

Python机器学习(三)——回归
Python机器学习(一)——特征工程
Python机器学习(二)——数据可视化
Python机器学习(四)——分类
这一节,我们将一起探讨线性回归模型,在使用线性回归中我们一般的流程如下:
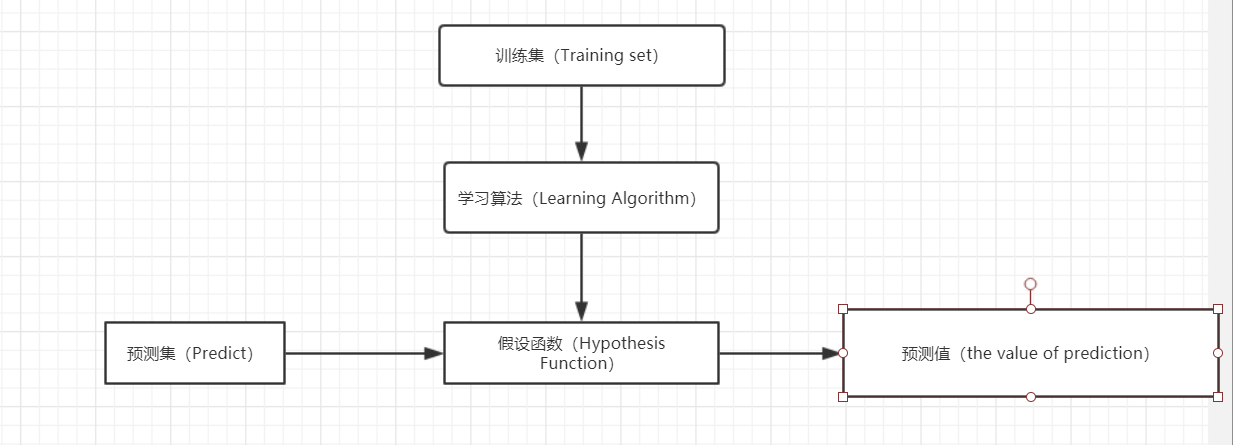

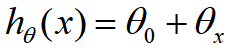
而我们选用的学习算法常用也有两种:最小二乘法、梯度下降法。而在介绍这些之前我们要先介绍一下误差函数。
; 代价函数(Cost Function)
损失函数(loss function):是当我们适用于(拟合)每个单个训练事例时所产生的误差;
代价函数(cost function):是在整个训练集中损失函数的平均值。
这里引用一张百科的图片
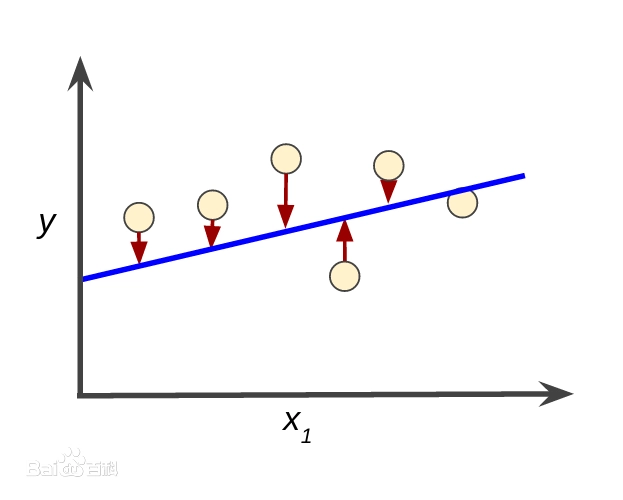
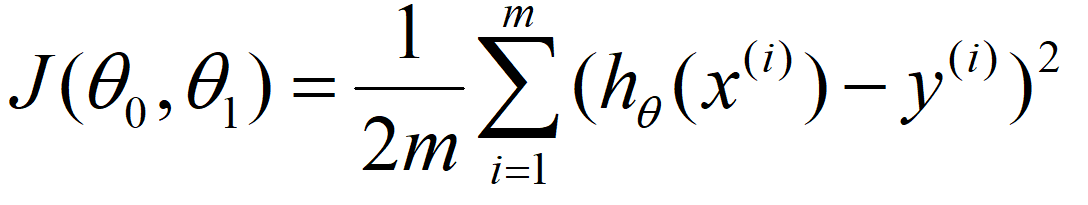
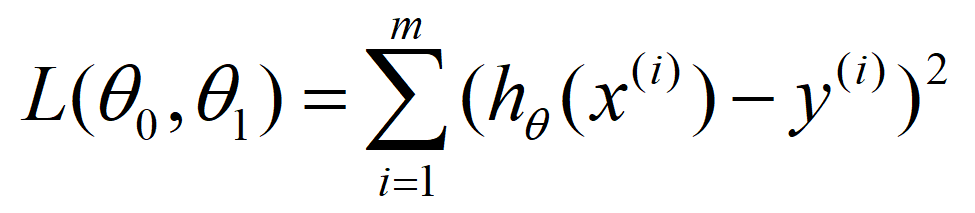
m:训练集的数量
而在这里我们所需要的就是是这个式子的值最小,代价函数值越小意味着我们的建立的假设函数模型越贴近实际真实情况。而在处理最小化问题时我们常用采取以下方式:
最小二乘法
该法是直接求解残差函数最小值,对其直接求导,我们可以得到这样的式子
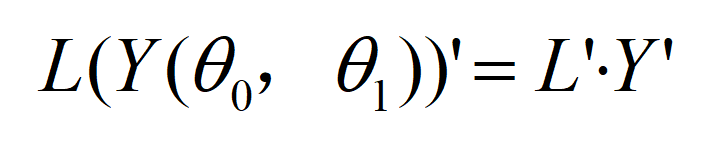
(此处文本编辑数学式子实属不易,就粗略表意)这就是链式求导法则(Chain Rule),而:L(外侧函数)’=2Y(内层函数),内层函数不可能为零,所以需要使Y’为零,导数值才能为零,而在这里Y为二元函数(theta zero&theta one),这里由全微分(Total Differential)可知当其偏导(Partial Differential)均为零时其导数值为零。在我们分别对其求偏导并使之为零时,我就可以分别求出其参数。
; 梯度下降
梯度下降算法的具体思想就是在θ0-θ1-J(θ)这个三维图像中,不断地找寻最快的下降方式,以不断的逼近最低点(即J(θ)的最小值)。
这里我们就要熟悉一个数学概念”梯度(Gradient)”
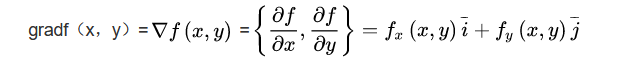
