

Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu and Tat-Seng Chua (2019). KGAT: Knowledge Graph Attention Network for Recommendation. Paper in ACM DL or Paper in arXiv. In KDD’19, Anchorage, Alaska, USA, August 4-8, 2019.
本文作者源码:https://github.com/xiangwang1223/knowledge_graph_attention_network
本人对KGCN的一些代码注释,有兴趣的道友可以看看
https://github.com/Archerxzs/KGAT-notes
文章最后附上本人对代码的解析
Abstract
为了更好的推荐,不仅要对user-item交互进行建模,还要将关系信息考虑进来
传统方法因子分解机将每个交互都当作一个独立的实例,但是忽略了item之间的关系(eg:一部电影的导演也是另一部电影的演员)
高阶关系:用一个/多个链接属性连接两个item
KG+user-item graph+high order relations—>KGAT
递归传播邻域节点(可能是users、items、attributes)的嵌入来更新自身节点的嵌入,并使用注意力机制来区分邻域节点的重要性
introduction
尽管 CF方法具有有效性和普遍性,但它 无法对辅助信息进行建模,例如项目属性、用户简档和上下文,因此在用户和项目很少交互的稀疏情况下表现不佳
解决方法:将 这些辅助信息转换成一个通用的特征向量,和userID和itemID输入到监督学习模型(SL)进行预测得分(常见模型:FM,NFM,Wide&Depp,xDeepFm)
仍然存在的问题:这些模型将每个交互都建模为一个独立的数据实例, 不考虑它们之间的关系,使得它们不能从用户的集体行为中提取协作信号


u1-[r1(Interact)]-i1-[r2(DirectedBy)]-e1
CF方法关注和i1有交互的相似user(u4,u5)
SL方法关注和e1有相同属性的相似item(i2)
期望:综上以上两种方法不仅可以对推荐进行互补,还使得user和item之间形成了高阶联系
但现有的SL方法不能将它们统一起来,并且无法考虑到高阶联系
(eg:黄圈中的u2,u3看的i2都是e1指导拍摄的,灰圈中的i3,i4和e1都有共同的关系,这两圈就被传统方法忽略了)

解决方法:
采用图中item的边信息(即knowledge graph)
knowledge graph+user-item graph–>collaborative knowledge graph协同知识图(CKG)
挑战:
1、节点会随着阶数的增加而急剧增加,会使得模型计算过载(选择多少邻居)
2、高阶关系对于预测的贡献不确定,需要模型来加权选择它们(邻居的重要性)
一些方法:
基于路径:提取携带高阶信息的路径,并将它们输入到预测模型中
路径选择算法:选择更重要的路径
定义元路径:需要大量领域知识
这两种路径选择方法没有对推荐目标进行优化
基于规则的:设计一个额外的损失项来捕获KG的结构来优化推荐模型的学习
目前存在的方法不是直接将高阶关系插入到优化推荐模型中,而是以隐式方法对它们进行编码,缺乏明确的建模,既不能保证捕捉到长期联系,也不能解释高阶建模的结果
GNN->KGAT
挑战:
1、递归嵌入传播,用领域节点嵌入来更新当前节点嵌入
2、使用注意力机制,来学习传播期间每个邻居的权重
优点:
1、与基于路径的方法相比,避免了人工标定路径
2、与基于规则的方法相比,将高阶关系直接融入预测模型
; Task Formulation
User-Item Bipartite Graph:
- G 1 = { ( u , y u i , i ) ∣ u ∈ U , i ∈ I } { U u s e r s e t I i t e m s e t y u i { 1 u 和 i 有 交 互 0 u 和 i 无 交 互 G_1\ ={(u,y_{ui},i)|u∈U,i∈I}\begin{cases} U \ \ \ user\ set \ I \ \ \ item\ set \ y_{ui}\begin{cases} 1 \ u和i有交互 \ 0 \ u和i无交互\end{cases} \end{cases}G 1 ={(u ,y u i ,i )∣u ∈U ,i ∈I }⎩⎪⎪⎪⎨⎪⎪⎪⎧U u s e r s e t I i t e m s e t y u i {1 u 和i 有交互0 u 和i 无交互
Knowledge Graph:item的信息(属性、外部知识)
例如一部电影可以用他的导演、演员、体裁等信息描述
(Hugh Jackman,ActorOf,Logan)
- G 2 = { ( h , r , t ) ∣ h , t ∈ ε , r ∈ R } G_2\ ={(h,r,t)|h,t∈\varepsilon,r∈R}G 2 ={(h ,r ,t )∣h ,t ∈ε,r ∈R }
Item-entity alignments set:
- $ A={(i,e)|i∈I,e∈\varepsilon}$
- i t e m i 对 应 于 e n t i t y e item\ i 对应于 entity\ e i t e m i 对应于e n t i t y e
Collaborative Knowledge Graph:将用户行为和项目知识编码为一个统一的关系图
- G = { ( h , r , t ) ∣ h , r ∈ ε ′ , r ∈ R ′ } G={(h,r,t)|h,r∈\varepsilon’,r∈R’}G ={(h ,r ,t )∣h ,r ∈ε′,r ∈R ′}
