

张若禹 北京大学
编者按 :
本文《A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions》是发表于IJCAL 2021 Survey Track的一篇综述文章。文章首先总结了知识库问答(KBQA)的任务背景和两类主流方法,然后详细探讨了这些方法的瓶颈挑战与解决方案,最后对未来可能的研究方向做出了展望。


论文地址:
https://arxiv.org/abs/2105.11644
-前言-
知识图谱问答( Knowledge Base Question Answering)旨在通过外部的知识库回答自然语言问题。近年来,大量的研究逐渐转向对语法上或者语义上复杂问题的解答。本文总结了复杂知识库问答的典型挑战和解决方案。首先,我们将介绍KBQA的任务背景和针对复杂知识库问答的两种主流方法, 即基于语义解析(Semanticparsing,SP)的方法和基于信息检索(Informationretrieval,IR)的方法。对于这两类方法,我们将介绍其中的前沿策略和相应的挑战。最后,我们总结并讨论了一些仍具有挑战的未来研究方向。
-问题介绍-
知识库(Knowledge Base)是一类结构化图数据库的统称,它以(主体、关系、客体)的三元组形式表征现实中存在的事实。一些大规模的知识库,如Freebasee [Bollacker et al., 2008],DBPedia[Lehmann et al., 2015] 和Wikidata [Tanon et al., 2016]在此前被构建并服务于下游任务。知识图谱问答( Knowledge Base Question Answering)旨在通过外部的知识库回答自然语言问题。早期的KBQA工作关注于对简单问题的解答。近年来,研究人员开始更多地关注于回答复杂问题 [Huet al., 2018b; Luo et al., 2018]。 复杂问题一般涉及多跳推理、约束关系、数值运算。图一中就是对于复杂问题解答的一个示例。
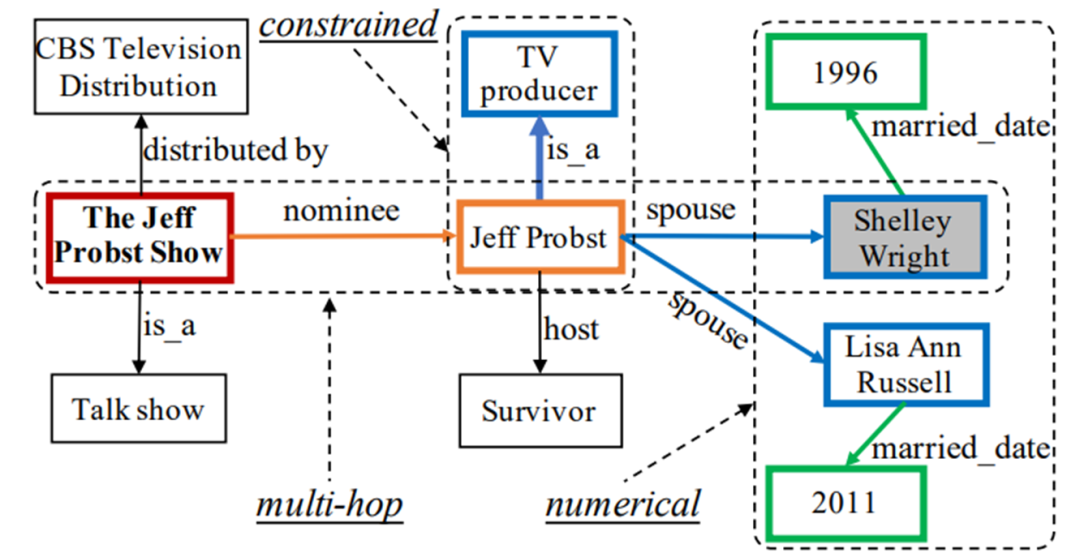
图1:对于复杂KBQA问题 “Who is the first wife of TVproducer that was nominated for The Jeff Probst Show?“的解答的推理过程。在这个例子中包含了多跳推理、约束关系、数值计算等逻辑过程。
对于简单KBQA问题,此前的研究已经形成了两类主流的解决方案, 即基于语义解析(Semanticparsing,SP)的方法和基于信息检索(Informationretrieval,IR)的方法。前者将自然语言问题转换成对应的符号逻辑形式,并在知识库上进行查询得到答案;后者则从知识库中提取一个问题相关的子图,然后根据与问题的相关性对抽取的子图中的所有实体进行排序。
但是,在面对复杂KBQA时,这两类问题都各自面临挑战。我们认为主要挑战如下:
- 现有基于SP的方法中所用的解析器(parser)难以覆盖 多样的复杂查询(如多跳推理、约束关系、数值运算)。类似地,之前的基于IR的方法也可能无法回答复杂查询,因为它们的排序是在缺乏可视化推理的情况下对小范围内的实体执行的;
