

Knowledge Graph Embedding by Translating on Hyperplanes
摘要
研究了将由实体和关系组成的大规模知识图谱嵌入到连续向量空间中的问题。TransE是最近提出的一种很有前途的方法,其非常高效,同时可以获得最优的预测效果。我们讨论了一些关系的映射属性,这些属性在嵌入时应该被考虑,比如自反性、一对多、多对一和多对多。我们注意到,TransE在处理这些属性方面做得并不好。一些复杂模型能够保持这些映射属性,但在处理过程中效率不高。为了在模型性能和效率之间取得良好的平衡,本文提出了TransH,其可以构建关系的超平面并执行翻译操作。这样,我们可以很好的保持上面提到的关系映射属性,且模型复杂度与TransE相似。另外,作为一个实用的知识图谱,其往往是不完整的,如何在训练中构造负采样来减少假负标签则显得非常重要。利用一个关系的一对多/多对一映射属性,我们提出了一个简单的技巧来降低假负标签的可能性。我们在标准数据集如WordNet和Freebase上进行了大量的链接预测、三元组分类和事实抽取的实验。实验表明,与TransE相比,TransH在预测精度上有显著的改进,并具有与之相当的扩展能力。
引言
知识图谱,如Freebase (Bollacker et al. 2008)、WordNet (Miller 1995)和GeneOntology
(Ashburner et al. 2000)已经成为支持许多人工智能相关应用的重要资源,如网络/手机搜索、问答等。知识图谱是由实体作为节点,关系作为不同类型的边组成的多元关系图。边的一个实例是事实三元组(头实体、关系、尾实体)(记为(h, r, t))。过去十年中,在构建大规模知识图谱方面已经取得了巨大的成就,但是支持计算的一般范式仍然不清楚。两大难点是:
(1)知识图谱是一种符号逻辑系统,其应用往往涉及连续空间的数值计算;
(2)很难在一个图谱中聚集全局信息。
传统的形式逻辑推理方法在处理大规模知识图谱的长时间推理时,既不易于操作,也不耐用。最近提出一种新方法来处理该问题,即试图将知识图谱嵌入到一个连续向量空间中,同时保持原始图谱的某些属性(Socher等, 2013;Bordes等,2013a;Weston等,2013;Bordes等,2011;2013 b;2012;Chang、Yih和Meek 2013)。例如,每个实体 h(或 t)被表示为向量空间中的一个点 h(或 t),而每个关系 r_被建模为空间中的一个操作,该操作以一个向量 r为特征,如翻译、投影等。实体和关系的表示是通过最小化一个涉及所有实体和关系的全局损失函数得到的。因此,即使单个实体/关系的嵌入表示也能从整个知识图谱中编码全局信息。然后,嵌入表示可以用于各种应用程序。其中一个直截了当的应用是补全知识图中缺失的边。对于任意候选三元组(_h, r, t),我们只需检查 h和 t在 r所表征的运算下表示的兼容性即可确定其正确性。
通常知识图谱嵌入将实体表示为 k_维向量 h(或 t),并定义一个得分函数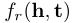
 来衡量嵌入空间中三元组(_h, r, t)关联的合理性。得分函数表示以关系 r_为表征的实体对之间的转换 r。例如,在基于TransE的翻译中(Bordes et al. 2013b), _fr (h , t)=
来衡量嵌入空间中三元组(_h, r, t)关联的合理性。得分函数表示以关系 r_为表征的实体对之间的转换 r。例如,在基于TransE的翻译中(Bordes et al. 2013b), _fr (h , t)=
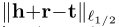 ,即通过翻译(向量) r来表征关系 r。不同的得分函数表示的转换不同,有简单差异 (Bordes et al. 2012), 翻译 (Bordes et al. 2013b), 仿射 (Chang, Yih, and Meek 2013), 一般线性 (Bordes et al. 2011), 双线性 (Jenatton et al. 2012; Sutskever, Tenenbaum, and Salakhutdinov 2009)和非线性变换(Socher et al. 2013). 根据模型的复杂性(以参数数量为依据)变化显著。(详情见表1及”有关工作”部分。)
,即通过翻译(向量) r来表征关系 r。不同的得分函数表示的转换不同,有简单差异 (Bordes et al. 2012), 翻译 (Bordes et al. 2013b), 仿射 (Chang, Yih, and Meek 2013), 一般线性 (Bordes et al. 2011), 双线性 (Jenatton et al. 2012; Sutskever, Tenenbaum, and Salakhutdinov 2009)和非线性变换(Socher et al. 2013). 根据模型的复杂性(以参数数量为依据)变化显著。(详情见表1及”有关工作”部分。)

