

课件获取:关注公众号”ChunJun”,后台私信 “课件” 获得直播课件
视频回放:点击这里
ChengYing开源项目地址:github 丨 gitee 喜欢我们的项目给我们点个__ STAR!STAR!!STAR!!!(重要的事情说三遍)__
技术交流钉钉 qun:30537511
本期我们带大家回顾一下六六同学的直播分享《ChunJun数据传输模块介绍》。
一、ChunJun数据类型转换
1、类型转换解决的问题
大家一听到「ChunJun数据类型转换」这个概念,可能会联想到上下游之间进行数据交互时会涉及到的隐式转换。如果上游和下游数据类型一致,则不需要对数据进行任何干预,直接进行下发即可。
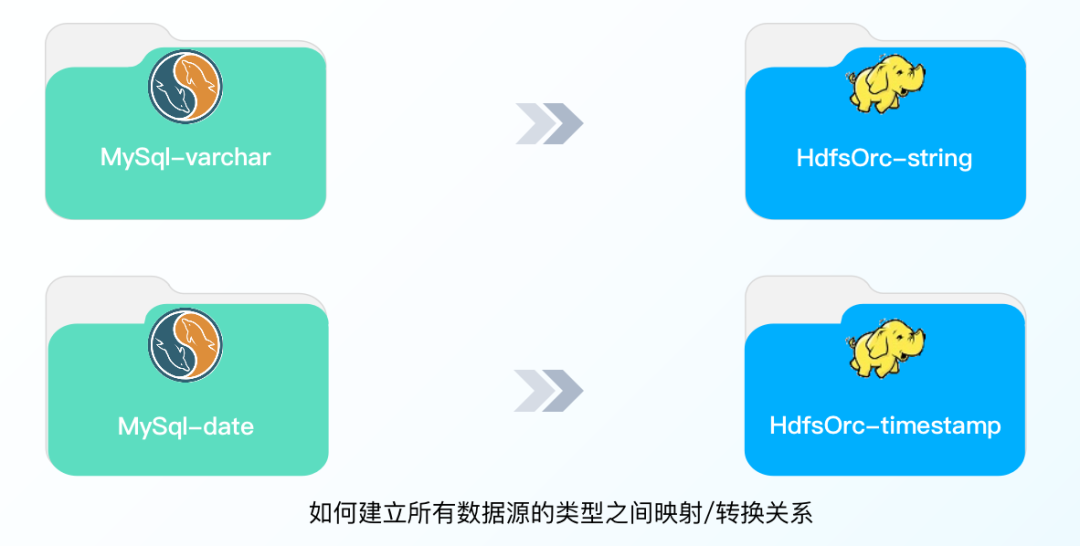
但是大多数情况下会涉及到两个问题,一是上游的数据源类型和下游的数据源类型不一致。比如MySql的varchar类型要写到HdfsOrc文件里的string类型的话,在上游的表示是varchar,在下游的表示是string,但实际上中间段java的类型都是string。
另外一种情况则是,上下游之间不止数据源类型不一样,数据类型也不一样,除了要做类型的映射之外,还需要对数据本身进行改动。比如,MySql的date类型要写到下游timestamp类型,我们需要进行的操作是把date中的毫秒级的时间戳拿出来,转换成timestamp的类型,再往下游去写。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:5a40f76d-0d0b-4269-a4ad-adad1b314ecb
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:90462711-2130-4065-969b-ce42a2d9c1af

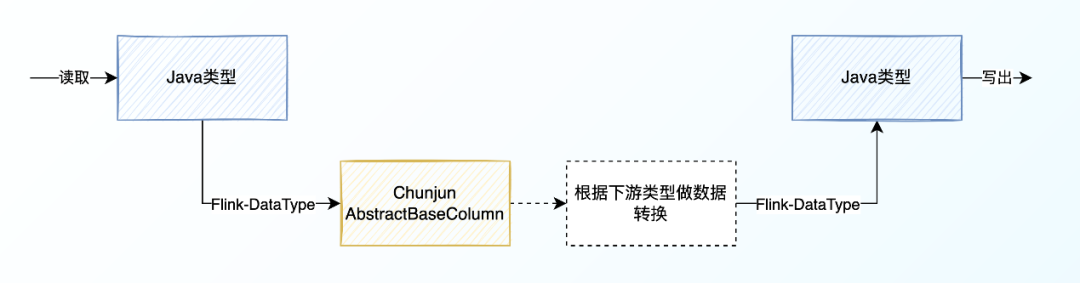
2、类型映射概览
• client端:在Factory类中通过RawConverter类建立映射关系
