

SEU:从对齐到分配—-简单有效的无监督实体对齐
《From Alignment to Assignment:Frustratingly Simple Unsupervised Entity Alignment》
论文地址:https://arxiv.org/pdf/2109.02363.pdf
相关博客:
【自然语言处理】【知识图谱】利用属性、值、结构来实现实体对齐
【自然语言处理】【知识图谱】基于图匹配神经网络的跨语言知识图谱对齐
【自然语言处理】【知识图谱】使用属性嵌入实现知识图谱间的实体对齐
【自然语言处理】【知识图谱】用于实体对齐的多视角知识图谱嵌入
【自然语言处理】【知识图谱】MTransE:用于交叉知识对齐的多语言知识图谱嵌入
【自然语言处理】【知识图谱】SEU:无监督、非神经网络实体对齐超越有监督图神经网络?
一、简介
- 知识图谱 知识图谱已经被广泛用于推荐系统、问答系统等下游的任务中。近些年,由不同的组织使用不同的语言在不同领域构建了大量的知识图谱。这些交叉语言知识图谱通常具有独特的信息,但也存在着一些覆盖。如果能够集成这些交叉语言知识图谱,那么就能够为那些缺乏语言资源的用户提供更广阔的视角。因此,交叉语言知识图谱吸引了越来越多的注意力。
- 传统实体对齐 交叉语言实体对齐的目标是,发现知识图谱中的等价实体。传统的方法主要依靠词汇匹配和概率推理,但需要机器翻译系统来解决交叉语言问题。但是,现有的机器翻译系统在有效上下文信息的情况下,并不能实现高的准确率。特别是对于那些不相似的语言,例如Chinese-English \text{Chinese-English}Chinese-English和Japanese-English \text{Japanese-English}Japanese-English。
- 图神经网络实体对齐 最近,GCN \text{GCN}GCN及其变体已经在各种图相关的应用中取得了state-of-the-art的结果。直觉上,GNN \text{GNN}GNN能够更好的捕获知识图谱的结构信息。一些基于GNN \text{GNN}GNN的实体对齐方法确实明显地改善了公开数据集上的效果。所有基于GNN \text{GNN}GNN的实体对齐方法都基于一个核心假设,即需要对齐的实体对具有相似的局部结构。然而,基于GNN \text{GNN}GNN的方法在带来优秀结果的同时,也不可避免地继承了神经网络的缺点:
- 糟糕的解释性 集合了非线性运算和大量参数的GNN \text{GNN}GNN方法难以被解释。因此,许多研究人员将GNN \text{GNN}GNN当做是黑盒,并只专注于提高性能指标。这种风气导致很难判断新的设计是真的有效,还是仅仅在特定数据集上过拟合。近期的一些研究表明,一些先进的实体对齐方法在若干个公开数据集上被传统方法打败。
- 效率低 为了改进效果,新的实体对齐方法堆叠了大量的新技术,例如:图注意力网络、图匹配网络和联合训练等。因此,整个架构变的越来越复杂,导致时间和空间复杂度显著增加。
- 本文贡献 本文尝试在不损失准确率的情况下,消除现有实体对齐方法的冗余设计来增强解释性和效率。基于假设:源和目标KG \text{KG}KG的结构和文本特征是同构的,本文成功将实体对齐问题转换为分配问题。分配问题是一个基础的且被很好研究的组合优化问题,可以通过Hungarian \text{Hungarian}Hungarian算法或者Sinkhorn \text{Sinkhorn}Sinkhorn算法求解。 基于上面的发现,本文提出了使用神经网络的实体对齐方法SEU \text{SEU}SEU。相比于基于GNN \text{GNN}GNN的实体对齐方法,SEU \text{SEU}SEU仅保留了用于特征传播的基础图卷积操作,抛弃了复杂的神经网络。在公开数据集上的实验结果显示:
- 在GPU \text{GPU}GPU上,SEU \text{SEU}SEU能在若干秒内完成;即使在CPU \text{CPU}CPU上,也能在数十秒内完成;
- SEU \text{SEU}SEU 在几乎所有公开数据集上都超越了有监督的state-of-the-art方法; 此外,本文还讨论了现有的实体对齐方法表现不佳的原因,以及交叉语言实体对齐中的神经网络的必要性。