- 在复杂问题中, 更多的关系和主题实体意味着更大的潜在逻辑形式的搜索空间,这将显著增加计算成本。更多的关系和主题实体同样会妨碍基于IR的方法检索所有相关实体进行排序;
- 两种方法都把问题理解作为主要步骤。当问题在语义和句法方面都变得复杂时,就要求模型具有 较强的自然语言理解能力和泛化能力;
- 对于复杂问题,为答案标记正确的推理路径(参见图1中的例子)代价非常高昂。通常,数据集只提供问题的正确答案。这意味着基于SP的方法和基于IR的方法需要分别在没有正确逻辑形式和推理路径标注的情况下进行训练。这种 弱监督模式给两种方式都带来了困难。
-问题背景-
问题定义。复杂KBQA任务以一个包含大量事实的KB和复杂自然语言问题作为输入。我们假定正确答案来自于KB的实体集。不同于简单问题中答案实体直接与主题实体在KB中相连,复杂问题中答案可能在主题实体的多跳之外,甚至包含一些聚合操作。
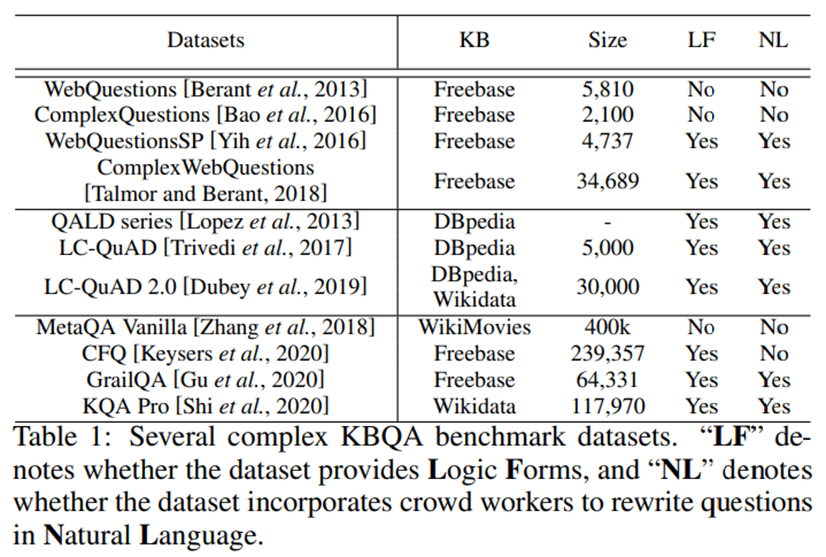
数据集。表1中列举了现有的复杂KBQA数据集。这些数据集一般通过如下步骤构建:一,给定KB中的一个主题实体,通过模板构建围绕该实体的简单问题;二,在简单问题的基础上通过模板生成复杂问题(有些工作 [Shi et al., 2020] 同时生成了对应的逻辑形式)和答案。有时候,研究者会使用众包的形式重写生成的问题以使其更流畅多样。为了贴合现实场景,这些数据集通常使用许多KB事实进行推理,并涵盖了数值运算(如计数、排序或比较)和约束条件(如实体、时序关系),以提高推理难度。
验证指标。KBQA系统一般选取置信度最高的实体组成答案集合。注意,预测集合和正确集合中都可能存在多个元素。之前的工作一般使用准确率(precision)、召回率(recall)、 _F1_分数、 _Hits@1_等作为评价指标。
主要方法
基于SP的和基于IR的方法是两种主流解决方案。语义解析方法将自然语言问题解析成对应的逻辑形式,并在知识库上进行查询得到答案;信息检索方法从知识库中提取一个问题相关的子图,然后根据与问题的相关性对抽取的子图中的所有实体进行排序。总而言之,这
两种方法分别遵循”解析-执行”和”检索-排序”范式。
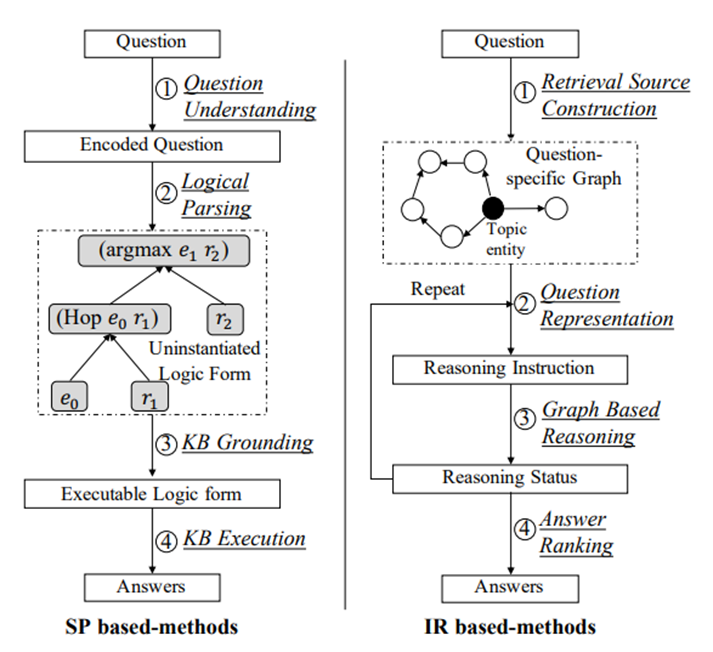
图2:两种方法的说明。各步骤如图所示。
基于语义解析的方法。[Berant and Liang, 2014; Reddy et al., 2014] 这类方法通过如下步骤预测答案:(1)通过 _问题理解_模块对自然语言问题进行语义和语法上的分析,并为后续解析步骤编码原始问题;(2)通过 _逻辑解析_模块将编码过的问题转化成未实例化(即没有链接到KB中的实体和关系)的逻辑形式;(3)通过 _知识库链接_将逻辑形式实例化,并与相应的KB做语义对齐;(4)最终通过 _知识库查询_得到预测答案。