梯度下降就是要求沿梯度最大的方向下降,分解到两个方向就是分别以其原向量减去该点梯度的k倍,这个k倍就是其沿梯度下降的量度,我们称之为”学习率(learning rate)”这个学习率的选取也是十分讲究的,如果太大其误差也就很大,往往会越过极值点,无法精确的取值;而学习率太小的话会影响到我们的迭代速率。在下面将给出这个过程的式子
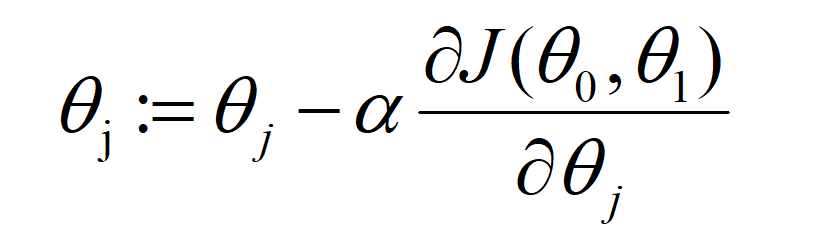
:=表示赋值,
j:j=0或 j=1
α:学习率
注意:这里同一组的θ0和θ1要同时进行赋值,即要相对应,否则分方向之间关联失调,这样的结果将会错误。
我们在这里的用H(θ)预测的对应x下y的情况中x、y并不一定是单例,他们多数情况下是一个向量(多元),毕竟我们的特征并不唯一,但无论是有多少个特征,其均符合线性的关系,所以其表达式可以写作:
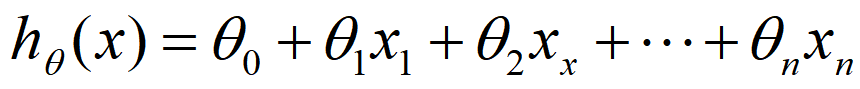
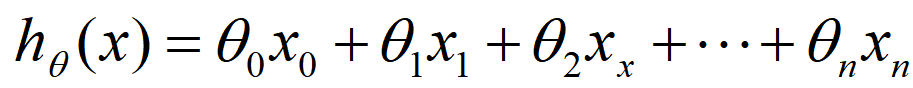
得到的这个式子我们就十分熟悉了,他就是θ向量的转置乘以x向量
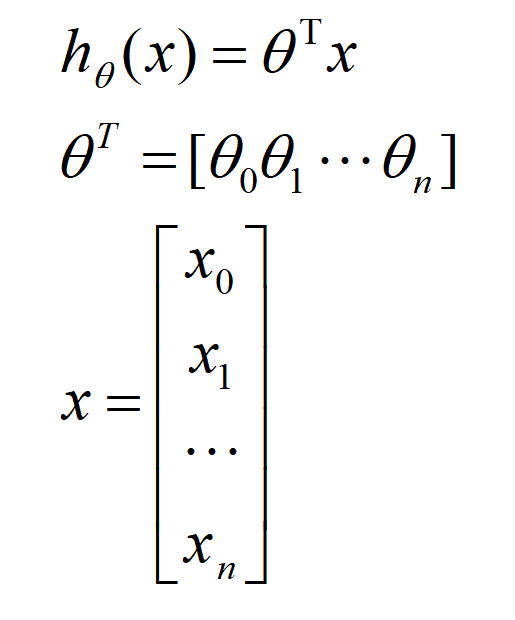
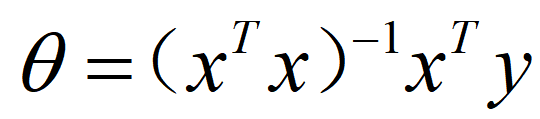
这个式子中含有求解逆矩阵的部分,但有时候这一块并不一定是可逆的,往往是因为特例数大于样例数这里我们就需要采取正则化处理。
在我们经行算法时还需要注意到许多问题,例如:特征放缩(Feature Scaling)、均值归一化(Mean Normalization)、α选取、拓展多项式(Polynomial Regression)(以元的不等阶多项式替代原元)、过拟合问题(Overfitting issue)与正则化处理(Regularization)等
代码实现
#首先,我们引用库
import numpy
import pandas
import sklearn
import seaborn
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#这个是将数据集分为训练集与测试集
#训练集是用来训练模型的,这里记作x_train,y_train
#测试集是用来测试模型的预测能力的,这里记作x_test,y_test