二、任务定义
知识图谱以三元组( h , r , t ) (h,r,t)(h ,r ,t )的形式存储了真实世界的知识。一个知识图谱可以被定义为G = ( E , R , T ) G=(E,R,T)G =(E ,R ,T ),其中分别表示实体集合、关系集合和三元组集合。给定一个源图谱G s = ( E s , R s , T s ) G_s=(E_s,R_s,T_s)G s =(E s ,R s ,T s )和目标图谱G t = ( E t , R t , T t ) G_t=(E_t,R_t,T_t)G t =(E t ,R t ,T t ),实体对齐的目标是发现两个图谱监督的对应关系P \textbf{P}P。
三、相关工作
1. 分配问题
分配问题是一个基础的且被很好研究的组合优化问题。一个简单的例子:为N个工人分配N个工作。假设每个工人都能够在规定时间段内完成每项工作,令x i j x_{ij}x i j 表示第i i i个工人被分配到第j j j项工作收益。分配问题的目标是寻找最优的分配计划,使得所有工作的收益最大化。该问题的求解形式化的定义为
a r g m a x P ∈ P N ⟨ P , X ⟩ F (1) \mathop{arg\;max}_{\textbf{P}\in\mathbb{P}_N}\langle \textbf{P},\textbf{X} \rangle_F \tag{1}a r g ma x P ∈P N ⟨P ,X ⟩F (1 )
X ∈ R N × N \textbf{X}\in\mathbb{R}^{N\times N}X ∈R N ×N是收益矩阵;P \textbf{P}P是排列矩阵,表示分配计划。P \textbf{P}P中的每行或者每列仅有一个1,其余均为0。P N \mathbb{P}_N P N 表示所有N维排列矩阵的集合。⟨ ⋅ ⟩ F \langle\cdot\rangle_F ⟨⋅⟩F 表示Frobenius \text{Frobenius}Frobenius内积。
本文采用Hungarian \text{Hungarian}Hungarian算法和Sinkhorn \text{Sinkhorn}Sinkhorn算法解决分配问题。
四、 SEU \text{SEU}SEU
1. 对齐问题的分配建模
方法SEU \text{SEU}SEU的输入为四个矩阵:A s ∈ R ∣ E s ∣ × ∣ E s ∣ \textbf{A}_s\in\mathbb{R}^{|E_s|\times |E_s|}A s ∈R ∣E s ∣×∣E s ∣和A t ∈ R ∣ E t ∣ × ∣ E t ∣ \textbf{A}_t\in\mathbb{R}^{|E_t|\times |E_t|}A t ∈R ∣E t ∣×∣E t ∣表示源图谱G s G_s G s 和目标图谱G t G_t G t 的邻接矩阵。H s ∈ R ∣ E s ∣ × d \textbf{H}_s\in\mathbb{R}^{|E_s|\times d}H s ∈R ∣E s ∣×d和H t ∈ R ∣ E t ∣ × d \textbf{H}_t\in\mathbb{R}^{|E_t|\times d}H t ∈R ∣E t ∣×d表示实体的文本特征,该特征通过机器翻译系统或者交叉语言词嵌入向量映射至了统一语义空间。
类似于分配问题,实体对齐也需要满足1-to-1 \text{1-to-1}1-to-1约束。令排列矩阵P ∈ P ∣ E ∣ \textbf{P}\in\mathbb{P}{|E|}P ∈P ∣E ∣表示G s G_s G s 和G t G_t G t 间的实体对应,P i j = 1 \textbf{P}{ij}=1 P i j =1表示e i ∈ G s e_i\in G_s e i ∈G s 和e j ∈ G t e_j\in G_t e j ∈G t 是相等的实体对。SEU \text{SEU}SEU的目标是根据{ A s , A t , H s , H t } {\textbf{A}_s,\textbf{A}_t,\textbf{H}_s,\textbf{H}_t}{A s ,A t ,H s ,H t }求解P \textbf{P}P。考虑下面的理想情况:
- A s \textbf{A}_s A s 和A t \textbf{A}_t A t 是同构的,即根据P \textbf{P}P重新排序A s \textbf{A}_s A s 的节点能够转换为A t \textbf{A}_t A t
PA s P − 1 = A t (2) \textbf{PA}_s\textbf{P}^{-1}=\textbf{A}_t \tag{2}PA s P −1 =A t (2 ) - 等价实体的文本特征能够被翻译系统完美映射。因此,H s \textbf{H}_s H s 和H t \textbf{H}_t H t 也可以根据实体对应的P \textbf{P}P来被对齐,
PH s = H t (3) \textbf{PH}_s=\textbf{H}_t \tag{3}PH s =H t (3 )
通过合并等式( 2 ) (2)(2 )和( 3 ) (3)(3 ),五元组{ A s , A t , H s , H t , P } {\textbf{A}s,\textbf{A}_t,\textbf{H}_s,\textbf{H}_t,\textbf{P}}{A s ,A t ,H s ,H t ,P }的关系如下:
( PA s P − 1 ) l PH s = A t l H t ∀ l ∈ N ⇒ PA s l H s = A t l H t (4) (\textbf{PA}_s\textbf{P}^{-1})^l\textbf{PH}_s=\textbf{A}_t^l\textbf{H}_t\quad \forall l\in \mathbb{N} \ \Rightarrow\quad\textbf{PA}_s^l\textbf{H}_s=\textbf{A}_t^l\textbf{H}_t \tag{4}(PA s P −1 )l PH s =A t l H t ∀l ∈N ⇒PA s l H s =A t l H t (4 )
在一对一约束P ∈ P ∣ E ∣ \textbf{P}\in\mathbb{P}{|E|}P ∈P ∣E ∣的条件下,等式( 4 ) (4)(4 )中的P \textbf{P}P可以通过最小化Frobenius \text{Frobenius}Frobenius ∥ PA s l H s − A t l H t ∥ \parallel \textbf{PA}s^l\textbf{H}_s-\textbf{A}_t^l\textbf{H}_t \parallel ∥PA s l H s −A t l H t ∥求解。理论上,对于任意深度l ∈ N l\in\mathbb{N}l ∈N,P \textbf{P}P的解应该都相同的。然而,上面的推断都是基于理想同构条件的。但是,实际中G s G_s G s 和G t G_t G t 并不是严格同构的,且翻译系统并不能完美的将文本特征映射至统一语义空间。为了减少实际中噪音的影响,P \textbf{P}P应该拟合各种深度的l l l。因此,本文提出了下面的等式来解决交叉语言实体对齐问题
arg min P ∈ P ∣ E ∣ ∑ l = 0 L ∥ PA s l H s − A t l H t ∥ F 2 (5) \mathop{\text{arg min}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L\parallel \textbf{PA}_s^l\textbf{H}_s-\textbf{A}_t^l\textbf{H}_t \parallel_F^2 \tag{5}arg min P ∈P ∣E ∣l =0 ∑L ∥PA s l H s −A t l H t ∥F 2 (5 )
定理1
等式( 5 ) (5)(5 )等价于解决下面的分配问题