在之前的方法中,TransE (Bordes et al. 2013b)是一个很有前途的方法,因为它既简单又高效,同时达到了最先进的预测效果。然而,我们发现在处理自反/一对多/多对一/多对多映射属性的关系时,TransE存在缺陷。以前很少讨论这些映射属性在嵌入中的作用。一些具有更多自由参数的高级模型能够保留这些映射属性,但是,模型的复杂性和运行时间也因此显著增加。此外,先进模型的整体预测效果甚至不如TransE (Bordes et al. 2013b)。这促使我们提出了一种能够很好地平衡模型复杂性和效率的方法,从而在继承效率的同时克服TransE的缺陷。
本文从分析TransE在自反关系、一对多关系、多对一关系、多对多关系的问题入手。为此,我们提出了一种名为 translation on hyperplanes(TransH)的方法,该方法将关系解释为超平面上的翻译操作。在TransH中,每个关系由超平面的法向量(
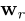 )和超平面上的翻译向量()表征。对于一个正确三元组(h, r, t),它在客观现实中是正确的,期望 h和 t在超平面上的 _投影_通过翻译向量 d _r_以低误差连接起来。这种简单的方法克服了TransE在处理自反/一对多/多对一/多对多关系时的缺陷,同时模型复杂度与TransE基本相同。关于模型训练,我们指出,在知识嵌入中认真构建负标签很重要。通过依次利用关系的映射属性,我们提出了一个简单的技巧来降低假负标签的出现。我们在基准数据集(如WordNet和Freebase)上进行了大量的链接预测、三元组分类和事实抽取的实验,在不同的预测精度指标上显示出了显著性的改进。TransH与TransE的运行时间也相差不大。
)和超平面上的翻译向量()表征。对于一个正确三元组(h, r, t),它在客观现实中是正确的,期望 h和 t在超平面上的 _投影_通过翻译向量 d _r_以低误差连接起来。这种简单的方法克服了TransE在处理自反/一对多/多对一/多对多关系时的缺陷,同时模型复杂度与TransE基本相同。关于模型训练,我们指出,在知识嵌入中认真构建负标签很重要。通过依次利用关系的映射属性,我们提出了一个简单的技巧来降低假负标签的出现。我们在基准数据集(如WordNet和Freebase)上进行了大量的链接预测、三元组分类和事实抽取的实验,在不同的预测精度指标上显示出了显著性的改进。TransH与TransE的运行时间也相差不大。
; 相关工作
表1简要总结了最相关的工作。所有这些方法都将实体嵌入到一个向量空间中,并在一个评分函数下强制嵌入兼容。不同的模型对得分函数 fr(h, r)的定义不同,即在 h和 t上有一些变化。
TransE(Bordes et al. 2013b) 表示翻译向量 r的关系,因此三元组( h,r,t)中的嵌入实体对可以通过 r以低误差连接。 TransE在达到最新的预测性能的同时非常高效。但是,它在处理自反/一对多/多对一/多对多关系方面存在缺陷。
Unstructured是TransE的简化情况,该情况将图谱视为单关系并设置所有的翻译 r = 0,即得分函数为|| h– t||。在(Bordes et al.2012; 2013b)中,它被用作单纯的基准。显然,它无法区分不同的关系。
Distant Model (Bordes et al. 2011) 为关系中的实体引入了两个独立的投影。它通过左矩阵
 和右矩阵表示关系。相异性通过 Wrh h与 Wrt t之间的
和右矩阵表示关系。相异性通过 Wrh h与 Wrt t之间的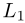 距离来衡量。正如(Socher等人,2013年)指出的那样,该模型在捕获实体和关系之间的相关性方面很弱,因为它使用了两个单独的矩阵。
距离来衡量。正如(Socher等人,2013年)指出的那样,该模型在捕获实体和关系之间的相关性方面很弱,因为它使用了两个单独的矩阵。Bilinear Model (Jenatton et al. 2012; Sutskever, Tenenbaum, and Salakhutdinov 2009) 通过二次形式对实体嵌入之间的二阶相关性进行建模:
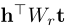 。因此,一个实体的每个组件都与另一个实体的每个组件进行交互。
。因此,一个实体的每个组件都与另一个实体的每个组件进行交互。Single Layer Model (Socher et al. 2013) 通过神经网络引入了非线性变换。它将 h和 t作为输入层连接到非线性隐藏层,然后线性输出层给出结果分数:
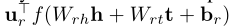 。 (Collobert and Weston 2008)提出了类似的结构。
。 (Collobert and Weston 2008)提出了类似的结构。NTN (Socher et al. 2013) 是迄今为止最具表现力的模型。它通过考虑将二阶相关转换为非线性变换(神经网络)来扩展单层神经网络。得分函数为 u r f( h Wr t + Wrh h + Wrt t + b r)。 正如作者分析的那样,即使张量 W _r_退化为矩阵,它也涵盖了上述所有模型。但是,模型复杂度高得多,因此难以处理大规模图谱。
除了直接针对嵌入知识图谱的同一问题的这些工作之外,在多元关系数据建模,矩阵分解和建议等更广泛的领域中还有大量相关作品。请参考(Bordes et al. 2013b)的”简介”部分。
通过在超平面上翻译嵌入
首先描述常见的符号。
符号表示
h,r,t
头实体,关系,尾实体
h,r,t
头实体,关系,尾实体的嵌入表示△,△’正确三元组,错误三元组(h,r,t)∈∆(h,r,t)表述正确
E
实体集
R
关系集
嵌入中的关系映射属性