• source端:将数据封装成AbstractBaseColumn
• sink端:通过AbstractBaseColumn中的转换方法将数据转换成对应类型
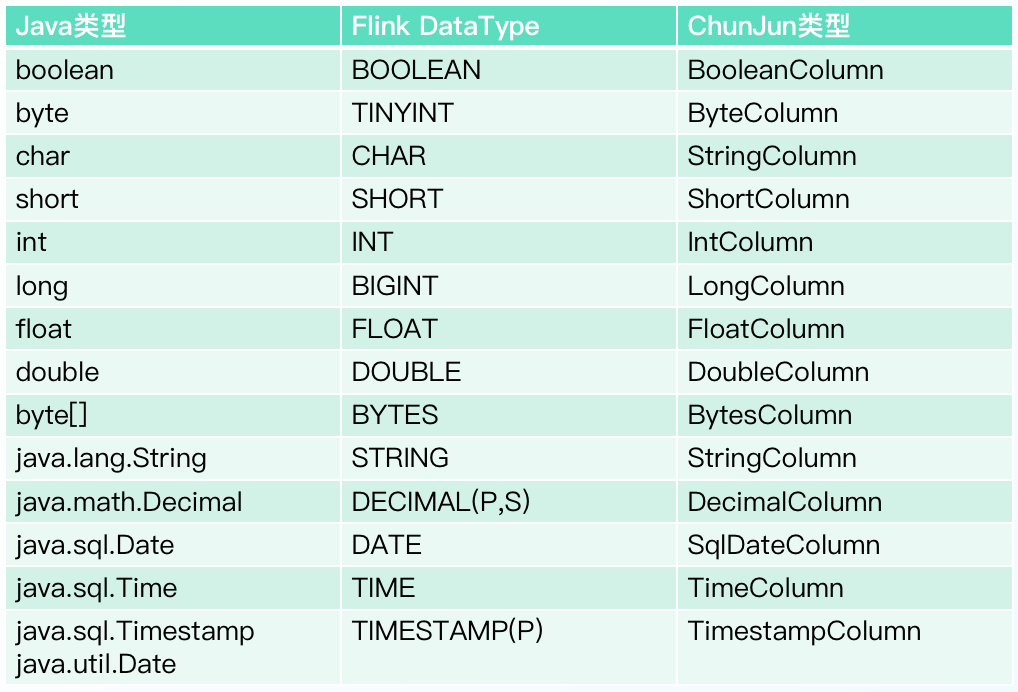
ChunJun目前支持的数据类型映射关系图如下:
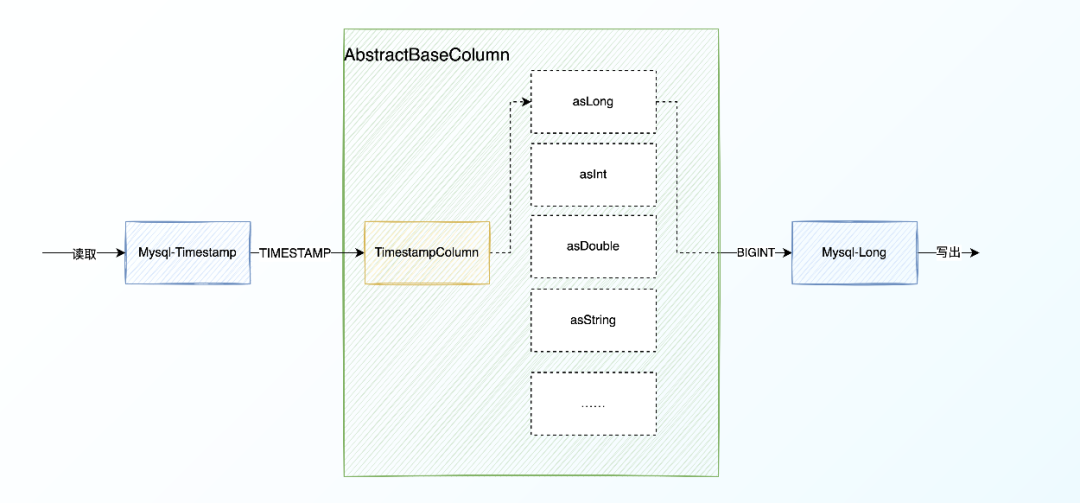
3、类型映射详解
以Timestamp为例,如果要写入到Long类型的话,根据上文展示的ChunJun数据类型映射关系图,最终映射到TimestampColumn中,具体流程如下图:
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:1ab47fe2-2b0c-4084-9640-799f78a65649
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:ce2908ec-f8e3-4583-af0d-d554e7eba229

as方法就是数据类型转换的方法。使用这个机制之后,在下游可以只关心需要的数据类型,增加开发效率。
二、ChunJun数据传输过程
了解完ChunJun数据类型转换后,我们来为大家分享ChunJun的数据传输过程。
1、上下游数据传输方式
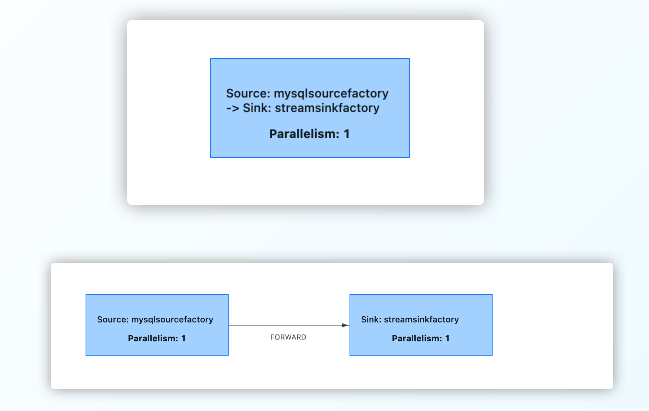
在ChunJun中进行同步作业,有两种情况,一是算子链打开的情况,上游的Source和下游的Sink会被合并成一个task,有同一个线程去做调度;二是把算子链进行关闭,Source和Sink各自形成一个task,也有各自的线程去进行调度。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b03d31aa-f45f-4c39-9c08-ad267c11a6dd
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:46c25d85-9320-4117-875d-5f0c6e3d2b9a