from sklearn .metrics import mean_squared_error, r2_score, mean_absolute_error
#这个方法的引用是用来评估拟合程度的
#mean_squared_error是均方误差,即我们前面所说的损失函数的值
#r2_score是R方系数,衡量变量间线性相关性
#先载入数据,并将其带特征打印
data_regression = pandas.read_csv('hour.csv')
data_regression.head()
#因为这组数据中,有很多特征,我挑选了一个与结果较有线性关系的特征
#先将数据可视化
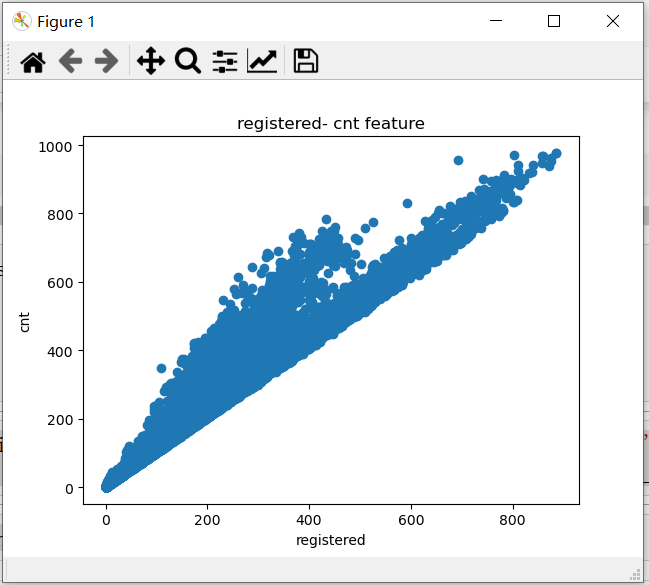
#见图一
plt.scatter(data_regression['registered'], data_regression['cnt'])
plt.xlabel('registered')
plt.ylabel('cnt')
plt.title('registered- cnt feature')
plt.show()
#将数据划分训练集与测试集(4:1)
x_train, x_test, y_train, y_test = train_test_split(data_regression['registered'],
data_regression['cnt'], test_size = 0.20)
#创建并告知Python线性回归对象
first_linear_regression = LinearRegression()
#fit()方法,用以将训练集适配训练模型
x_train = x_train.values
y_train = y_train.values
x_test = x_test.values
first_linear_regression.fit(pandas.DataFrame(x_train),pandas.DataFrame(y_train))
#模型训练完成后,使用测试集测试模型
#训练过程:使用模型对x_test集经行预测,然后在对比原数据,即y_test
prediction = first_linear_regression.predict(pandas.DataFrame(x_test))
#模型拟合的简单评估
#打印均方误差