考虑到如果( h,r,t)∈∆时 h + r − t = 0的无误差嵌入的理想情况,我们可以直接从TransE模型获得以下结果:
- 如果( h,r,t)∈∆且( t,r,h)∈∆,即 _r_是自反关系图,则 r = 0且 h = t。

即, _r_是一对多关系图,则 t0= . . . = tm.
导致上述结果的原因是,在TransE中,当涉及任何关系时,实体的表示形式相同,而当涉及不同的关系时,则忽略实体的分布式表示形式。尽管TransE不强迫 h+r-t = 0以得到正确三元组,但它排名损失来激励低误差以得到正确三元组,而对于错误三元组的误差更高(Bordes等人,2013b),上述主张的趋势仍然存在。
在超平面上翻译(TransH)


得分函数为


在TransH中,通过引入投影到特定关系超平面的机制,它可以使实体在不同的关系/三元组中扮演不同的角色。

; 训练
为了激励区分正确三元组和错误三元组,我们使用以下基于边距的排名损失:
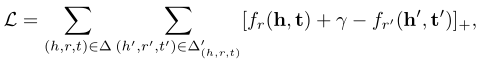

当我们最小化损失L时,考虑以下约束:


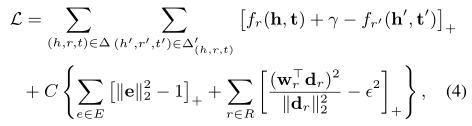
其中C是权重软约束重要性的超参数。

减少假负标签
如上一节所述,训练涉及为正确三元组构造负三元组。先前的方法只是通过随机破坏正确三元组来获取负三元组。例如,在TransE中,对于正确三元组( h,r,t),通过从 E_中随机采样一对实体( _h’,t’ )来获得负三元组( h’,r,t’ )。然而,知识图谱通常并不完整,这种随机抽样的方式可能会在训练中引入许多假负标签。
对于TransH,我们采用不同的方法。基本上,当破坏三元组时,我们设置不同的概率以替换头或尾实体,这取决于关系的映射属性,即一对多、多对一或多对多。如果关系为一对多,则倾向于更多的替换头实体,如果关系为多对一,则倾向于更多的替换尾实体。这样,减少了产生假负标签的情况。具体而言,在关系 r_的所有三元组中,我们首先获得以下两个统计信息:
(1)每个头实体的平均尾实体数,表示为 _tph;
(2)每个尾实体的平均头实体数,表示为 hpt。