基于信息抽取的方法。[Bordes et al., 2015; Dong et al., 2015] 这类方法通过如下步骤预测答案:(1)从主题实体开始,从KB中抽取查询相关的子图。在理想情况下,子图应该包含所有与问题相关的实体和关系构成图的结点和边;(2)通过 _问题表示_模块编码自然语言问题;(3)通过 _图推理_模块对结点信息进行传播和聚合,得到实体表示;(4)通过 _答案排序_模块选取得分最高的实体结点作为问题的答案。
总体上看,基于SP的方法通过生成逻辑形式可以得到可解释性更强的推理过程。但是,这类方法严重依赖于逻辑形式的设计和解析器算法的质量,这同时也是进一步提升表现的瓶颈;基于IR的方法自然地契合端到端(end-to-end)的训练过程,使得训练更容易。但是,这种黑盒式推理也降低了推理的可解释性。
-挑战和解决策略-
一、基于语义解析的方法
在前文中我们已经介绍过了基于SP的方法采用的四个主要步骤。这些模块各自面临不同的挑战。
- 理解复杂语义和语法。在基于SP的方法的第一步问题理解中,需要将自然语言问题转化成结构化表示进行进一步的解析。相比于简单问题,复杂问题包含更复杂的查询类型和复合语义,从而进一步增大了问题理解的难度。为了缓解这个问题,许多现行的方法使用语法解析(syntactic parsing)信息,如依存句法树 [Abujabal etal., 2017; Abujabal et al., 2018; Luo et al., 2018] 和抽象意义表示(Abstract Meaning Representation,AMR)[Kapanipathi et al., 2020],使问题成分与逻辑形式更好地对齐。但是,对于复杂问题,特别是长距离依赖问题的语法解析准确度存在不足。为了缓解语法解析的错误回传,Sun et al. [2020] 使用了骨干解析将复杂问题分解为简单问题的分支。另一类方法关注于利用逻辑形式的结构性质(如树结构或图结构)对候选解析结果进行打分。研究者们通过尝试使用结构特征编码器[Zhu et al., 2020],细粒度插槽匹配 [Maheshwariet al., 2019],添加查询结构相关的约束条件以过滤错误查询 [Chen et al., 2020] 从而更好地匹配自然语言问题和逻辑形式;
- 解析复杂查询。传统的方法可以很好地解析简单问题,如CCG [Cai and Yates, 2013; Kwiatkowski et al., 2013; Reddy et al.,2014]。但是,由于本体错误匹配的问题 [Yih et al., 2015],这些方法可能不能很好地适用于复杂问题。因此,在解析阶段利用KB的结构是非常必要的。为了满足复杂问题的各种特征,研究者提出了多种逻辑结构作为解析目标。Bast and Haussmann [2015] 设计了三种模板,可以表征单跳、两跳和带有一条对于关系的限制的问题。这个设计显然不能覆盖许多复杂问题。Yih et al. [2015] 提出了 _查询图_作为解析目标。查询图是一种与KB数据库模式相匹配的图状结构,在复杂KBQA任务中展现了强大的表达能力。但是,这种查询图的生成过程通常依赖于人工预定义规则,不能很好地适用于大规模数据集和长尾复杂查询类型。为了缓解这一问题,Ding et al. [2019] 提出了通过利用高频出现的查询的子结构辅助查询生成。Abujabalet al. [2017] 利用了语义标注提高查询图的结构复杂性。Hu et al. [2018b] 应用了更多的聚合操作(如合并)和共指消歧技术以适应复杂问题;
