

2008 年,”大数据” 一词在《大数据时代》中被首次提出,距今已有整整 14 个年头。在这 14 年中,许多人亲眼见证了数据的力量,以及目睹它如何改变世界。大部分企业的决策者都明白了一个道理:数据才是企业中最有价值的商品,它可以被人为选择成就还是破坏业务。
然而,自流行词 “大数据” 出现的 14 年后,如何获得更高质量的数据,以及更智能的数据管理,帮助企业做出明智和及时的决策,仍然是许多企业的 “疑难杂症”。每个人的嘴里都在谈论数据治理和数据管理,却没有人真正知道该怎么办。
幸运的是,一种帮助企业提升数据分析质量和效率的方法论正在兴起,它就是 DataOps。基于 DataOps,企业数据中台可以实现数据利用率最大化,加快生产周期,及针对结果优化的数据管道。
今天,我们将展开说说 DataOps,以及为什么它对于每一个想要真正实现数据赋能业务的企业都很重要。
一、DataOps 是什么
DataOps(Data Operations)并不是一个新的概念,根据维基百科的说明,早在 2014 年就被 IBM(Lenny Liebmann)提出,在 2017 年得到大范围关注,并在 2018 年正式被纳入 Gartner 的数据管理技术成熟度曲线当中。
今年,中国信通院正式牵头启动了 DataOps 的标准建设工作,以此为基础推动我国大数据产业的多元化发展,为企业经营决策提供数据支持。
同时需注意的一点,DataOps 不是一个工具或产品,可以理解成一种「方法论,或者最佳实践」,类似软件开发中的「敏捷方法」。不能以功能的视角去看待 DataOps,而是以「我应该如何做」的视角来看待此问题。
DataOps 的目标是提供工具、过程以及结构化的方式来应对快速增长的数据,对企业内的数据团队赋能,能够使企业内的数据团队更高效、高质量的完成数据分析,它强调交流、协作、多系统集成以及自动化流程,并配套具备对应的度量方式。
二、DataOps 的涵盖内容
下图为标准的 DataOps 涵盖的内容,主要包括数据技术、数据管道、数据处理 3 个方面,最终为商业用户输出价值。


原图出自:https://www.eckerson.com/articles/diving-into-dataops-the-underbelly-of-modern-data-pipelines
三、数栈 DataOps 实践
从发展上看,自 2018 年被纳入 Gartner 的数据管理技术成熟度曲线中以来,DataOps 的热度逐年上升;从实践上看,欧美企业对于 DataOps 的探索和发展要早于中国,DataOps 在我国仍处于一个从萌芽期到爆发期的关键过渡阶段。
数栈依据多年经验,通过敏锐的嗅觉快人一步开始探索 DataOps 的实践,总结出 DataOps 的 3 个层次 + 4 个核心能力,助力企业加快数据洞察的步伐,具体分析如下:
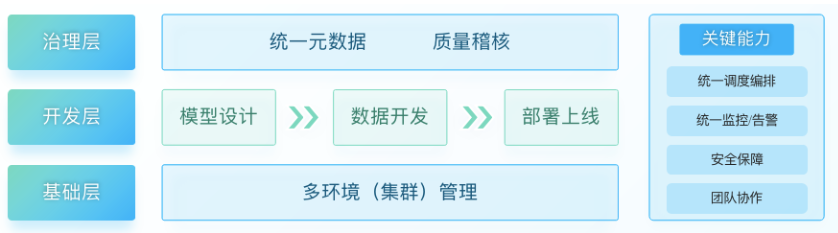
1、基础层:多环境(集群)管理
在基础层,数栈支持多环境多集群管理,支持一套统一的平台来对接多套不同规模、不同类型的集群,支持 Cloudera Hadoop、华为 FusionInsight、华为 MRS、星环 Inceptor、Greenplum、GaussDB、MySQL 等各类数据库作为计算引擎,提供统一的开发与应用体验,具备跨云部署以及对跨云 EMR 的兼容能力,面向多云场景提供统一开发、统一管控能力,用户可在不同的集群环境中(同类型引擎)实现代码及相关资源的无缝发布。

2、开发层:数据开发全链路
根据数据开发的基本流程,分为模型设计、数据开发、部署和质量审核四个步骤。日常用户的主要操作包括以下四个步骤,具体介绍如下:
[En]
According to the basic process of data development, it is divided into four steps: model design, data development, deployment and quality audit. The main operations of daily users are in these four steps, which are described in detail below:
1)模型设计
按照标准的数据中心建设模式,分为标准制定和模型设计两个部分。标准的制定和模型的在线设计可以在数据栈线上进行,不需要在线下单独维护数据标准文件、数据模型文件等内容。普通开发者需要将模型设计提交给管理员审核。允许模型在线/审核后更改。
[En]
According to the standard data center construction mode, it is divided into two parts: “setting standards” and “model design”. The formulation of standards and the online design of the model can be carried out online in the data stack, and there is no need to maintain separate data standard documents, data model documents and other contents offline. Ordinary developers need to submit the model design to the administrator for review. The model is allowed to be online / changed after review.
模型设计和标准制定可细分为六个单元,如下图所示:
[En]
Model design and standard setting can be subdivided into six units, as shown in the following figure:

其中,仓库级、标准设计、模型元素属于表级定义,数据同义词、词根、代码表属于字段级定义,数据堆栈以生产的形式对六个单元进行梳理组合。方便企业建立自己的数据治理体系。
[En]
Among them, the warehouse level, standard design and model elements belong to the table level definition, the data thesaurus, word root and code table belong to the field level definition, and the data stack combs and combines the six units in the form of production. it is convenient for enterprises to establish their own data governance system.
3)数据开发
在数据开发环节,通过丰富的任务类型、代码版本管理、责任人机制等,实现了数据开发和数据分析的可持续发展。具体内容如下:
[En]
In the data development link, the sustainable development of data development and data analysis is realized through rich task types, code version management, responsible person mechanism and so on. The specific contents are as follows:
● 20 + 种丰富的任务类型
支持离线同步、实时同步、离线计算、实时计算、关系数据库计算、管理节点、脚本任务等五大类、20种不同的任务类型。用户可以通过数据堆栈统一管理企业内各种离线、实时的数据采集处理流程,实现一体化的数据开发平台。
[En]
Support offline synchronization, real-time synchronization, offline computing, real-time computing, relational database computing, management nodes, script tasks and other five categories, 20 different task types. Users can uniformly manage all kinds of offline and real-time processing processes of data acquisition and processing in the enterprise by the data stack to realize an integrated data development platform.
● 数据测试
支持样本数据上传、模拟测试、数据逻辑验证和测试。
[En]
Support uploading sample data, simulation testing, data logic verification and testing.

● 代码预检查
在提交代码之前做一次“预检查”,以防止启动后出现问题。
[En]
Do a “pre-check” before submitting the code to prevent problems after launch.

未来数栈将在系统规则的基础上,支持自定义校验规则,用户可基于数栈暴露的接口进行自定义开发,例如代码 JOIN 次数限制、分区表禁止全表扫描、禁止跨数仓层级访问等规则,可通过自定义开发 Jar 包的方式进行自定义规则校验。
3)部署上线
用户开发完成后,需要将代码从测试环境发布到生产环境,平台需要支持快速任务发布,并将开发/测试代码及其依赖资源快速发布到生产环境。
[En]
After the user completes the development, the user needs to release the code from the test environment to the production environment, and the platform needs to support rapid task release, and quickly release the development / test code and its dependent resources to the production environment.
堆栈的部署和发布有两种模式:
[En]
There are two modes for deployment and release of stacks:
● 双项目模式
您可以将在一个项目中开发的任务发布到另一个项目。双项目模式可以在代码层和底层数据层面实现良好的隔离,保证数据安全。
[En]
You can publish tasks developed in one project to another. The dual-project model can achieve good isolation at the code layer and the underlying data level, and ensure data security.
● 导入导出式发布
对于物理环境隔离的场景,可将开发的任务代码、依赖的 UDF 函数、Jar 包等关联资源一起导出为 zip 包,并在生产环境执行一键导入。
除了代码发布,它还支持版本管理、版本比较、代码快速回滚。该堆栈可以记录每次提交和发布的任务代码和运行参数,并标记每个版本的更改,帮助定位代码问题,并支持一键版本回滚。
[En]
In addition to code release, it also supports version management, version comparison, and quick rollback of code. The stack can record the task code and running parameters of each submission and release, and mark the changes of each version, help locate code problems, and support one-click version rollback.

3) 治理层:统一元数据 质量稽核
[TencentCloudSDKException] code:LimitExceeded.LimitedAccessFrequency message:Reduce the frequency requestId:68c9eed5-e541-428c-aaa5-02d3bf9b4528
[En]
The governance layer mainly includes two capabilities: unified metadata and quality audit:
统一元数据
支持将数栈平台内的各类元数据汇聚、展示、打通、分析等,包括:元数据基础属性、离线表 / 任务、实时表 / 任务、API、标签、指标等各类元数据。
● 全域血缘打通
根据数据在中台内的采集、流转、对外服务等各环节的处理方式,自动建立全平台的血缘关系,基于核心的智能化 SQL 血缘解析能力,实现平台内跨应用的血缘打通,可视化展示数据的流转影响链路。
● 资产分析
支持资产版本变更记录对比、数据输出分析、使用情况分析、质量分析等统计内容。
[En]
It can support statistical contents such as asset version change record / comparison, data output analysis, usage analysis, quality analysis and so on.