实验
我们对三个任务进行实证研究和评估相关方法:链接预测(Bordes等,2013b),三元组分类(Socher等,2013)和事实关系抽取(Weston等,2013)。所有这三个任务都从不同的角度和文本信息上评估了预测不可见三元组的准确性。
链接预测
用于(Bordes et al. 2011; 2013b),此任务是为了补全三元组( h,r,t)中缺失的 h_或 _t,即给定( h,r)预测 t_或给定( _r,t )预测 h。该任务不是要求得到最佳答案,而是着重于对知识图谱中的一组候选实体集进行排名。
我们使用与TransE中相同的两个数据集(Bordes等,2011; 2013b):WN18,Wordnet的子集; FB15k,这是Freebase的相对密集子图,其中所有实体都存在于Wikilinks数据库中。两者均发布于(Bordes等人,2013b)。更多信息详见表2。

; 评估规约

实现
由于数据集相同,我们直接从中复制了几个基线的实验结果(Bordes等人,2013b)。在训练TransH时,我们在{0.001,0.005,0.01}中选择SGD的学习率 α,在{0.25,0.5,1,2}中选择裕度 γ,在{50,75,100}中选择嵌入维度 k,在{ 0.015625、0.0625、0.25、1.0}中选择权重 C,在{20,75,300,1200,4800}中选择批量大小 B。最优参数由验证集决定。关于构造负标签的策略,使用” unif”来表示以相等概率替换头部或尾部的传统方式,并使用” bern.”表示以不同概率替换头部或尾部来减少假负标签。在” unif”设置下,最优配置为:WN18上: α= 0.01, γ= 1, k = 50, C = 0.25及 B = 75;FB15k: α= 0.005, γ= 0.5, k = 50, C = 0.015625及 B = 1200。在” bern”设置下,最优配置为:WN18上: α= 0.01, γ= 1, k = 50, C = 0.25及 B = 1200;FB15k: α= 0.005, γ= 0.25, k = 100, C = 1.0和 B = 4800。对于这两个数据集,我们遍历所有训练三元组500轮。
结果

; 三元组分类
该工作是确认给定的三元组( h,r,t)是否正确,即在三元组上进行二进制分类。 (Socher et al. 2013)使用它来评估NTN模型。
该工作使用三个数据集。其中两个与NTN中的相同(Socher等,2013):WN11,WordNet的子集; FB13,Freebase的子集。由于WN11和FB13包含的关系数很少,因此我们也使用包含更多关系的FB15k数据集。有关详细信息,祥见表2。
评估规约
遵循与NTN相同的规约(Socher等,2013)。分类评估需要负标签。 WN11和FB13的已发布集已包含负三元组,这些负三元组由(Socher et al。2013)构造,其中每个正确三元组都被破坏成负三元组。对于FB15k,我们按照(Socher et al. 2013)中用于FB13的相同步骤构造负三元组。

实现
对于WN11和FB13,使用相同的数据集,直接复制(Socher et al. 2013)中不同方法的结果。对于未在(Socher et al. 2013)中使用的FB15k,我们自己实现了TransE和TransH,并将使用在NTN上已发布的代码。
对于TransE,我们在{0.001,0.005,0.01,0.1}中选择学习率 α,在{1.0,2.0}中选择边距 γ,在{20,50,100}中选择嵌入维度 k,在{30,120,480,1920}中选择批量大小为 B。我们还将套用减少假负标签的技巧到TransE。 TransE的最优配置(bern.)为: α= 0.01,k = 20,γ= 2.0,B = 120_及 _L1_作为WN11上的相异度指标; _α= 0.001,k = 100,γ= 2.0,B = 30_及 _L1_作为FB13上的相异度指标;, _α= 0.005,k = 100,γ= 2.0,B = 480_及 _L1_作为FB15k上的相异度指标。对于TransH,超参数的搜索空间与链接预测相同。TransH(bern.)在WN11上的最优超参数为: _α= 0.01,k = 100,γ= 2.0,C = 0.25_及 _B = 4800; FB13: α= 0.001,k = 100,γ= 0.25,C = 0.0625_及 _B = 4800;FB15k: α= 0.01,k = 100,γ= 0.25,C = 0.0625_及 _B = 4800。我们没有在FB113上更改NTN代码的配置,其中维数 k = 100,切片数等于3。由于FB15k相对较大,我们将周期数限制为500。
结果
准确性见表6。在WN11上,TransH优于所有其他方法。在FB13上,功能强大的NTN模型是最好的模型。但是,在较大的FB15k上,TransE和TransH比NTN更好。注意,当实体的数接近时,FB15k的关系数(1,345)比FB13的关系数(13)大得多(见表2)。这意味着FB13是一个非常密集的子图谱,其中实体之间存在很强的相关性。在这种情况下,通过张量和非线性变换对实体之间复杂的相关性进行建模有助于嵌入。但是,在FB15k的较稀疏子图谱中,似乎简单地假设在超平面上进行翻译就足够了,而不必使用复杂的NTN模型。关于运行时间,NTN的耗时比TransE / TransH高得多。另外,在所有三个数据集上,减少假负标签(” bern.”的结果)的技巧有助于TransE和TransH。
在NTN中(Socher等人,2013年)还报告了将其与词嵌入(Mikolov等人,2013年)相结合的结果。但是,如何最好地结合单词嵌入与模型有关,这也是一个超出了本文范围之外的开放性问题。为了公开、公正地进行比较,表6中的所有结果均未与词嵌入结合。