arg max P ∈ P ∣ E ∣ ⟨ P , ∑ l = 0 L A t l H t ( A s l H s ) T ⟩ F (6) \mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}} \Big\langle \textbf{P},\sum_{l=0}^L\textbf{A}_t^l\textbf{H}_t(\textbf{A}_s^l\textbf{H}_s)^T \Big\rangle_F\tag{6}arg max P ∈P ∣E ∣⟨P ,l =0 ∑L A t l H t (A s l H s )T ⟩F (6 )
证明:
基于Frobenius \text{Frobenius}Frobenius方式的性质∥ A-B ∥ F 2 = ∥ A ∥ F 2 + ∥ B ∥ F 2 − 2 ⟨ A,B ⟩ F \parallel \textbf{A-B} \parallel_F^2=\parallel\textbf{A}\parallel_F^2+\parallel\textbf{B}\parallel_F^2-2\langle\textbf{A,B}\rangle_F ∥A-B ∥F 2 =∥A ∥F 2 +∥B ∥F 2 −2 ⟨A,B ⟩F ,对等式( 5 ) (5)(5 )进行如下推导
arg min P ∈ P ∣ E ∣ ∑ l = 0 L ∥ PA s l H s − A t l H t ∥ F 2 = arg min P ∈ P ∣ E ∣ ∑ l = 0 L ∥ PA s l H s ∥ F 2 + ∥ A t l H t ∥ F 2 − 2 ⟨ PA s l H s , A t l H t ⟩ (7) \begin{aligned} &\mathop{\text{arg min}}{\textbf{P}\in\mathbb{P}{|E|}}\sum_{l=0}^L\parallel \textbf{PA}s^l\textbf{H}_s-\textbf{A}_t^l\textbf{H}_t \parallel_F^2 \ =&\mathop{\text{arg min}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L\parallel\textbf{PA}s^l\textbf{H}_s\parallel_F^2+\parallel\textbf{A}_t^l\textbf{H}_t\parallel_F^2-2\langle\textbf{PA}_s^l\textbf{H}_s,\textbf{A}_t^l\textbf{H}_t\rangle \end{aligned} \tag{7}=arg min P ∈P ∣E ∣l =0 ∑L ∥PA s l H s −A t l H t ∥F 2 arg min P ∈P ∣E ∣l =0 ∑L ∥PA s l H s ∥F 2 +∥A t l H t ∥F 2 −2 ⟨PA s l H s ,A t l H t ⟩(7 )
由于排列矩阵P \textbf{P}P是正交的,所以∥ PA s l H s ∥ F 2 \parallel\textbf{PA}_s^l\textbf{H}_s\parallel_F^2 ∥PA s l H s ∥F 2 和∥ A t l H t ∥ F 2 \parallel\textbf{A}_t^l\textbf{H}_t\parallel_F^2 ∥A t l H t ∥F 2 是常数。因此,等式( 7 ) (7)(7 )等价于
arg max P ∈ P ∣ E ∣ ∑ l = 0 L ⟨ PA s l H s , A t l H t ⟩ F (8) \mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L\langle \textbf{PA}s^l\textbf{H}_s,\textbf{A}_t^l\textbf{H}_t \rangle_F \tag{8}arg max P ∈P ∣E ∣l =0 ∑L ⟨PA s l H s ,A t l H t ⟩F (8 )