- ε ′ = ε ∪ U \varepsilon’=\varepsilon∪U ε′=ε∪U
- R ′ = R ∪ { I n t e r a c t } { I n t e r a c t } 为 额 外 的 关 系 R’=R∪{Interact}\ \ \ \ {Interact}为额外的关系R ′=R ∪{I n t e r a c t }{I n t e r a c t }为额外的关系
I n p u t : 协 作 知 识 图 G ( 包 括 G 1 和 G 2 ) Input:协作知识图G(包括G_1和G_2)I n p u t :协作知识图G (包括G 1 和G 2 )
O u t p u t : y ^ u i : u s e r u 是 否 会 交 互 i t e m i Output:\widehat{y}_{ui}:user\ u是否会交互item\ i O u t p u t :y u i :u s e r u 是否会交互i t e m i
High-Order Connectivity:
定义 L阶连通 :多跳关系的路径
e 0 r 1 > e 1 r 2 . . . r L > e L e_0\frac{r_1}{}>e_1\frac{r_2}{}…\frac{r_L}{}>e_L e 0 r 1 >e 1 r 2 …r L >e L ( e L ∈ ε ′ , r ∈ R ′ ) (e_L∈\varepsilon’\ ,r∈R’)(e L ∈ε′,r ∈R ′)
( e l − 1 , r l , e l ) 是 第 l 个 三 元 组 , L 是 序 列 的 长 度 (e_{l-1},r_l,e_l)是第l个三元组,L是序列的长度(e l −1 ,r l ,e l )是第l 个三元组,L 是序列的长度
CF方法是建立在用户行为的相似性的基础上,即相似的用户在项目上表现出更相似的偏好
u 1 r 1 > i 1 − r 1 > u 2 r 1 > i 2 u_1\frac{r_1}{}>i_1\frac{-r_1}{}>u_2\frac{r_1}{}>i_2 u 1 r 1 >i 1 −r 1 >u 2 r 1 >i 2
如上的连通路径会表现为u1可能对i2有偏好,因为u1的相似用户u2曾经对i2有过交互
SL方法更关注与相似属性的item
u 1 r 1 > i 1 r 2 > e 1 − r 2 > i 2 u_1\frac{r_1}{}>i_1\frac{r_2}{}>e_1\frac{-r_2}{}>i_2 u 1 r 1 >i 1 r 2 >e 1 −r 2 >i 2
如上的连通路径会表现为u1可能对i2有偏好,因为i2和之前喜欢的i1有相同的导演e1
但是很难对u 1 r 1 > i 1 r 2 > e 1 − r 3 > i 2 u_1\frac{r_1}{}>i_1\frac{r_2}{}>e_1\frac{-r_3}{}>i_2 u 1 r 1 >i 1 r 2 >e 1 −r 3 >i 2 进行建模,尽管有e1作为中间实体,但是和e1的关系是不一样
Methodology
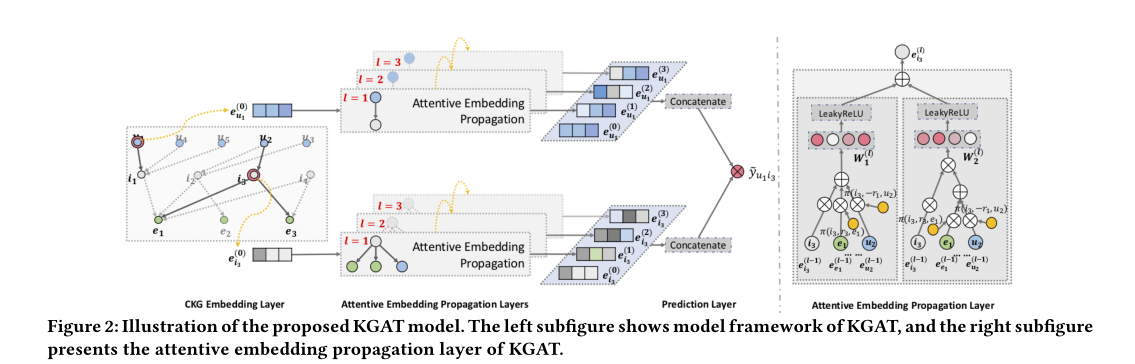
- 嵌入层,它通过保留CKG结构将每个节点参数化为一个向量
- 注意力嵌入传播层,其递归地传播来自节点的邻居的嵌入以更新其表示,并采用注意力机制来学习传播期间每个邻居的权重
- 预测层,其聚集来自所有传播层的用户和项目的表示,并输出预测的匹配分数。
; Embedding Layer
使用TransR
- e h r + e r ≈ e t r { e h , e r , e t 为 h , r , t 的 嵌 入 e h r , e t r 是 e h , e t 在 关 系 r 的 空 间 中 的 投 影 表 示 e^r_h+e_r≈e^r_t\begin{cases}e_h,e_r,e_t为h,r,t的嵌入\e^r_h,e^r_t是e_h,e_t在关系r的空间中的投影表示 \end{cases}e h r +e r ≈e t r {e h ,e r ,e t 为h ,r ,t 的嵌入e h r ,e t r 是e h ,e t 在关系r 的空间中的投影表示
- g ( h , r , t ) = ∣ ∣ W r e h + e r − W r e t ∣ ∣ 2 2 g(h,r,t)=||W_re_h+e_r-W_re_t||^2_2 g (h ,r ,t )=∣∣W r e h +e r −W r e t ∣∣2 2
- W r ∈ R k × d 关 系 r 的 变 换 矩 阵 , 使 得 e n t i t y 从 d 维 投 影 到 k 维 W_r∈\R^{k×d} 关系r的变换矩阵,使得entity从d维投影到k维W r ∈R k ×d 关系r 的变换矩阵,使得e n t i t y 从d 维投影到k 维
- 分数越低,说明三元组越可能为真
TransR训练需要考虑有效三元组和无效三元组的相对顺序,使用以下损失函数来区分
- L K G = Σ ( h , r , t , t ′ ) ∈ τ − l n σ ( g ( h , r , t ′ ) − g ( h , r , t ) ) L_{KG}=\Sigma_{(h,r,t,t’)∈\tau}-ln\sigma(g(h,r,t’)-g(h,r,t))L K G =Σ(h ,r ,t ,t ′)∈τ−l n σ(g (h ,r ,t ′)−g (h ,r ,t ))
