

知识点3.1.1 文本向量化和语言模型的概念
分词是中文文本分析的基础,但是计算机无法将分词的结果直接用于后续的统计建模,因此需要对文本进行向量化处理
文本向量化:将文本表示成一系列能够表达语义的数值化向量
语言模型:对于任意一个词序列,计算出其可能是一个句子(通顺且有意义)的概率
知识点3.1.2 词袋模型
- 最基础的以词为基本单元的文本向量化方法
- 把文本看成是一系列词的集合(袋子)
- 词和词相互独立,一个词是否在文本中出现不依赖于其他词
import numpy as np
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
text =['John likes to watch movies,Mary likes too.', 'John also likes to watch football games.']
contv = CountVectorizer()
contv_fit = contv.fit_transform(text)
print(contv.vocabulary_)
print(contv.get_feature_names())
print(contv_fit.toarray())
问题:
- 忽略了词和词之间的关联顺序(我是他爸爸 vs 他是我爸爸)
text =['我 是 他 爸爸 ', '他 是 我 爸爸']
contv = CountVectorizer(token_pattern = '(?u)\\b\\w+\\b')
contv_fit = contv.fit_transform(text)
print(contv.get_feature_names())
print(contv_fit.toarray())
- 忽略了词和词之间的相近程度(我爱他 vs 我喜欢他,我爱他 vs 我恨他)
text =['我 爱 他', '我 喜欢 他', '我 恨 他']
contv = CountVectorizer(token_pattern = '(?u)\\b\\w+\\b')
contv_fit = contv.fit_transform(text)
print(contv.get_feature_names())
print(contv_fit.toarray())
cos(‘我爱他’,’我喜欢他’)=0.667
cos(‘我爱他’,’我恨他’)=0.667


- 导致稀疏矩阵和维度灾难(词典有多少词,每个文本就有多少维)
知识点3.1.3 N-gram模型
- 把文本看成是一系列词的集合
- 词和词不相互独立,下一个词在文本中出现依赖于前面的词 例:我学习NLP课程
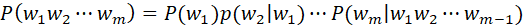
- 每个词出现的条件概率即是词频的比值(极大似然估计)

- 为了防止数据过于稀疏(词序列越长在训练集中相邻出现的概率越低,从而导致产生大量的零概率),假设下一个词在文本中出现仅依赖于前1个或n个词(马尔科夫假设)
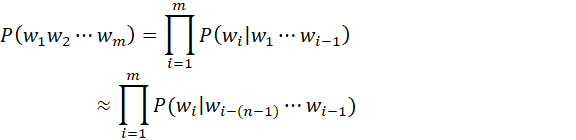
- 为了防止参数空间过大(如果基于训练集构建的词典大小为V V V,那么训练n-gram模型需要的参数空间为V n V^n V n),在实际应用中n的取值一般不超过5,多为Bi-gram(一个词的出现依赖前一个词)或Tri-gram(一个词的出现依赖前两个词),也可使用log将概率相乘变为概率相加以缓解数据下溢问题(underflow,当数据过小被取整为0)
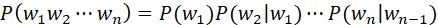
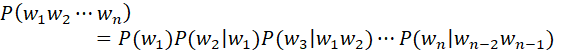
《Language Modeling with Ngrams》中加州餐厅语料库的例子:

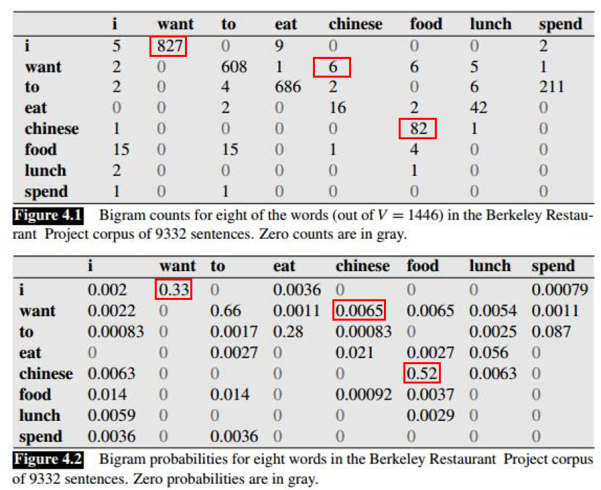
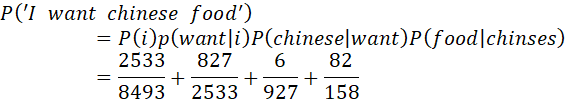
问题:
- 无法体现文本相似度
- 无法利用长距离信息 n越大,对下一个词出现的约束信息越多,模型能够获得更高的辨别力,但数据会越稀疏、参数空间会越大 n越小,词序列在训练集中出现的次数越多,模型能够获得更可靠的统计信息,但模型辨别力会相对下降
text =['我 是 他 爸爸 ', '他 是 我 爸爸']
contv = CountVectorizer(ngram_range = (1, 2), token_pattern = '(?u)\\b\\w+\\b')
contv_fit = contv.fit_transform(text)
print(contv.get_feature_names())
print(contv_fit.toarray())
欢迎关注微信公众号”Trihub数据社”
Original: https://blog.csdn.net/Yif18/article/details/122728664
Author: Yif18
Title: Chapter 3.1 文本向量化和语言模型(一)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531868/
转载文章受原作者版权保护。转载请注明原作者出处!