● 对象重用
· 上下游数据传输使用方法调用的形式,将上游产生的数据的对象引用直接交给下游
· 上下游算子需要形成算子链,作业开启对象重用
· env.getConfig().enableObjectReuse();
● 拷贝
· 上游传输给下游的数据,需要经过一次深拷贝
· 上下游算子需要形成算子链
算子链的好处是可以减少序列化的操作,那么为什么我们还要引入序列化呢?因为ChunJun的特殊性。ChunJun同步作业的话,只有上下游两个算子,且都对接了正式的数据源,读写的时候会导致线程堵塞。因此上限由网络io决定,如果断开算子链,cpu会在一端线程阻塞的时候切换到另外一端。在序列化的性能较高时,线程上下文切换带来的性能下降完全可以被弥补。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:d6438826-d1f0-4df2-95fe-6cdb938c29aa
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:d3b7724f-c50e-42ea-9fc2-4ea6c60fd564
● 序列化
· 上下游数据传输依赖于网络传输。上游数据进行序列化成byte数组后进行网络传输,下游收到数据后需要进行反序列化
· 上下游之间不形成算子链
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:16a450c9-ff17-4a65-a99a-3dcdb8c3ba07
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:cd91157a-7a17-4801-8243-bd4ff8993126
• 序列化和反序列化在什么时候发生?
• Flink支持哪些序列化?
• 序列化是怎么做的?
• 怎么找到适合的序列化方式?
• 如何实现自定义的序列化?
