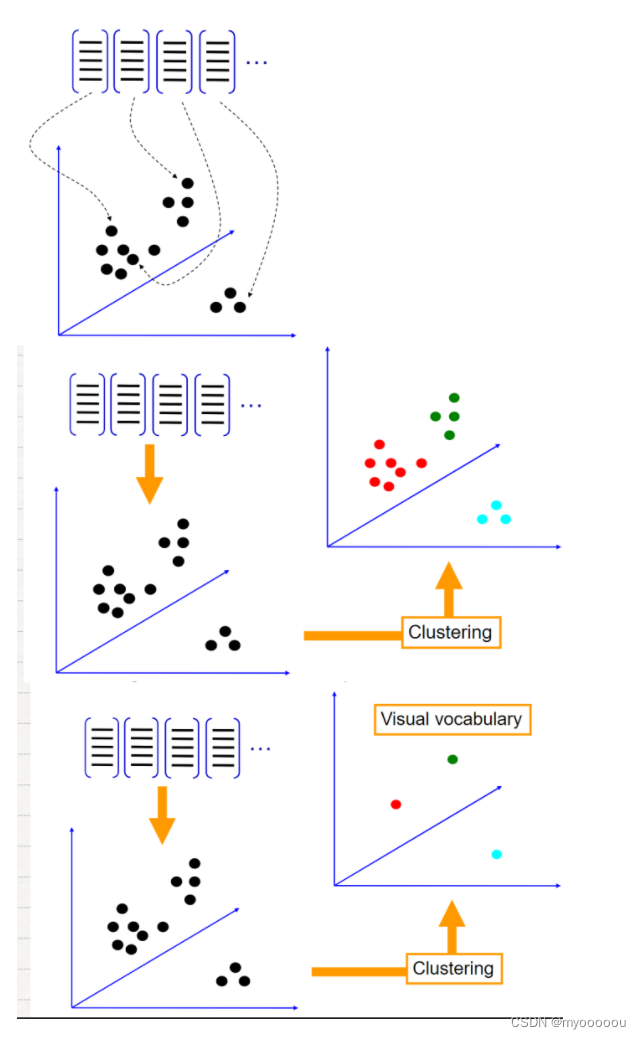
利用SIFT算法,从每类图像中提取视觉词汇,将所有的视觉词汇集合在一起,如下图所示:

Learning the visual vocabulary
利用K-Means算法构造单词表。K-Means算法是一种基于样本间相似性度量的间接聚类方法,此算法以K为参数,把N个对象分为K个簇,以 使簇内具有较高的相似度,而簇间相似度较低。SIFT提取的视觉 词汇向量之间根据距离的远近,可以利用K-Means算法将词义相近 的词汇合并,作为单词表中的基础词汇,假定我们将K设为4,
; Quantize features using visual vocabulary
利用单词表的中词汇表示图像。利用SIFT算法,可以从每幅图像中提取很多个特征点,这些特征点都可以用单词表中的单词近似代替, 通过统计单词表中每个单词在图像中出现的次数,可以将图像表示成为一个K=4维数值向量。
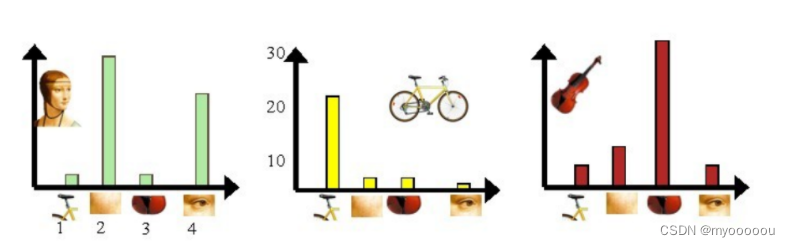
Represent images by frequencies of “visual words”
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:a25ae252-3617-49be-9cb6-b956ccc1e572
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:382687bc-8a04-471e-a2f2-9b28b105a813
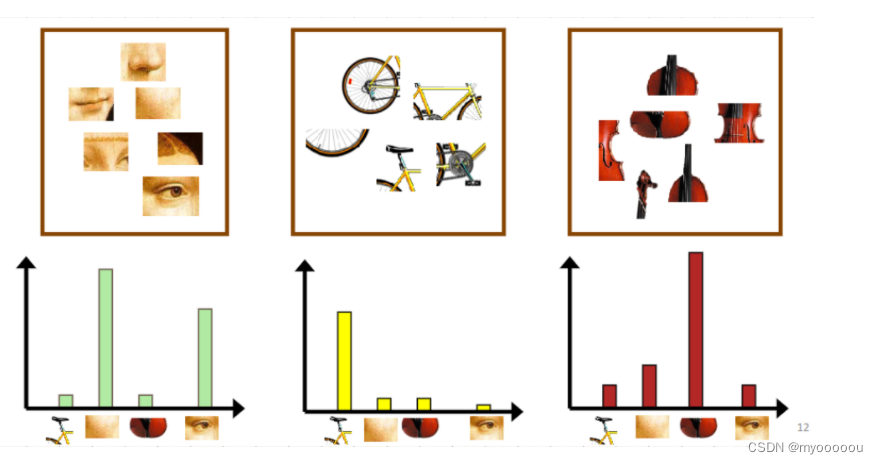
人脸: [3,30,3,20]
自行车:[20,3,3,2]
吉他: [8,12,32,7]
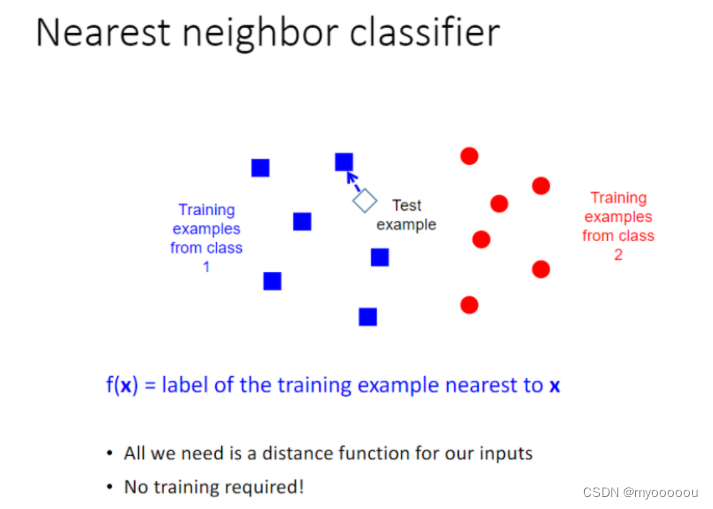
; Multi-Layer Neural Networks
Original: https://blog.csdn.net/myooooou/article/details/126769164
Author: myooooou
Title: week5 Bag of Visual Words (Bag of Features)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563223/
转载文章受原作者版权保护。转载请注明原作者出处!