对于任意的实数矩阵A \textbf{A}A和B \textbf{B}B,有两个恒成立的等式:⟨ A,B ⟩ F = Tr ( AB T ) \langle\textbf{A,B}\rangle_F=\text{Tr}(\textbf{AB}^T)⟨A,B ⟩F =Tr (AB T )和⟨ A,B+C ⟩ F = ⟨ A,B ⟩ F + ⟨ A,C ⟩ F \langle \textbf{A,B+C} \rangle_F=\langle\textbf{A,B}\rangle_F+\langle\textbf{A,C}\rangle_F ⟨A,B+C ⟩F =⟨A,B ⟩F +⟨A,C ⟩F ,其中Tr ( X ) \text{Tr}(\textbf{X})Tr (X )表示矩阵X \textbf{X}X的迹。因此,定理1可以被证明:
arg max P ∈ P ∣ E ∣ ∑ l = 0 L ⟨ PA s l H s , A t l H t ⟩ F = arg max P ∈ P ∣ E ∣ ∑ l = 0 L Tr ( PA s l H s ( A t l H t ) T ) = arg max P ∈ P ∣ E ∣ ∑ l = 0 L ⟨ P , A t l H t ( A s l H s ) T ⟩ F = arg max P ∈ P ∣ E ∣ ⟨ P , ∑ l = 0 L A t l H t ( A s l H s ) ⟩ (9) \begin{aligned} &\mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L\langle\textbf{PA}s^l\textbf{H}_s,\textbf{A}_t^l\textbf{H}_t\rangle_F \ =&\mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L \text{Tr}(\textbf{PA}s^l\textbf{H}_s(\textbf{A}_t^l\textbf{H}_t)^T)\ =&\mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}}\sum{l=0}^L \langle\textbf{P},\textbf{A}t^l\textbf{H}_t(\textbf{A}_s^l\textbf{H}_s)^T\rangle_F\ =&\mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}{|E|}}\Big\langle \textbf{P},\sum{l=0}^L\textbf{A}_t^l\textbf{H}_t(\textbf{A}_s^l\textbf{H}_s) \Big\rangle \end{aligned} \tag{9}===arg max P ∈P ∣E ∣l =0 ∑L ⟨PA s l H s ,A t l H t ⟩F arg max P ∈P ∣E ∣l =0 ∑L Tr (PA s l H s (A t l H t )T )arg max P ∈P ∣E ∣l =0 ∑L ⟨P ,A t l H t (A s l H s )T ⟩F arg max P ∈P ∣E ∣⟨P ,l =0 ∑L A t l H t (A s l H s )⟩(9 )
通过定理1,成功将实体对齐问题转换为分配问题。需要注意的是,实体规模∣ E s ∣ |E_s|∣E s ∣和∣ E t ∣ |E_t|∣E t ∣在实践中通常是不一致的,导致收益矩阵不是方阵。这种不平衡分配的问题能够轻易转换为平衡分配问题。假设∣ E s ∣ > ∣ E t ∣ |E_s|>|E_t|∣E s ∣>∣E t ∣,一个朴素的简化方法是使用0来填充收益矩阵,使其形状成为R ∣ E s ∣ × ∣ E s ∣ \mathbb{R}^{|E_s|\times|E_s|}R ∣E s ∣×∣E s ∣。这种朴素的方法适合于∣ E s ∣ |E_s|∣E s ∣和∣ E t ∣ |E_t|∣E t ∣差距较小的数据集。对于差距较大的数据集,可以使用更高效的简化算法https://www.hpl.hp.com/techreports/2012/HPL-2012-40R1.pdf。