; 文本关系抽取
从文本中提取关系事实是丰富知识图谱的重要渠道。大多数现有的提取方法(Mintz等,2009; Riedel、Yao和McCallum,2010; Hoffmann等,2011; Surdeanu等,2012)从外部文本语料库中为候选事实远程收集依据,而忽略了知识图谱本身可以推理新事实。实际上,知识图谱嵌入能够对候选事实进行评分,而无需观察来自外部文本语料库的任何依据。最近(Weston等,2013)将 TransE的得分(知识图的依据)与 文本侧提取模型的得分(文本语料库的依据)相结合,并观察到了有效的改进。在本实验中,我们比较了TransH和TransE对改进关系事实提取的贡献。
该实验包括两个主要部分:文本侧提取模型和知识图谱嵌入。
对于文本侧,我们使用(Weston等人,2013)中相同的数据集-由(Riedel、Yao和McCallum 2010)发布的NYT + FB。他们通过使用Stanford NER(Finkel、Grenager和Manning 2005)标记文本中的实体,并通过名称上的字符串匹配将它们链接到Freebase ID,从而使Freebase关系与New York Times语料库保持一致。我们仅考虑数据集中最受欢迎的50个谓词,包括负类” NA”。然后将数据集分为两部分:一部分用于训练,另一部分用于测试。对于文本侧提取方法,TransE和TransH均可用于为任何文本侧方法提供先验分数。为了与(Weston et al.2013)中报道的TransE进行公开公正的比较,我们与(Weston et al.2013)中使用相同的文本侧方法 Wsabie M2R,本文称其为 Sm2r。
对于知识图谱嵌入,(Weston等人,2013)使用了Freebase子集,该子集由最受欢迎的4M实体和Freebase所有23k 关系组成。由于他们尚未发布实验中使用的子集,因此我们遵循类似的程序从Freebase中生成FB5M子集(表2)。重要的是,我们从FB5M中删除了测试集中出现的所有实体对,因此泛化测试不是伪造的。由于FB5M的规模,我们没有全面搜索就为TransE / TransH选择参数。为简单起见,在TransE和TransH中,我们设置嵌入维数 k_为50,设置SGD的学习率 _α_为0.01,设置边距 _γ_为1.0,设置TransE的相异度为 _L2。

