

测试环境
CDH:Cloudera Express 6.1.0
Hadoop:3.0.0-cdh6.1.0
Hive:2.1.1-cdh6.1.0
namenode:1个
datanode:3个
原始文件大小:243.1MB
测试方法
利用hadoop进行测试,利用load data将文件导入到hive表中。
LOAD DATA [LOCAL] INPATH 'file_path' [OVERWRITE] INTO TABLE table_name
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:0a0c0ac8-ddc5-45fe-a231-302d1a6dc05a
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:068a85c1-8a7a-4848-b80b-576f851a8b1e
--创建表CREATE TABLE test.text_default(
id int COMMENT '主键id',
words1 string COMMENT '歌词1',
words2 string COMMENT '歌词2',
words3 string COMMENT '歌词3',
words4 string COMMENT '歌词4',
words5 string COMMENT '歌词5',
words6 string COMMENT '歌词6',
words7 string COMMENT '歌词7',
words8 string COMMENT '歌词8',
words9 string COMMENT '歌词9',
words10 string COMMENT '歌词10',
words11 string COMMENT '歌词11')
COMMENT 'textfile的default算法表'STORED AS textfile;--导入数据
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.DefaultCodec;
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true;
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
insert into test.text_default
select * from ods_table;
–校验数据量
select count(1) from text_default;
测试结果
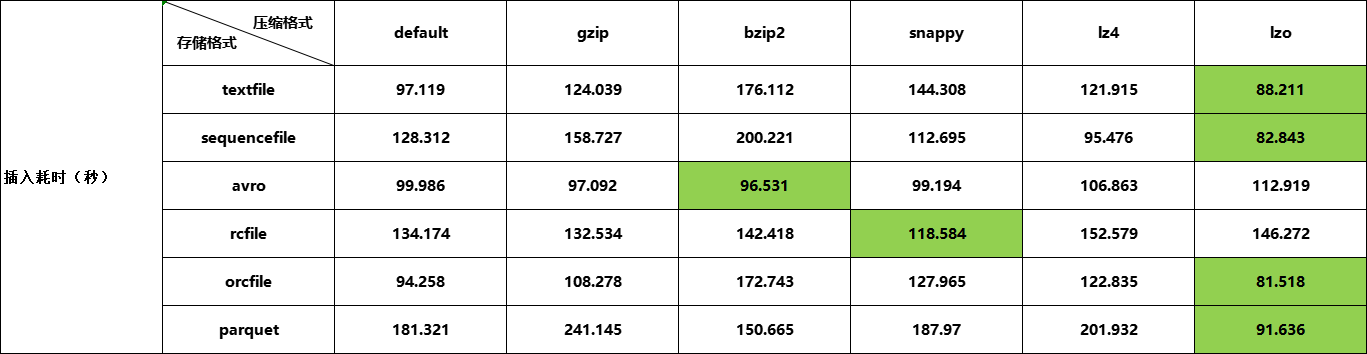

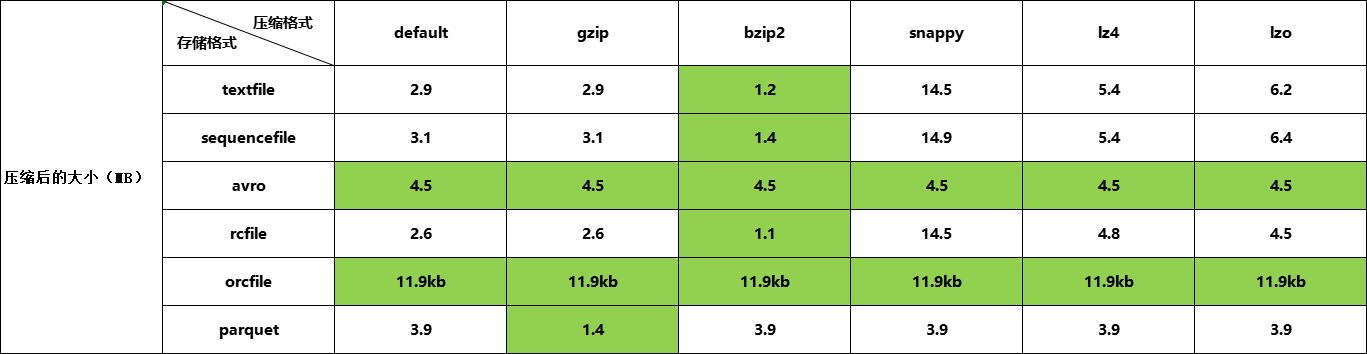
总结
测试文件格式及压缩算法在hive中的表现,小数据量并不能体现出问题及它们的特征。
Original: https://www.cnblogs.com/tangshanqun/p/16715589.html
Author: 踩坑臭皮匠
Title: 记录一次不靠谱的hadoop文件格式及压缩研发的测试
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/562044/
转载文章受原作者版权保护。转载请注明原作者出处!