2. 求解分配问题
解决分配问题的第一个多项式时间复杂度算法是Hungarian \text{Hungarian}Hungarian算法,其原始的复杂度为O ( n 4 ) O(n^4)O (n 4 )。后来的一些改进将时间复杂度降低为O ( n 3 ) O(n^3)O (n 3 )。
除了Hungarian \text{Hungarian}Hungarian算法,分配问题还可以看作是最优运输问题的特例。在最优运输问题中,分配计划P \textbf{P}P可以是随机矩阵。基于Sinkhorn \text{Sinkhorn}Sinkhorn操作,Cuturi \text{Cuturi}Cuturi等人提出了一个快速且完全并行的算法来解决最优运输问题。
S 0 ( X ) = e x p ( X ) S k ( X ) = N c ( N r ( S k − 1 ( X ) ) ) Sinkhorn ( X ) = l i m k → ∞ S k ( X ) \begin{aligned} S^0(\textbf{X})&=exp(\textbf{X}) \ S^k(\textbf{X})&=\mathcal{N}c(\mathcal{N}_r(S^{k-1}(\textbf{X}))) \ \text{Sinkhorn}(\textbf{X})&=\mathop{lim}{k\rightarrow\infty}S^k(\textbf{X}) \end{aligned}S 0 (X )S k (X )Sinkhorn (X )=e x p (X )=N c (N r (S k −1 (X )))=l im k →∞S k (X )
其中,N r ( X ) = X ⊘ ( X 1 N 1 N T ) \mathcal{N}r(\textbf{X})=\textbf{X}\oslash(\textbf{X}\textbf{1}_N\textbf{1}_N^T)N r (X )=X ⊘(X 1 N 1 N T )和N c = X ⊘ ( 1 N 1 N T X ) \mathcal{N}_c=\textbf{X}\oslash(\textbf{1}_N\textbf{1}_N^T\textbf{X})N c =X ⊘(1 N 1 N T X )是矩阵行和列元素规范化操作,⊘ \oslash ⊘是element-wise除法。然后,Mena \text{Mena}Mena等人进一步证明了分配问题能够作为最优运输问题的特例,然后使用Sinkhorn \text{Sinkhorn}Sinkhorn操作进行求解。
arg max P ∈ P N ⟨ P,X ⟩ F = l i m τ → 0 + Sinkhorn ( X / τ ) \begin{aligned} \mathop{\text{arg max}}{\textbf{P}\in\mathbb{P}N}\langle \textbf{P,X} \rangle_F \ =\mathop{lim}{\tau\rightarrow0^+}\text{Sinkhorn}(\textbf{X}/\tau) \end{aligned}arg max P ∈P N ⟨P,X ⟩F =l im τ→0 +Sinkhorn (X /τ)
一般来说,Sinkhorn \text{Sinkhorn}Sinkhorn操作的时间复杂度是O ( k n 2 ) O(kn^2)O (k n 2 )。由于迭代数目k k k是有限的,实践中Sinkhorn \text{Sinkhorn}Sinkhorn操作通常能够获得近似解。基于实践的经验,非常小的k k k就能在实体对齐上实现好的表现。因此,Sinkhorn \text{Sinkhorn}Sinkhorn算法的实际时间复杂度为O ( n 2 ) O(n^2)O (n 2 )。
五、实现细节
1. 文本特征 H \textbf{H}H