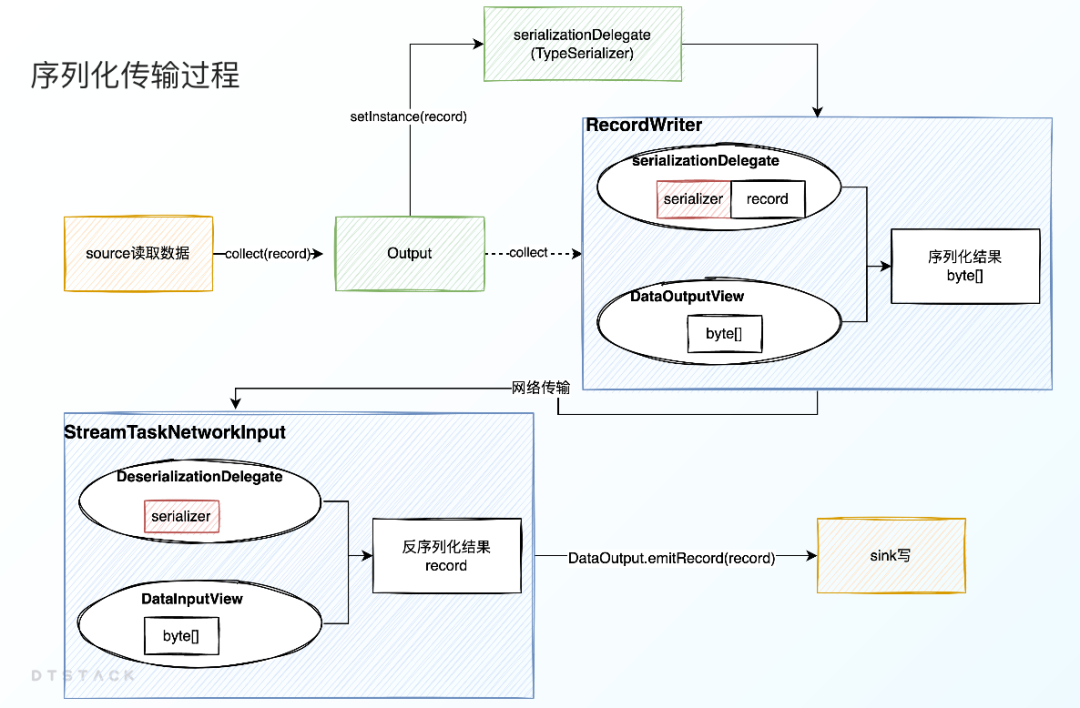
2、序列化传输过程
下图是ChunJun在进行序列化操作时的数据传输链路图:
3、DataOutView

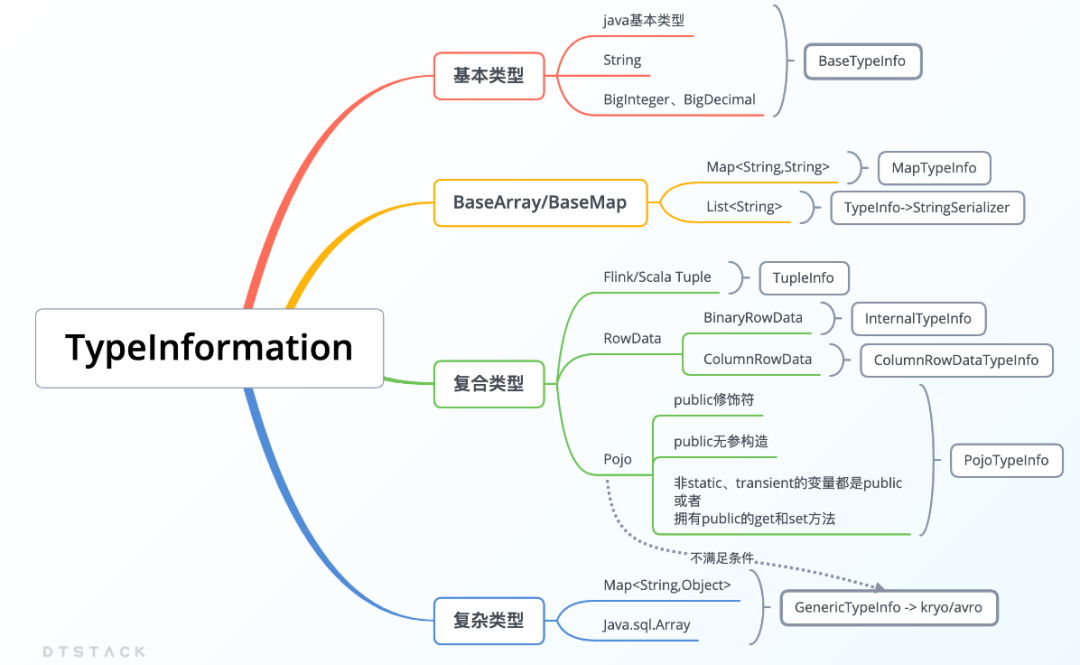
4、TypeInformation介绍
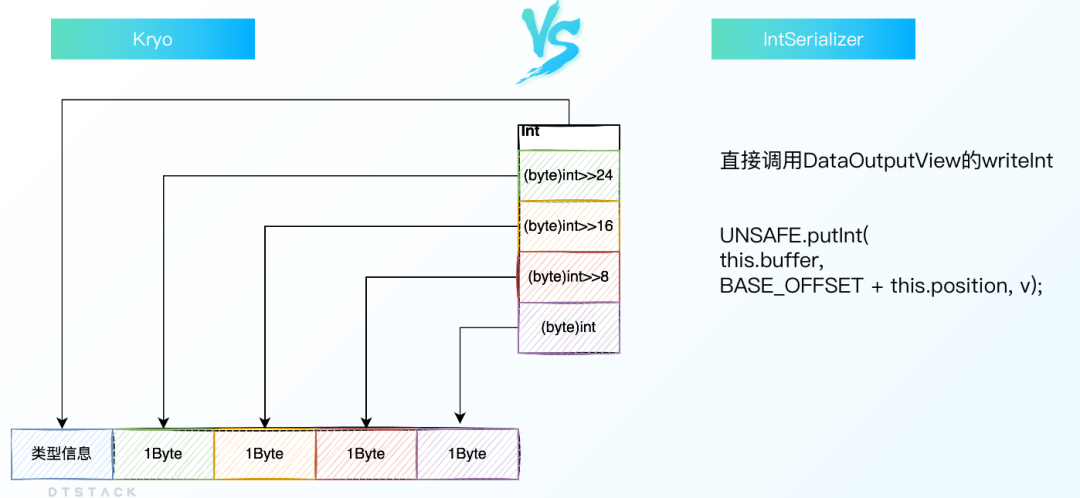
5、kryo序列化&BaseSerializer
同样是序列化一个int对象,对kryo来说,首先需要知道它的类型,然后从高位到低位依次去写入。
DataOutputView则是直接调用一个writeInt的方法,写一句关键代码即可:
UNSAFE.putInt(
this.buffer,
BASE_OFFSET + this.position, v);