- τ = ( h , r , t , t ′ ) ∣ ( h , r , t ) ∈ G , ( h , r , t ′ ) ∉ G \tau={(h,r,t,t’)|(h,r,t)∈G,(h,r,t’)∉G}τ=(h ,r ,t ,t ′)∣(h ,r ,t )∈G ,(h ,r ,t ′)∈/G
- ( h , r , t ′ ) 通 过 随 机 替 换 有 效 三 元 组 中 的 一 个 实 体 而 构 造 的 无 效 三 元 组 (h,r,t’)通过随机替换有效三元组中的一个实体而构造的无效三元组(h ,r ,t ′)通过随机替换有效三元组中的一个实体而构造的无效三元组
Attentive Embedding Propagation Layers
information propagation
一个实体可以包含在多个三元组中,充当连接两个三元组和传播信息的桥梁
eg:
e 1 r 2 > i 2 − r 1 > u 2 e_1\frac{r_2}{}>i_2\frac{-r_1}{}>u_2 e 1 r 2 >i 2 −r 1 >u 2
e 2 r 3 > i 2 − r 1 > u 2 e_2\frac{r_3}{}>i_2\frac{-r_1}{}>u_2 e 2 r 3 >i 2 −r 1 >u 2
i 2 i_2 i 2 通过将e 1 e_1 e 1 和e 2 e_2 e 2 的属性作为输入来丰富自身特征,然后贡献给u 2 u_2 u 2 去丰富自身
给 定 一 个 e n t i t y h , N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } 表 示 三 元 组 的 集 合 , 其 中 h 为 头 实 体 给定一个entity\ h,N_h={(h,r,t)|(h,r,t)∈G}表示三元组的集合,其中h为头实体给定一个e n t i t y h ,N h ={(h ,r ,t )∣(h ,r ,t )∈G }表示三元组的集合,其中h 为头实体
- e N h = Σ ( h , r , t ) ∈ N h π ( h , r , t ) e t e_{N_h}=\Sigma_{(h,r,t)∈N_h}\pi(h,r,t)e_t e N h =Σ(h ,r ,t )∈N h π(h ,r ,t )e t
- π ( h , r , t ) 控 制 三 元 组 每 次 传 播 的 衰 减 因 子 , 说 明 有 多 少 信 息 量 从 t 经 过 r 传 向 h \pi(h,r,t)控制三元组每次传播的衰减因子,说明有多少信息量从t经过r传向h π(h ,r ,t )控制三元组每次传播的衰减因子,说明有多少信息量从t 经过r 传向h
knowledge-aware attention
- π ( h , r , t ) = ( W r e t ) T t a n h ( ( W r e h + e r ) ) \pi(h,r,t)=(W_re_t)^Ttanh((W_re_h+e_r))π(h ,r ,t )=(W r e t )T t a n h ((W r e h +e r ))
注意力得分依赖于关系空间r上的e h e_h e h 和e t e_t e t 的距离(为更接近的实体传播更多的信息)
- π ( h , r , t ) = e x p ( π ( h , r , t ) ) Σ ( h , r ′ , t ′ ) ∈ N h e x p ( π ( h , r ′ , t ′ ) ) \pi(h,r,t)=\frac{exp(\pi(h,r,t))}{\Sigma_{(h,r’,t’)∈N_h}exp(\pi(h,r’,t’))}π(h ,r ,t )=Σ(h ,r ′,t ′)∈N h e x p (π(h ,r ′,t ′))e x p (π(h ,r ,t ))
和GCN、GraphSage将两个节点之间的衰减因子定义为1 ∣ N h ∣ ∣ N t ∣ o r 1 ∣ N t ∣ \frac{1}{\sqrt{|N_h||N_t|}}or\frac{1}{|N_t|}∣N h ∣∣N t ∣1 o r ∣N t ∣1 不同,本文模型不仅利用图的邻近结构,还规定了相邻节点的不同重要性,并且还将节点之间的关系进行建模,在传播过程中编码更多的信息
information aggregation
e h ( 1 ) = f ( e h , e N h ) { e h 实 体 表 示 e N h 邻 域 表 示 f ( ⋅ ) 聚 合 器 函 数 e_h^{(1)}=f(e_h,e_{N_h})\begin{cases}e_h\ 实体表示\ e_{N_h}\ 邻域表示\ f(·)\ 聚合器函数\end{cases}e h (1 )=f (e h ,e N h )⎩⎪⎨⎪⎧e h 实体表示e N h 邻域表示f (⋅)聚合器函数
- GCN Aggregator 两个向量相加,然后进行非线性转换:
- f G C N = L e a k y R e L U ( W ( e h + e N h ) ) f_{GCN}=LeakyReLU(W(e_h+e_{N_h}))f G C N =L e a k y R e L U (W (e h +e N h ))
- W ∈ R d ′ × d W∈\R^{d’×d}W ∈R d ′×d
- GraphSage Aggregator 两个向量连接,然后进行非线性转换:
- f G r a p h S a g e = L e a k y R e L U ( W ( e h ∣ ∣ e N h ) ) f_{GraphSage}=LeakyReLU(W(e_h||e_{N_h}))f G r a p h S a g e =L e a k y R e L U (W (e h ∣∣e N h ))