- Word-level 先前的实体对齐工作中,最常使用的文本特征是词级别的实体名称向量。具体来说,这些方法会使用机器翻译系统或者交叉语言词嵌入将实体名称映射至统一语义空间,然后平均预训练实体名称向量来构造初始特征。为了公平比较,本文采用相同的实体名称和词向量。
- Char-level 由于专有名词之间存在广泛的矛盾以及词表的有限尺寸。单词级别的实体对齐方法遭受严重的OOV \text{OOV}OOV问题。因此,许多实体对齐方法通过char-CNN \text{char-CNN}char-CNN或者name-BERT \text{name-BERT}name-BERT来使用字符级别的特征。为了保持SEU \text{SEU}SEU的简单性和一致性,采用翻译后实体名称的字符bigram作为输入特征,而不使用复杂的神经网络。
2. 邻接矩阵 A \textbf{A}A
上面所有的推论都是建立在邻接矩阵A s \textbf{A}s A s 和A t \textbf{A}_t A t 是同构的。显然,令D \textbf{D}D为邻接矩阵A s / t \textbf{A}{s/t}A s /t 的度矩阵,等概率随机游走矩阵A r = D − 1 A s / t \textbf{A}r=\textbf{D}^{-1}\textbf{A}{s/t}A r =D −1 A s /t 和对称归一化Laplacian \text{Laplacian}Laplacian矩阵A L = I − D − 1 / 2 A s / t D − 1 / 2 \textbf{A}L=\textbf{I}-\textbf{D}^{-1/2}\textbf{A}{s/t}\textbf{D}^{-1/2}A L =I −D −1 /2 A s /t D −1 /2也是同构的。因此,A s / t \textbf{A}{s/t}A s /t 被替换为A r \textbf{A}_r A r 或者A L \textbf{A}_L A L ,本文顶点方法也是有效的。然而,上面的矩阵忽略了知识图谱中的关系,即所有类型的关系都同等重要。直觉上,低频关系应该有更高的权重,因为他们能够表示更加独特的信息。依据这个直觉,应用简单的策略来生成关系邻接矩阵A r e l \textbf{A}{rel}A r e l ,对应a i j ∈ A r e l a_{ij}\in\textbf{A}{rel}a i j ∈A r e l :
a i j = ∑ r j ∈ R i , j ln ( ∣ T ∣ / ∣ T r j ∣ ) ∑ k ∈ N i ∑ r k ∈ R i , k ln ( ∣ T ∣ / ∣ T r k ∣ ) \textbf{a}{ij}=\frac{\sum_{r_j\in R_{i,j}}\text{ln}(|T|/|T_{r_j}|)}{\sum_{k\in\mathcal{N}i}\sum{r_k\in R_{i,k}}\text{ln}(|T|/|T_{r_k}|)}a i j =∑k ∈N i ∑r k ∈R i ,k ln (∣T ∣/∣T r k ∣)∑r j ∈R i ,j ln (∣T ∣/∣T r j ∣)
其中,N i \mathcal{N}i N i 表示实体e i e_i e i 的邻居集合,R i , j R{i,j}R i ,j 是实体e i e_i e i 和e j e_j e j 间的关系,∣ T ∣ |T|∣T ∣和∣ T r ∣ |T_r|∣T r ∣分别表示所有三元组的总数和包含关系r r r的三元组数量。
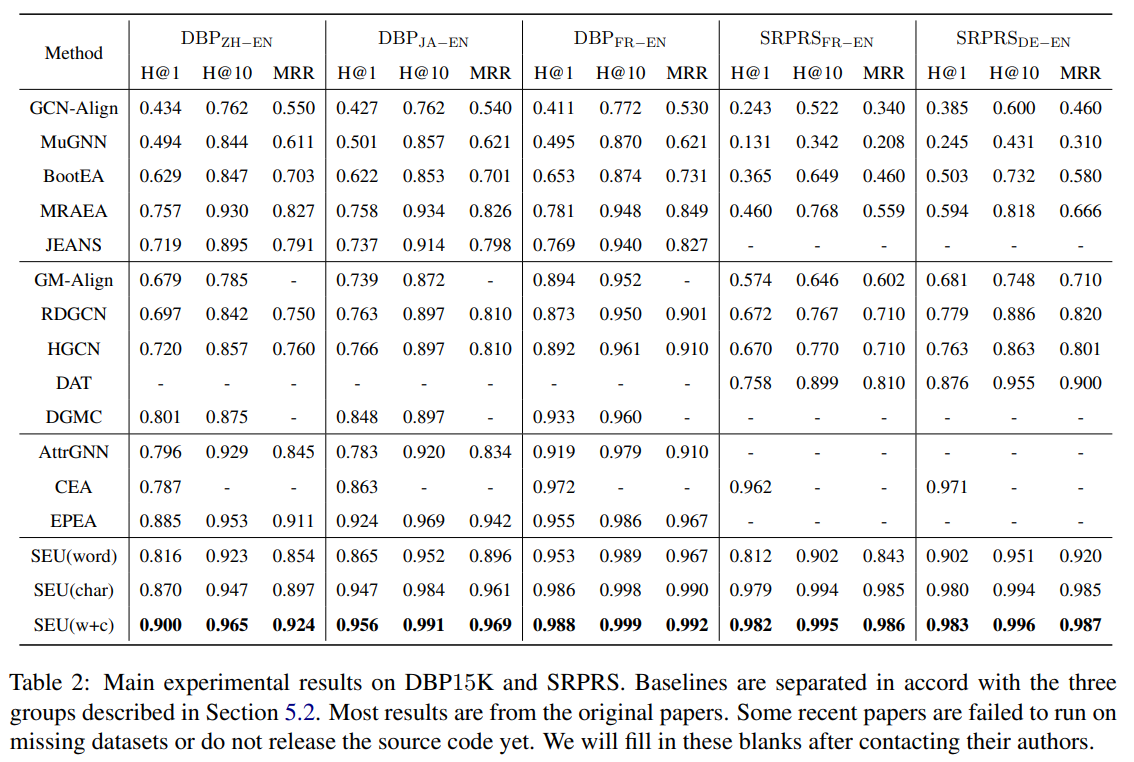
六、实验结果

Original: https://blog.csdn.net/bqw18744018044/article/details/123769088
Author: BQW_
Title: 【自然语言处理】【知识图谱】SEU:无监督、非神经网络实体对齐超越有监督图神经网络?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531149/
转载文章受原作者版权保护。转载请注明原作者出处!