三、ChunJun序列化实现
1、ColumnRowData序列化过程
ColumnRowData序列化过程采取标志位+实际数据的方式,具体流程如下图:
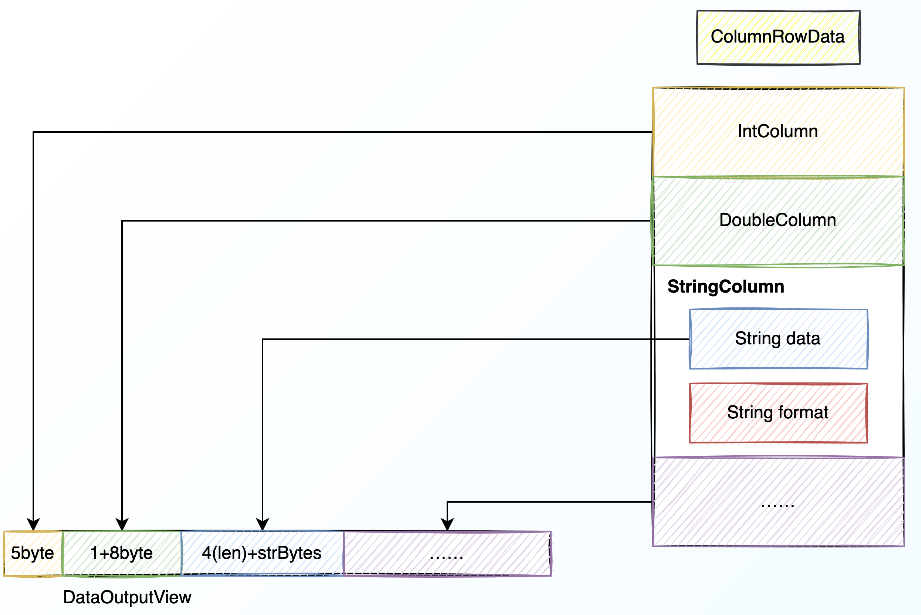
相对于kryo的序列化来说:
· 实现了更密集的存储
· 兼容null值
· 减少了不必要的数据传输
2、BinaryRowData结构
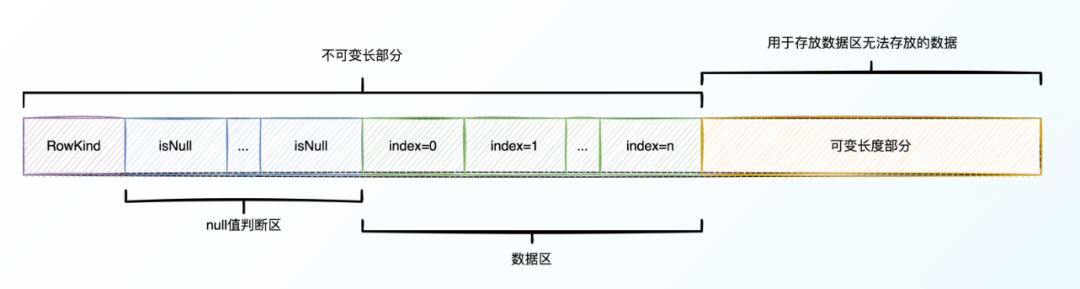
因为数据区一格只占8个字节,且每个index只能占到一位,所以肯定存在一些没法存储在8字节范围之内的数据,可变长度部分就是用来存放数据区无法存放的数据。
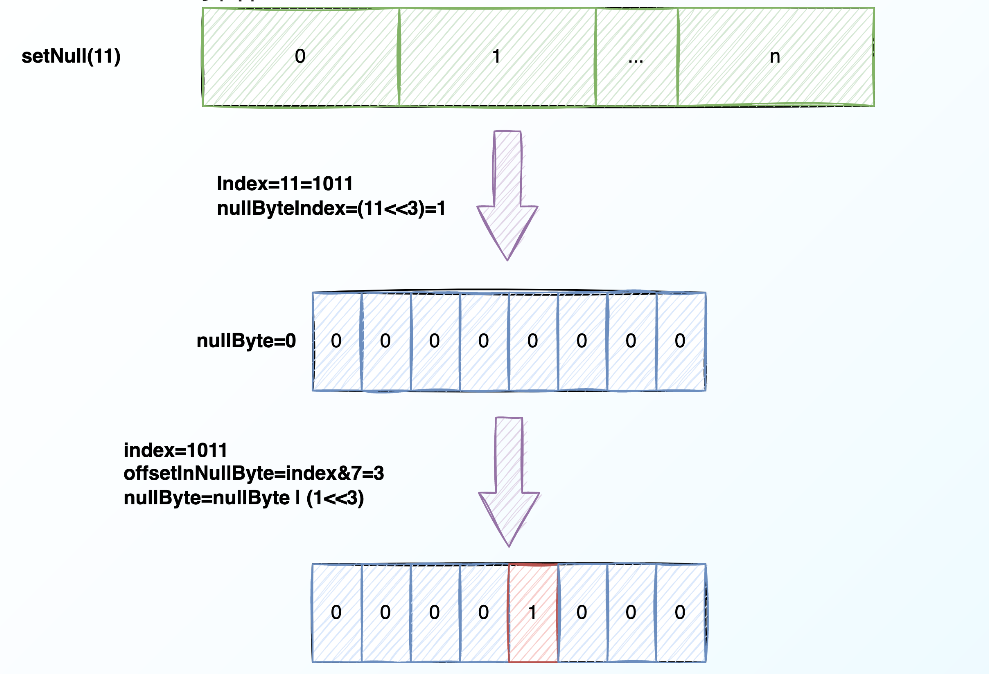