- Bi-Interaction Aggregator 考虑了e h e_h e h 和e N h e_{N_h}e N h 之间的两种特征交互
- f B i − I n t e r a c t i o n = L e a k y R e L U ( W 1 ( e h + e N h ) ) + L e a k y R e L U ( W 2 ( e h ⊙ e N h ) ) f_{Bi-Interaction}=LeakyReLU(W_1(e_h+e_{N_h}))+LeakyReLU(W_2(e_h ⊙ e_{N_h}))f B i −I n t e r a c t i o n =L e a k y R e L U (W 1 (e h +e N h ))+L e a k y R e L U (W 2 (e h ⊙e N h ))
- ⊙ 对应元素积,让相似的实体传递更多的信息
High-order Propagation
- e h ( l ) = f ( e h l − 1 , e N h l − 1 ) e^{(l)}h=f(e^{l-1}_h,e^{l-1}{N_h})e h (l )=f (e h l −1 ,e N h l −1 )
- e N h ( l − 1 ) = Σ ( h , r , t ) ∈ N h π ( h , r , t ) e t ( l − 1 ) e^{(l-1)}{N_h}=\Sigma{(h,r,t)∈{N_h}}\pi(h,r,t)e^{(l-1)}_t e N h (l −1 )=Σ(h ,r ,t )∈N h π(h ,r ,t )e t (l −1 )
- e t ( l − 1 ) 实 体 t 的 表 示 , 存 储 了 来 自 ( l − 1 ) 跳 的 邻 域 信 息 e^{(l-1)}_t\ 实体t的表示,存储了来自(l-1)跳的邻域信息e t (l −1 )实体t 的表示,存储了来自(l −1 )跳的邻域信息
- e h ( 0 ) e h 初 始 信 息 传 播 中 的 集 合 , 有 助 于 在 l 层 更 好 的 表 示 实 体 h e^{(0)}_h\ e_h初始信息传播中的集合,有助于在l层更好的表示实体h e h (0 )e h 初始信息传播中的集合,有助于在l 层更好的表示实体h
eg:
u 2 r 1 > i 2 − r 2 > e 1 r 2 > i 1 − r 1 > u 1 u_2\frac{r_1}{}>i_2\frac{-r_2}{}>e_1\frac{r_2}{}>i_1\frac{-r1}{}>u_1 u 2 r 1 >i 2 −r 2 >e 1 r 2 >i 1 −r 1 >u 1
u 2 u_2 u 2 的信息被编码在了e u 1 ( 3 ) e^{(3)}_{u_1}e u 1 (3 )中
Model Prediction
经过L层后,我们可以获得u s e r u user\ u u s e r u节点和i t e m i item\ i i t e m i节点的的多个表示
{ e u ( 1 ) , . . . , e u ( L ) } {e^{(1)}_u,…,e^{(L)}_u}{e u (1 ),…,e u (L )}
{ e i ( 1 ) , . . . , e i ( L ) } {e^{(1)}_i,…,e^{(L)}_i}{e i (1 ),…,e i (L )}
采用层聚合机制将每一步的表示连接成一个向量:
e u ∗ = e u 0 ∣ ∣ ⋅ ⋅ ⋅ ∣ ∣ e u L e i ∗ = e i 0 ∣ ∣ ⋅ ⋅ ⋅ ∣ ∣ e i L e^_u=e^{0}_u||···||e^{L}_u\e^_i=e^{0}_i||···||e^{L}_i e u ∗=e u 0 ∣∣⋅⋅⋅∣∣e u L e i ∗=e i 0 ∣∣⋅⋅⋅∣∣e i L
上述操作,不仅可以通过执行嵌入传播来丰富初始嵌入,还可以通过调整L L L来加强传播
通 过 u s e r 和 i t e m 的 表 示 的 内 积 来 预 测 : 通过user和item的表示的内积来预测:通过u s e r 和i t e m 的表示的内积来预测:
y ^ ( u , i ) = ( e u ∗ ) T e i ∗ \widehat{y}(u,i)=(e^_u)^Te^_i y (u ,i )=(e u ∗)T e i ∗
Optimization
BPR Loss:观察到的交互(表示更多的用户偏好)应该比未观察到的交互赋予更高的预测值
L C F = Σ ( u , i , j ) ∈ O − l n σ ( y ^ ( u , i ) − y ^ ( u , j ) ) { O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } 训 练 集 R + u s e r u 和 i t e m i 的 正 交 互 R − u s e r u 和 i t e m i 的 负 交 互 L_{CF}=\Sigma_{(u,i,j)∈O}-ln\sigma(\widehat{y}(u,i)-\widehat{y}(u,j))\begin{cases}O={(u,i,j)|(u,i)∈R^+,(u,j)∈R^-}\ 训练集\ R^+\ user \ u 和item \ i 的正交互 \ R^-\ user \ u 和item \ i 的负交互\end{cases}L C F =Σ(u ,i ,j )∈O −l n σ(y (u ,i )−y (u ,j ))⎩⎪⎨⎪⎧O ={(u ,i ,j )∣(u ,i )∈R +,(u ,j )∈R −}训练集R +u s e r u 和i t e m i 的正交互R −u s e r u 和i t e m i 的负交互
最终的Loss:
L K G A T = L K G + L C F + λ ∣ ∣ Θ ∣ ∣ 2 2 L_{KGAT}=L_{KG}+L_{CF}+\lambda||\Theta||^2_2 L K G A T =L K G +L C F +λ∣∣Θ∣∣2 2
Θ : 模 型 参 数 集 \Theta:模型参数集Θ:模型参数集
Experiments
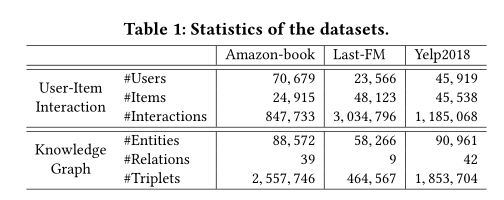
Dataset
Baseline
{ K G A T S L ( F M , N F M ) r e g u l a r i z a t i o n − b a s e d ( C F K G , C K E ) p a t h − b a s e d ( M C R e c , R i p p l e N e t ) g r a p h n e u r a l n e t w o r k − b a s e d ( G C − M C ) \begin{cases}KGAT\ SL(FM,NFM)\regularization-based(CFKG,CKE)\path-based(MCRec,RippleNet)\graph\ neural\ network-based(GC-MC)\end{cases}⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧K G A T S L (F M ,N F M )r e g u l a r i z a t i o n −b a s e d (C F K G ,C K E )p a t h −b a s e d (M C R e c ,R i p p l e N e t )g r a p h n e u r a l n e t w o r k −b a s e d (G C −M C )
{ F M 将 u s e r I D 和 i t e m I D 以 及 它 们 的 知 识 作 为 输 入 特 征 , 其 考 虑 输 入 之 间 的 二 阶 特 征 交 互 N F M 将 F M 放 在 在 神 经 网 络 上 , 在 输 入 特 征 上 使 用 一 个 隐 藏 层 C K E 通 过 T r a n s R 得 到 的 语 义 嵌 入 来 增 加 矩 阵 分 解 C F K G 在 用 户 、 项 目 、 实 体 、 关 系 的 统 一 图 上 使 用 T r a n s E , 将 推 荐 任 务 当 作 ( u s e r , i n t e r a c t , i ) 的 预 测 M C R e c 提 取 合 格 的 元 路 径 作 为 用 户 和 项 目 之 间 的 连 接 R i p p l e N e t 通 过 在 其 他 用 户 的 路 径 的 项 目 信 息 来 丰 富 自 身 表 示 G C − M C 使 用 G C N 编 码 \begin{cases}FM\ 将userID和itemID以及它们的知识作为输入特征,其考虑输入之间的二阶特征交互\ NFM\ 将FM放在在神经网络上,在输入特征上使用一个隐藏层\ CKE\ 通过TransR得到的语义嵌入来增加矩阵分解\CFKG\ 在用户、项目、实体、关系的统一图上使用TransE,将推荐任务当作(user,interact,i)的预测\ MCRec\ 提取合格的元路径作为用户和项目之间的连接\ RippleNet\ 通过在其他用户的路径的项目信息来丰富自身表示\GC-MC\ 使用GCN编码\end{cases}⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧F M 将u s e r I D 和i t e m I D 以及它们的知识作为输入特征,其考虑输入之间的二阶特征交互N F M 将F M 放在在神经网络上,在输入特征上使用一个隐藏层C K E 通过T r a n s R 得到的语义嵌入来增加矩阵分解C F K G 在用户、项目、实体、关系的统一图上使用T r a n s E ,将推荐任务当作(u s e r ,i n t e r a c t ,i )的预测M C R e c 提取合格的元路径作为用户和项目之间的连接R i p p l e N e t 通过在其他用户的路径的项目信息来丰富自身表示G C −M C 使用G C N 编码
CG的两个思想:
1、高关联度的结果比一般关联度的结果更影响最终的指标得分;
2、有高关联度的结果出现在更靠前的位置的时候,指标会越高;
- CG(累计增益): 只考虑到了相关性的关联程度,没有考虑到位置的因素。它是一个搜素结果相关性分数的总和
- $CG_p=\Sigma_{i=1}^p rel_i,rel_i 代表i这个位置上的相关度 $
- 假设搜索”篮球”结果,最理想的结果是:B1、B2、 B3。而出现的结果是 B3、B1、B2的话,CG的值是没有变化的
- DCG(折损累计增益): 是在每一个CG的结果上处以一个折损值,目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低
- D C G p = Σ i = 1 p r e l i l o g 2 ( i + 1 ) DCG_p=\Sigma_{i=1}^p \frac{rel_i}{log_2(i+1)}D C G p =Σi =1 p l o g 2 (i +1 )r e l i
- $DCG_P=\Sigma_{i=1}p\frac{2{rel_i}-1}{log_2(i+1)},用来增加相关度影响比重的DCG计算方式 $
- NDCG(归一化折损累计增益): 由于搜索结果随着检索词的不同,返回的数量是不一致的,而DCG是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理