质量稽核
支持数据质量检查,帮助企业及时发现数据问题。通过规则前配置、规则中验证、分析后报告的流程方式,对数据的完整性、准确性、规范性、唯一性、一致性进行多维度评估,确保企业数据优质服务。支持规则配置、任务查询、实时验证等。
[En]
Support the quality check of the data to help enterprises find data problems in time. Through the flow way of pre-rule configuration, in-process rule verification and post-analysis report, multi-dimensional evaluation of data integrity, accuracy, standardization, uniqueness and consistency is carried out to ensure enterprise data quality service. support rule configuration, task query, real-time verification and so on.

4) 关键能力
数栈 DataOps 包括以下四大能力:
统一调度编排
数栈内置分布式调度引擎 Taier,支持百万级别复杂依赖调度。调度平台在数栈内为底层通用能力,离线、实时、质量校验、标签、指标等各任务均使用统一的调度能力。
在此基础上,各产品模块可以灵活地相互依赖,如离线数据提取+计算等场景,自动触发标签任务的计算。
[En]
On this basis, each product module can be flexibly interdependent, such as scenarios such as offline data extraction + calculation, automatically triggering the calculation of label tasks.

统一监控 / 告警
数栈支持统一的告警通道,不同的产品模块内可能都会使用告警能力,例如离线任务突破基线、实时任务失败、API 调用失败、质量校验未通过等。针对某个告警通道仅需开发一次,即可再各个产品内使用此告警方式,例如短信、邮件,企业微信、钉钉、电话告警等。

模型设计
在数据安全层面,数据堆栈可以分为以下几个方面:
[En]
At the level of data security, data stack can be divided into the following aspects:
● 系统安全
通过服务高可用部署、数据定期备份等策略保障服务安全。登录密码可根据长度、复杂程度、强制定期更换等支持多种安全策略。密码为加密传输+加密存储。
[En]
Service security is ensured through strategies such as high-availability deployment of services and regular backup of data. The login password can support a variety of security policies according to length, complexity, mandatory periodic replacement, and so on. The password is encrypted transmission + encrypted storage.
● 数据安全
底层可集成 LDAP+Ranger+Kerberos 数据安全组件。在 Hadoop 体系内可支持库、表、列、行级数据权限控制。在服务安全方面,可支持行、列权限控制、多种认证方式、国密加密等特性,保障用户数据安全。
● 安全审计
自动记录用户的关键操作行为和数据访问行为,管理员可以对用户的操作行为进行审计,检查异常行为。
[En]
Automatically record the key operation behavior and data access behavior of the user, and the administrator can audit the user operation behavior and check for abnormal behavior.

团队协作
● 责任人机制
每个任务、表、标签、API、指标、告警配置等「资源」均建立责任人机制,当发生异常需配合排查时,可快速获取相关负责人,便于线下沟通。
● 一键交接
当发生人员变动时,支持一键交接,可自动分批替换当前负责人的所有资源,方便工作交接。
[En]
When there is a personnel change, one-click handover is supported, and all the resources of the current person in charge can be replaced automatically in batches to facilitate work handover.
● 用户组
当开发团队规模较大,需要再次细分时,可以通过用户组的方式进行管理,如按用户组批量添加用户、分配功能权限/数据权限、发送告警等场景,无需重复操作。
[En]
When the development team is large and needs to be subdivided again, it can be managed in the way of user groups, such as adding users in batches by user groups, assigning functional permissions / data permissions, sending alarms and other scenarios without repeated operations.

四、结语
随着时间的推移,数据的数量、频率、多样性都在增加,在一个万物皆可被度量的时代,数据积累的速度超过大部分企业跟上其脚步的速度。这也意味着能够帮助企业完成自动化日常任务,提高数据质量,促进不同团队之间的协作,带来更准确的洞察和分析,以及助力企业进入敏捷、自动化和加速的数据供应链环境的 DataOps,未来将会在企业的数智化蜕变中,发挥不可小觑的作用。
企业实现 DataOps 有赖于一系列广泛的技术和流程,数栈目前已经在采集、加工、治理的核心流程上,通过版本控制、团队协同、一键发布、质量稽核、数据安全等能力实践了基本的 DataOps 理念,但依然有很多方面亟需改善,例如:利用 AI/ML 技术降低人为操作的成本与失误、对研发效能增加更多的的度量指标(Metric),以数据化的方式来衡量研发效能的增减等方面,均需要数栈团队,以及全行业一起努力。
袋鼠云开源框架钉钉技术交流qun(30537511),欢迎对大数据开源项目有兴趣的同学加入交流最新技术信息,开源项目库地址:https://github.com/DTStack
Original: https://blog.51cto.com/u_15137832/5521549
Author: 数栈DTinsight
Title: DataOps 不是工具,而是帮助企业实现数据价值的最佳实践
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/508467/
转载文章受原作者版权保护。转载请注明原作者出处!