

1.定义类实现 Partitioner 接口,重写 partition()方法
package com.kafka.producer;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* 1. 实现接口 Partitioner
* 2. 实现 3 个方法:partition,close,configure
* 3. 编写 partition 方法,返回分区号
*/
public class MyPartitioner implements Partitioner {
/*** 返回信息对应的分区
* @param topic 主题
* @param key 消息的 key
* @param keyBytes 消息的 key 序列化后的字节数组
* @param value 消息的 value
* @param valueBytes 消息的 value 序列化后的字节数组
* @param cluster 集群元数据可以查看分区信息
* @return
*/
@Override public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { // 获取消息 String msgValue = value.toString(); // 创建 partition int partition; // 判断消息是否包含 Kafka if (msgValue.contains("Kafka")){ partition = 0; }else { partition = 1; } // 返回分区号 return partition; } // 关闭资源 @Override public void close() { } // 配置方法 @Override public void configure(Map configs) { }}
undefined
2.使用分区器的方法,在生产者的配置中添加分区器参数。
复制之前写的CustomProducerCallBack类,改成CustomProducerCallBackPartition
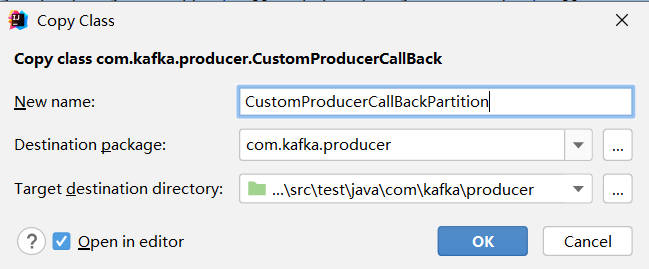

红色代码为添加部分
package com.kafka.producer; import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties; public class CustomProducerCallBackPartition { public static void main(String[] args) { //配置 Properties properties = new Properties(); //连接集群 properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092"); //指定对应的key和value序列化类型 properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.kafka.producer.MyPartitioner"); //创建Kafka生产者对象 KafkaProducerkafkaProducer = new KafkaProducer<>(properties); //发送数据 for (int i = 0; i < 5; i++) { kafkaProducer.send(new ProducerRecord<>("first", "Kafka" + i), new Callback() { @Override public void onCompletion(RecordMetadata metadata, Exception exception) { if (exception == null) { System.out.println("主题:" + metadata.topic() + " 分区:" + metadata.partition()); } } }); } //关闭资源 kafkaProducer.close(); } } ,>
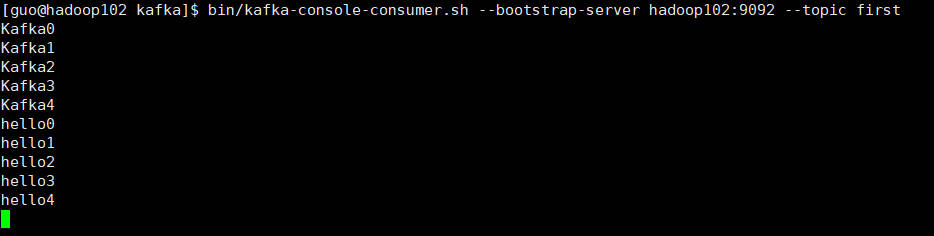
3.在 hadoop102 上开启 Kafka 消费者。
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first

4.在IDEA运行代码
查看hadoop102信息


同时IDEA打印信息,指定分区为0,因为消息包含Kafka
修改发送的信息为hello

运行代码
查看hadoop102信息
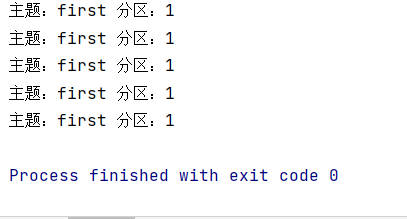
同时IDEA打印信息,指定分区为1,因为消息不包含Kafka
Original: https://www.cnblogs.com/hz-Master/p/16273069.html
Author: hz15968199950
Title: Kafka自定义分区器
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/563048/
转载文章受原作者版权保护。转载请注明原作者出处!