- n D C G p = D C G p I D C G p , I D C G 为 理 想 情 况 下 最 大 的 D C G 的 值 nDCG_p=\frac{DCG_p}{IDCG_p},IDCG为理想情况下最大的DCG的值n D C G p =I D C G p D C G p ,I D C G 为理想情况下最大的D C G 的值
eg:返回6个结果,其相关性分数分别为3,2,3,0,1,2
C G = 3 + 2 + 3 + 0 + 1 + 2 CG=3+2+3+0+1+2 C G =3 +2 +3 +0 +1 +2
D C G = 3 / l o g 2 ( 1 + 1 ) + 2 / l o g 2 ( 2 + 1 ) + . . . + 2 / l o g 2 ( 6 + 1 ) = 6.86 DCG=3/log_2(1+1)+2/log_2(2+1)+…+2/log_2(6+1)=6.86 D C G =3 /l o g 2 (1 +1 )+2 /l o g 2 (2 +1 )+…+2 /l o g 2 (6 +1 )=6 .8 6
假设我们实际召回8个物品,除了上面6个, 还有两个结果,假设第7个相关性为3,第8个相关性为0。那么在理想情况下的相关性分数排序应该是:3、3、3、2、2、1、0、0
I D C G @ 6 = 3 / l o g 2 ( 1 + 1 ) + 3 / l o g 2 ( 2 + 1 ) + . . . + 1 / l o g 2 ( 6 + 1 ) = 8.37 IDCG@6=3/log_2(1+1)+3/log_2(2+1)+…+1/log_2(6+1)=8.37 I D C G @6 =3 /l o g 2 (1 +1 )+3 /l o g 2 (2 +1 )+…+1 /l o g 2 (6 +1 )=8 .3 7
N D C G @ 6 = 6.86 / 8.37 = 81.96 % NDCG@6=6.86/8.37=81.96\%N D C G @6 =6 .8 6 /8 .3 7 =8 1 .9 6 %
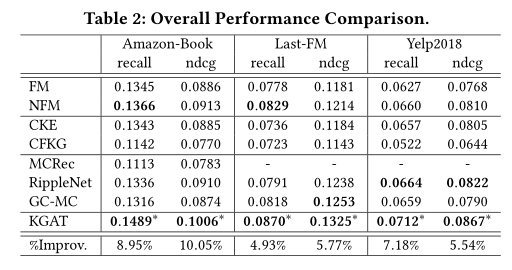
- KGAT在所有数据集上都有最佳性能,通过叠加多个注意力机制的嵌入传播层,KGAT能够以显式的方法探索高阶连通性,从而有效捕获协作信号,并且和GC-MC相比,证明了注意力机制的有效。
- SL(FM,NFM)在大多数情况下比regularization-based(CFKG,CKE)取得更好的性能,说明regularization-based方法没有充分利用项目知识
- RippleNet和FM相比证明了合并两跳邻域节点对于丰富自身表示的重要性,而和NFM相比,前两个数据集较略微逊色,而在最后一个数据集效果较好,因为NFM允许NFM去捕获用户、项目、实体之间的非线性、复杂的特征交互
- RippleNet的表现远远好于MCRec,MCRec严重依赖元路径的质量,需要大量的领域知识来定义
- GC-MC和RippleNet在Last-FM和Yelp2018数据集上表现相当,但是在Amazon-Book上,GC-MC比RippleNet差,因为GC-MC没有关注节点之间的语义关系
; 性能和矩阵稀疏性的关联
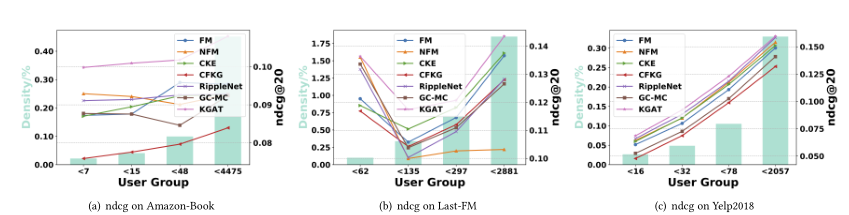
- 证明高阶连通建模的重要性,KGAT在较为稀疏的Amazon-Book和Last-Fm中的性能要优于其他模型,因为递归嵌入传播丰富了低活跃用户的表示
- 在Yelp2018的性能要轻微优于某些基准,是因为太多的交互引入了太多的噪声造成了负面影响
KGAT对用户偏好推荐的解释
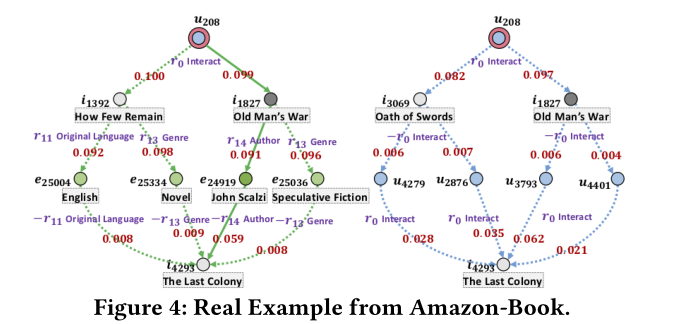
(左)基于属性 (右)基于行为
- u 208 r 0 > O l d M a n ′ s W a r r 14 > J o h n S c a l z i − r 14 > i 4293 u_{208}\frac{r_0}{}>Old\ Man’s\ War\frac{r_{14}}{}>John\ Scalzi\frac{-r_{14}}{}>i_{4293}u 2 0 8 r 0 >O l d M a n ′s W a r r 1 4 >J o h n S c a l z i −r 1 4 >i 4 2 9 3
- 上述路径具有最高的注意力分数,所以可以生成一个解释i 4293 i_{4293}i 4 2 9 3 被推荐的原因是因为看过O l d M a n ′ s W a r Old\ Man’s\ War O l d M a n ′s W a r
- KG的质量也很重要,左图中的Original Language和English太过笼统无法提供高质量的解释
数据集:
train.txt: userId,itemId(list)
test.txt: userId,itemId(list)
user_list.txt: org_id,remap_id(原数据集ID、本文使用ID)
item_list.txt: org_id,remap_id,freebase_id(原数据集ID、本文使用ID、freebaseID)
entity_list.txt: freebase_id,remap_id(freebaseID、本文使用ID)
item_list里面的数据包含在entity_list中
以Last-FM为例:
Items有48123,那么item_list.txt有48123行(单纯的音乐item)
Entitys有58266,那么entity_list.txt有48123+58266=106389行(音乐item+外部信息(如作词作曲?))