print(mean_squared_error(y_test,prediction))
#打印R方系数
print(r2_score(y_test,prediction))
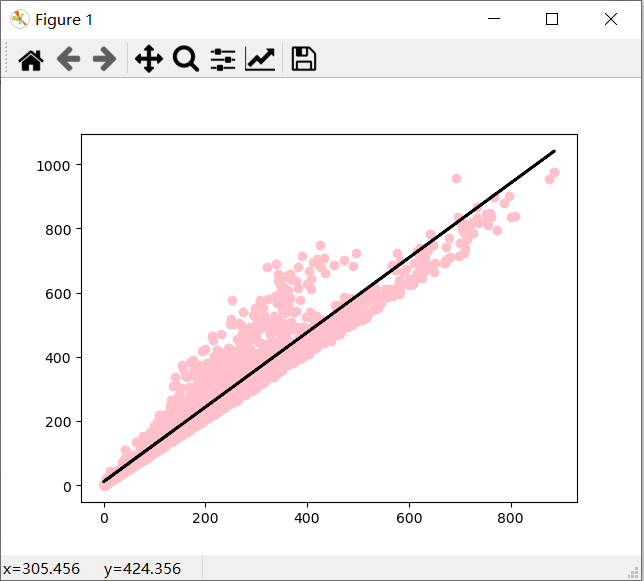
#绘制测试曲线(见图二)
#拟合预测曲线的绘制是以测试集的输入与预测值绘制
#同时绘制测试集的散点图以作对比
plt.scatter(x_test,y_test,color='pink')
plt.plot(x_test,prediction,color='black',linewidth = 2)
图一
以上就是经行简单的一元线性回归的基本步骤,但是我们可以总结出一般性的步骤:
1.数据的读取
2.数据的预处理(数据可视化、数据集划分等)
3.算法(线性回归)对象创建
4.(使用训练集对)模型的适配训练
5.(对测试集的)模型预测评估
6.模型性能评价(R方,均方误差,模型可视化等)
以上就是大致的线性回归思路,但是简单的一元线性回归并不足以满足实际的种种复杂情况,我们在模型建立、适配与预测的过程中,会遇到现有模型的不适配、高误差问题,我们就要采用其他的回归方式,例如:当数据分布不成直线时,我们可能需要使用到将原有的一阶变元替换成其它阶数经行数据的适应(或是多项式);当我们得到的数据是病态数据,我们会去使用前面提到的正则化处理,可能就会用到岭回归、套索回归等。这一领域涉及到数学统计学、计算数学等十分的复杂。但源点均是从原始的算法出发,不断的改良以适合更加现实或是极端的情形。值得高兴的是他们的模型组建流程与基础的结构是大体相似,其变化大体是产生在不同方法函数的运用,所以这些复杂模型的重点在于其背后的数学原理。
这一章就到这结束了,但这并不代表着回归的结束,在其他章节结束后我们继续讨论更为高级的回归方式的原理与实现,而我们的下一章将讨论有关分类的内容。
Original: https://blog.csdn.net/qq_50459047/article/details/115568728
Author: 高星熠
Title: 手把手教会机器学习(三)——回归(基于Pandas)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/634722/
转载文章受原作者版权保护。转载请注明原作者出处!