

图像检索与识别
- 前言
- 1.Bag-of-words模型
- 2.Bag of features原理: 图像特征词典
* - 2.1.特征提取
- 2.2.K-means聚类算法
- 2.3.图像检索
- 3.代码实现
* - 3.1训练视觉词典
- 3.2.构建索引
- 3.3.检索图片
- 3.4.测试结果
- 4.总结
前言
之前介绍了计算机视觉的基础内容,本篇正式介绍计算机视觉一个应用广泛的内容,图像的检索与识别,这里我们使用的方法是由自然语言处理领域的Bag-of-words 模型改进而来的Bag of features。
1.Bag-of-words模型
在介绍Bag of features模型前,我们先介绍其原型Bag-of-words 模型。
Bagofwords模型,也叫做”词袋”,在信息检索中,Bag of words model假定对于一个文本,忽略其词序和语法、句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现,或者说当这篇文章的作者在任意一个位置选择一个词汇都不受前面句子的影响而独立选择的。
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:74ccd839-0bde-447b-975b-c254752664ca
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:f0fdfc4d-e452-4c7f-bb19-2eda4d6968ee
具体原理可以参考我以前写的朴素贝叶斯算法里的词袋模型:机器学习_5:朴素贝叶斯算法
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:8bfac8eb-9be7-4d45-a578-9f85c89cbb73
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:6b79d3c1-b55c-40a7-90e7-ebc4c72e990d
2.Bag of features原理: 图像特征词典
2.1.特征提取
和以前的特征提取一样,我们使用SIFT算法提取特征点,假设我们每张图像提取的特征点数目是固定的100个(实际上每幅图像能提取的特征点数量不同且远远大于100个),假设有100张图片(实际图片数目远比这个多),那么我们一共可以收集到1万个特征点。如果我们直接用这1万个特征点作为视觉词典,针对输入特征集,根据视觉词典进行量化,把输入图像转化成视觉单词(visual words)的频率直方图。
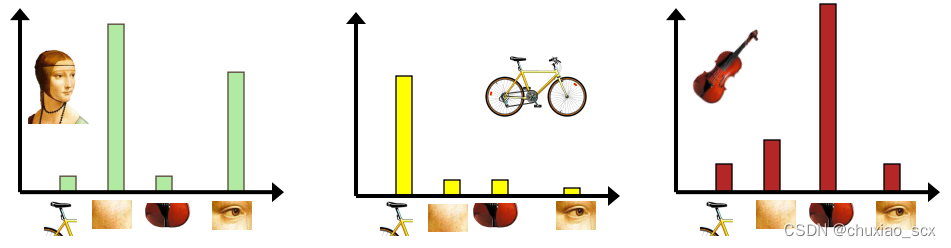

[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b6f6ee09-eb56-4185-9f01-13fb23c7b7fc
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:b88a670d-01b4-4d5c-9685-a4a9c5374f4f
; 2.2.K-means聚类算法



如图所示,每个特征点都有RGB三个像素通道,我们将这些特征点转换成RGB色彩空间中的立体点,然后随机设置k个聚类中心,最小化每个特征 xi 与其相对应的聚类中心 mk之间的欧式距离,最后将所有的特征点聚集成k个特征中心,这样我们就可以大幅度减少视觉词典内的特征数。

算法流程:
1.随机初始化 K 个聚类中
2.重复下述步骤直至算法收敛:
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:593da3cb-9827-4e3b-ba41-8140649ddc9f
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:cb687046-32cc-47d1-9a7a-f2945da75955
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:60c43244-4952-4846-8190-1e74b5e47bd5
[En]
[TencentCloudSDKException] code:FailedOperation.ServiceIsolate message:service is stopped due to arrears, please recharge your account in Tencent Cloud requestId:2e5c1120-0d88-4085-8e15-d5c08c12f8ff
问题显而易见,k的取值是比较难以确定的,k值太少,视觉单词无法覆盖所有可能出现的情况,k值过大,计算量大,容易过拟合
2.3.图像检索
那么有了给定图像的bag-of-features直方图特征,应该如何实现图像分类/检索呢?
给定输入图像的BOW直方图, 在数据库中查找 k 个最近邻的图像,对于图像分类问题,可以根据这k个近邻图像的分类标签,投票获得分类结果,当训练数据足以表述所有图像的时候,检索/分类效果良好
3.代码实现
3.1训练视觉词典
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
imlist = get_imlist("D:\\vscode\\python\\input\\image")
nbr_images = len(imlist)
print('nbr_images:',nbr_images)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
voc = vocabulary.Vocabulary('Image')
voc.train(featlist, 200, 10)
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print ('vocabulary is:', voc.name, voc.nbr_words)
3.2.构建索引
import pickle
from PCV.imagesearch import imagesearch
from PCV.localdescriptors import sift
from sqlite3 import dbapi2 as sqlite
from PCV.tools.imtools import get_imlist
imlist = get_imlist("D:\\vscode\\python\\input\\image")
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
indx = imagesearch.Indexer('testImaAdd.db',voc)
indx.create_tables()
for i in range(nbr_images)[:110]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr)
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
3.3.检索图片
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
imlist = get_imlist('D:\\vscode\\python\\input\\image')
nbr_images = len(imlist)
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
with open('D:\\vscode\\python\\input\\image\\vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)
q_ind = 1
nbr_results = 5
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]]
print ('top matches (regular):', res_reg)
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
model = homography.RansacModel()
rank = {}
for ndx in res_reg[1:]:
locs,descr = sift.read_features_from_file(featlist[ndx])
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
rank[ndx] = len(inliers)
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
imagesearch.plot_results(src,res_reg[:5])
imagesearch.plot_results(src,res_geom[:5])
3.4.测试结果

; 4.总结
1.使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。
2.字典大小的选择也是问题,字典过大,单词缺乏一般性,对噪声敏感,计算量大,关键是图象投影后的维数高;字典太小,单词区分性能差,对相似的目标特征无法表示。
3.相似性测度函数用来将图象特征分类到单词本的对应单词上,其涉及线型核,塌方距离测度核,直方图交叉核等的选择。
Original: https://blog.csdn.net/chuxiao_scx/article/details/125154826
Author: chuxiao_scx
Title: Python计算机视觉编程_05
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/560936/
转载文章受原作者版权保护。转载请注明原作者出处!