relation_list.txt: freebase_id,remap_id(freebaseID、本文使用ID)
freebase_id 是不重要的,只要管remap_id
kg_final.txt: entityId、relationId、entityId
第一列和第三列都是entity的id(音乐、作词、作曲)
例如:
孤独之书 原唱 房东的猫
房东的猫 职业 歌手
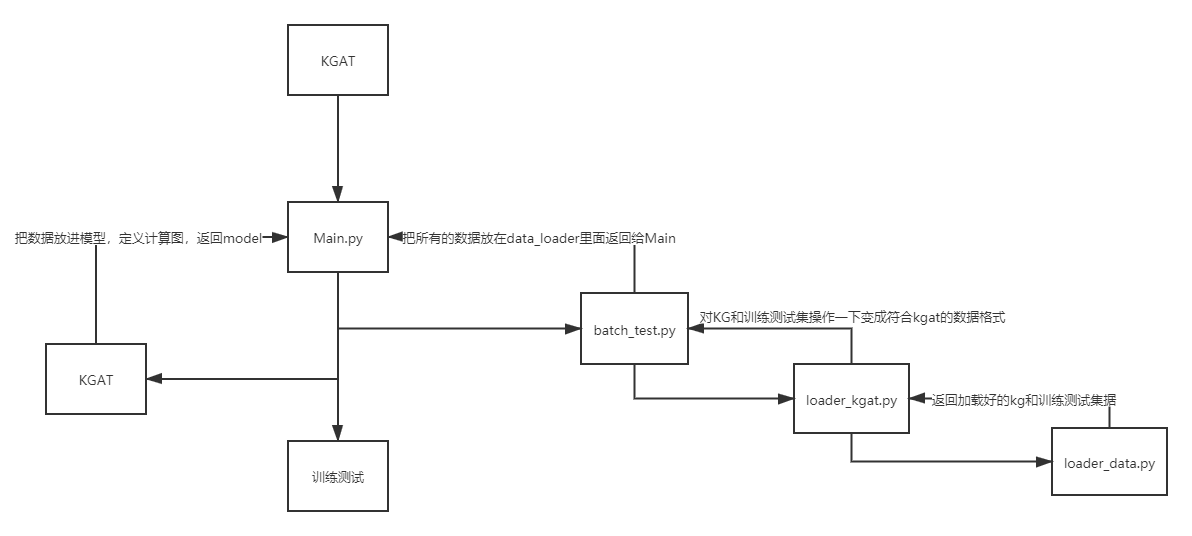
; 代码大赏
python -u Main.py --model_type kgat --alg_type bi --dataset last-fm --regs [1e-5,1e-5] --layer_size [64,32,16] --embed_size 64 --lr 0.0001 --epoch 1000 --verbose 50 --save_flag 1 --pretrain -1 --batch_size 1024 --node_dropout [0.1] --mess_dropout [0.1,0.1,0.1] --use_att True --use_kge True
先运行的batch_test.py
load_data.py
Data:(Last-Fm)
- train_data、test_data:[ [ u s e r I d , i t e m I d ] , [ u s e r I d , i t e m I d ] . . . ] ( n p . a r r a y ) [[userId,itemId],[userId,itemId]…](np.array)[[u s e r I d ,i t e m I d ],[u s e r I d ,i t e m I d ]…](n p .a r r a y )
- train_user_dict、test_user_dict:u s e r I d : [ i t e m I d , i t e m I d , . . . ] , u s e r I d : [ i t e m I d , i t e m I d , . . . ] ( d i c t ) {userId:[itemId,itemId,…],userId:[itemId,itemId,…]}(dict)u s e r I d :[i t e m I d ,i t e m I d ,…],u s e r I d :[i t e m I d ,i t e m I d ,…](d i c t )
- exist_user:t r a i n _ d a t a 中 的 所 有 u s e r I d [ u s e r I d 1 , u s e r I d 2 , . . . . ] train_data中的所有userId\ [userId1,userId2,….]t r a i n _d a t a 中的所有u s e r I d [u s e r I d 1 ,u s e r I d 2 ,….]
- n_users:23566
- n_items:48123
- n_relations:9–>20
- n_entities:106389(item+辅助item)
- n_triples:464567
- kg_data:[ [ h e a d , r e l a t i o n , t a i l ] , [ h e a d , r e l a t i o n , t a i l ] , . . . ] [[head,relation,tail],[head,relation,tail],…][[h e a d ,r e l a t i o n ,t a i l ],[h e a d ,r e l a t i o n ,t a i l ],…]
- kg_dict:{ ” h e a d ” : [ ( t a i l , r e l a t i o n ) , ( t a i l , r e l a t i o n ) , . . . ] , ” h e a d ” : [ ( t a i l , r e l a t i o n ) , ( t a i l , r e l a t i o n ) , . . . ] , . . . } {“head”:[(tail,relation),(tail,relation),…],”head”:[(tail,relation),(tail,relation),…],…}{“h e a d “:[(t a i l ,r e l a t i o n ),(t a i l ,r e l a t i o n ),…],”h e a d “:[(t a i l ,r e l a t i o n ),(t a i l ,r e l a t i o n ),…],…}
- head除了包括item还包括辅助item的id
- relation_dict:{ ” r e l a t i o n ” : [ ( h e a d , t a i l ) , ( h e a d , t a i l ) , . . . ] , ” r e l a t i o n ” : [ ( h e a d , t a i l ) , ( h e a d , t a i l ) , . . . ] , . . . } {“relation”:[(head,tail),(head,tail),…],”relation”:[(head,tail),(head,tail),…],…}{“r e l a t i o n “:[(h e a d ,t a i l ),(h e a d ,t a i l ),…],”r e l a t i o n “:[(h e a d ,t a i l ),(h e a d ,t a i l ),…],…}
loader_kgat.py
KGAT_loader:
1、_get_relational_adj_list():生成user-item和item-item的交互矩阵和关系id列表
- _np_mat2sp_adj(np_mat, row_pre, col_pre):np_mat是数据,row_pre和col_pre分别是行列初始的位置;这个函数作用是为了生成矩阵,并且返回的矩阵互为转置矩阵
- adj_mat_list:长度为20,其中前2个是user-item的交互矩阵(第0个和第1个互为转置矩阵);后面18个是item和item的交互矩阵(根据关系的种类来分,假设第一种关系为”作曲”,那么第2和第3个矩阵就是关系为”作曲”的头尾实体组成的矩阵,第二种关系为”作词”,那么第4和第5个矩阵就是。。。。以此类推)
- adj_r_list:长度为20,第0个和第1个的数值是”0″和”10″,代表了user-item的关系(也就是”交互”),其余的都为item-item的关系(比如第2和第3个都是”作曲”,数值是”1″和”11″,第2和第12个都是”作词”,数值是”2″和”12″。。。。)
2、_get_relational_lap_list():生成拉普拉斯矩阵
- _bi_norm_lap(adj):对每一个矩阵A(adj)进行归一化,生成拉普拉斯矩阵;先算出度矩阵D(rowsum),然后对D做处理,没值的赋0,然后铺在对角线,最后对adj进行对称归一化,生成拉普拉斯矩阵
- _si_norm_lap(adj):和上面差不多意思