3、BinaryRowData-setNull操作
看到上文的null值判断区,有些同学可能会好奇这是什么,又是怎么进行操作的。下图将对一个下标为11的数据去做setnull操作,进行简单介绍:
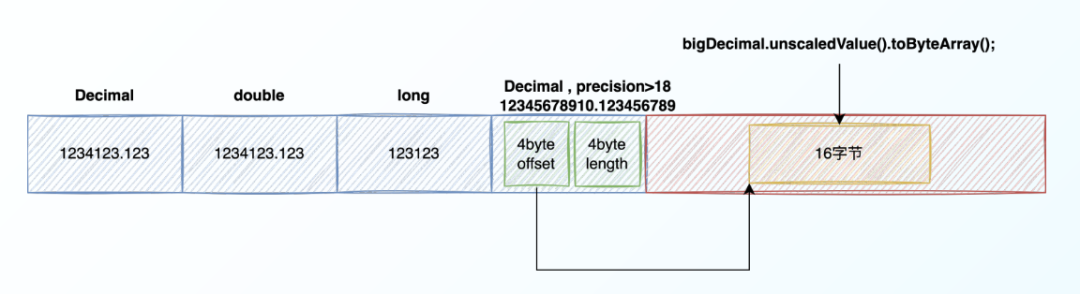
4、BinaryRowData数据存储方式
Original: https://www.cnblogs.com/DTinsight/p/16619048.html
Author: 数栈DTinsight
Title: 开源交流丨批流一体数据集成框架ChunJun数据传输模块详解分享
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/561785/
转载文章受原作者版权保护。转载请注明原作者出处!