遵循将知识图谱嵌入的分数与文本侧模型的分数相结合的相同规则,可以获得TransE和TransH的精确调用曲线,如图2(a)所示。从图中可以看出,TransH在改进文本侧提取方法Sm2r方面是”先进”模型,其性能始终优于TransE。
图2(a)中的结果取决于将知识图谱嵌入的得分与文本侧模型的得分相结合的特定规则。实际上(Weston et al. 2013)中的合并规则是特别的,其可能不是最佳方法。因此,图2(a)不能清楚地展示TransE / TransH作为关系事实预测的独立模型的独立功能。为了清楚地展示TransE / TransH的独立功能,我们首先使用文本侧模型Sm2r将每个实体对分配给具有最高置信度得分的关系,然后保留那些分配关系不是” NA”的事实。对于这些可信的候选事实,我们仅使用TransE / TransH的分数进行预测。结果示于图2(b)。在候选子集上,TransE和TransH的性能均优于文本侧模型Sm2r。当召回率高于0.6时,TransH的性能要比TransE好得多。
; 结论
本文介绍了TransH,一种将知识图谱嵌入到连续向量空间中的新模型。 TransH在继承效率的同时克服了TransE关于自反/一对多/多对一/多对多关系的缺陷。对链接预测,三元组分类和关系事实提取工作的大量实验表明,TransH为TransE带来了可喜的改进。本文提出的减少假负标签的技巧也被证明是有效的。
参考文献
Ashburner, M.; Ball, C. A.; Blake, J. A.; Botstein, D.; But-ler, H.; Cherry, J. M.; Davis, A. P .; Dolinski, K.; Dwight,S. S.; Eppig, J. T.; et al. 2000. Gene ontology: Tool for theunification of biology. Nature genetics 25(1):25–29.
Bollacker, K.; Evans, C.; Paritosh, P .; Sturge, T.; and Taylor,J. 2008. Freebase: A collaboratively created graph databasefor structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, 1247–1250. ACM.
Bordes, A.; Weston, J.; Collobert, R.; and Bengio, Y . 2011. Learning structured embeddings of knowledge bases. In Proceedings of the 25th AAAI Conference on Artificial Intelligence.
Bordes, A.; Glorot, X.; Weston, J.; and Bengio, Y . 2012. A semantic matching energy function for learning with multirelational data. Machine Learning 1–27.
Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and Y akhnenko, O. 2013a. Irreflexive and hierarchical relations as translations. arXiv preprint arXiv:1304.7158. Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and
Yakhnenko, O. 2013b. Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems 26. Curran Associates, Inc. 2787–2795.
Chang, K.-W.; Yih, W.-t.; and Meek, C. 2013. Multrelational latent semantic analysis. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1602–1612. Seattle, Washington, USA:Association for Computational Linguistics.
Collobert, R., and Weston, J. 2008. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th Annual International Conference on Machine Learning (ICML 2008), 160–167. Omnipress.
Finkel, J. R.; Grenager, T.; and Manning, C. 2005. Incorporating non-local information into information extraction systems by gibbs sampling. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, 363–370. Association for Computational Linguistics.
Hoffmann, R.; Zhang, C.; Ling, X.; Zettlemoyer, L. S.; and Weld, D. S. 2011. Knowledge-based weak supervision for information extraction of overlapping relations. In Proceedings of the 49th Annual Meeting on Association for Computational Linguistics, 541–550. Association for Computational Linguistics.
Jenatton, R.; Roux, N. L.; Bordes, A.; and Obozinski, G. R. 2012. A latent factor model for highly multi-relational data. In Advances in Neural Information Processing Systems 25. Curran Associates, Inc. 3167–3175.
Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G. S.; and Dean, J. 2013. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26. Curran Associates, Inc. 3111–3119.
Miller, G. A. 1995. Wordnet: A lexical database for english. Communications of the ACM 38(11):39–41.
Mintz, M.; Bills, S.; Snow, R.; and Jurafsky, D. 2009. Distant supervision for relation extraction without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-V olume 2, 1003–1011. Association for Computational Linguistics.
Nickel, M.; Tresp, V .; and Kriegel, H.-P . 2011. A threeway model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), ICML ’11, 809–816. New Y ork,NY , USA: ACM.
Riedel, S.; Y ao, L.; and McCallum, A. 2010. Modeling relations and their mentions without labeled text. In Machine Learning and Knowledge Discovery in Databases. Springer.148–163.
Socher, R.; Chen, D.; Manning, C. D.; and Ng, A. 2013. Reasoning with neural tensor networks for knowledge base completion. In Advances in Neural Information Processing Systems 26. Curran Associates, Inc. 926–934.
Surdeanu, M.; Tibshirani, J.; Nallapati, R.; and Manning, C. D. 2012. Multi-instance multi-label learning for relation extraction. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 455–465. As-
sociation for Computational Linguistics.
Sutskever, I.; Tenenbaum, J. B.; and Salakhutdinov, R. 2009. Modelling relational data using bayesian clustered tensor factorization. In Advances in Neural Information Processing Systems 22. Curran Associates, Inc. 1821–1828.
Weston, J.; Bordes, A.; Y akhnenko, O.; and Usunier, N. 2013. Connecting language and knowledge bases with embedding models for relation extraction. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1366–1371. Seattle, Washington, USA:
Association for Computational Linguistics.
仅用作学习笔记,翻译如有错误,欢迎指正。
Original: https://blog.csdn.net/weixin_48716320/article/details/110734187
Author: Ting廷帅
Title: TransH论文翻译
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558088/
转载文章受原作者版权保护。转载请注明原作者出处!