- lap_list:长度20,就是 adj_mat_list的归一化后的结果
3、_get_all_kg_dict():对拉普拉斯矩阵循环遍历,得到一个三元组字典
- all_kg_dict:dict 长度为129955,得到一个{head:[(tail,relation),(tail,relation),…],head:[(tail,relation),(tail,relation),…],…}
4、_get_all_kg_data():
lap_list[0]的情况:
l_id=0
lap= (0, 23678) 0.008849557522123894
(0, 23677) 0.008849557522123894
(0, 23676) 0.008849557522123894
(0, 23675) 0.008849557522123894
(0, 23674) 0.008849557522123894
(0, 23673) 0.008849557522123894
(0, 23672) 0.008849557522123894
(0, 23671) 0.008849557522123894
(0, 23670) 0.008849557522123894
(0, 23669) 0.008849557522123894
(0, 23668) 0.008849557522123894
(0, 23667) 0.008849557522123894
(0, 23666) 0.008849557522123894
(0, 23665) 0.008849557522123894
(0, 23664) 0.008849557522123894
(0, 23663) 0.008849557522123894
(0, 23662) 0.008849557522123894
(0, 23661) 0.008849557522123894
(0, 23660) 0.008849557522123894
(0, 23659) 0.008849557522123894
(0, 23658) 0.008849557522123894
(0, 23657) 0.008849557522123894
(0, 23656) 0.008849557522123894
(0, 23655) 0.008849557522123894
(0, 23654) 0.008849557522123894
: :
(23564, 45288) 0.08333333333333333
(23564, 45263) 0.08333333333333333
(23564, 45257) 0.08333333333333333
(23564, 30637) 0.08333333333333333
(23565, 71676) 0.047619047619047616
(23565, 71083) 0.047619047619047616
(23565, 52920) 0.047619047619047616
(23565, 51952) 0.047619047619047616
(23565, 47716) 0.047619047619047616
(23565, 43140) 0.047619047619047616
(23565, 40048) 0.047619047619047616
(23565, 36810) 0.047619047619047616
(23565, 35981) 0.047619047619047616
(23565, 34215) 0.047619047619047616
(23565, 31039) 0.047619047619047616
(23565, 30923) 0.047619047619047616
(23565, 29301) 0.047619047619047616
(23565, 29258) 0.047619047619047616
(23565, 29200) 0.047619047619047616
(23565, 29088) 0.047619047619047616
(23565, 28949) 0.047619047619047616
(23565, 25744) 0.047619047619047616
(23565, 25691) 0.047619047619047616
(23565, 25433) 0.047619047619047616
(23565, 24748) 0.047619047619047616
rows=[ 0 0 0 … 23565 23565 23565]
cols=[23678 23677 23676 … 25691 25433 24748]
all_h_list、all_t_list、all_v_list、all_r_list的情况
len(all_h_list)=3507140
len(all_t_list)=3507140
len(all_v_list)=3507140
len(all_r_list)=3507140
str(all_h_list[0:9])=[0, 0, 0, 0, 0, 0, 0, 0, 0]
str(all_t_list[0:9])=[23678, 23677, 23676, 23675, 23674, 23673, 23672, 23671, 23670]
str(all_v_list[0:9])=[0.008849557522123894, 0.008849557522123894, 0.008849557522123894, 0.008849557522123894, 0.008849557522123894, 0.008849557522123894, 0.008849557522123
894, 0.008849557522123894, 0.008849557522123894]
str(all_r_list[0:9])=[0, 0, 0, 0, 0, 0, 0, 0, 0]
- all_h_list:排序过的全部头实体id =3507140
- all_r_list:排序过的全部关系实体id =3507140
- all_t_list:排序过的全部尾实体id =3507140
- all_v_list:排序过的全部数据 =3507140
KGAT.py
- _parse_args():解析参数
- _build_inputs():定义输入变量
- _build_weights():定义权重偏置等
- _build_model_phase_I():根据选择的聚合器去聚合向量
- self.ua_embeddings, self.ea_embeddings:分别是最终的user和item向量
- _build_loss_phase_I():定义CF的损失
- _build_model_phase_II():图嵌入的计算
- _build_loss_phase_II():图嵌入的损失
- _statistics_params():统计参数数量8427280
Original: https://blog.csdn.net/Caster_X/article/details/109448685
Author: 默默然咯
Title: KGAT_基于知识图谱+图注意力网络的推荐系统(KG+GAT)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/558016/
转载文章受原作者版权保护。转载请注明原作者出处!