- 链接中巨大的搜索空间。知识库链接将逻辑形式实例化,形成可执行查询。由于KB中的实体可能连接了成百上千条边,因此搜索所有可能的逻辑形式会造成高昂的计算代价和时间开销。研究者们提出了多种策略解决这一问题。Zheng et al. [2018b] 将复杂问题分解为简单问题,分别解析其对应的逻辑形式,执行得到中间查询结果,并根据这些中间结果得到最终答案。这一”分解-执行-合并”策略可以有效缩减搜索空间。Bhutaniet al. [2019] 也采用了类似的策略,并利用依存句法关系减少了人工标注。同时,其他的一些工作采用了”扩展-排序”策略,使用集束搜索缩减搜索空间。Chen et al. [2019] 首先采用了每跳贪心搜索生成查询图。Lan et al. [2019c] 提出使用迭代匹配模块解析问题。这种策略只适用于多跳问题,而不能很好地处理约束条件和数值计算。Lan and Jiang [2020] 为三种典型复杂查询定义了更多操作,从而极大地缩减了搜索空间;
- 弱监督训练。基于强化学习的优化策略被广泛应用于训练数据不足或受限的场景[Liang et al., 2017; Qiu et al., 2020b]。在这种场景下,模型只能在查询执行后得到最终反馈,使得奖励稀疏且数据不足。为了解决这些问题,一些工作对于解析结果使用了 _奖励构造_策略。Saha et al. [2019] 在模型生成与正确答案相同类型的实体时提供了额外的奖励。Hua et al. [2020b] 在评价生成的逻辑形式时将其与之前缓存的高奖励逻辑形式相对比,并对中间结果也提供了奖励。Qiu et al. [2020b] 将查询图生成定义为分层决定问题,并基于分层强化学习和内在性质提供中间奖励。为了加速、稳定训练过程,他们同时使用伪正确结果(人工规则生成的高奖励结果)对模型进行预训练。考虑到这些结果同样可由模型生成,Liang et al. [2017] 提出使用迭代最大似然估计自举训练,并维护伪正确结果。
二、基于信息检索的方法
类似的,基于IR的方法的模块也各自面临不同的挑战。
- 知识库的不完整性。基于IR的方法首先需要从KB中抽取问题相关的子图,再在此基础上进行推理。简单问题只要求单跳推理,因此较少遇到这种问题。但在复杂问题中,这个问题可能变得非常严重,正确的推理路径甚至可能没有包含在我们抽取的子图之中。并且,这种不完整性还使得编码实体时邻居信息的传递效率降低,为推理带来了额外的难度。为了解决这一问题,研究者们尝试利用额外信息扩充知识来源。直觉上,从Wikipedia中提取的问题相关的文本语料可以提供大量非结构化知识辅助推理。Sunet al. [2018] 和Sun et al. [2019] 提出使用与问题相关的文本语句补全知识库子图形成一个异构图,并在此异构图上进行推理。Xiong et al. [2019] 和 Han et al. [2020a] 提出将文本信息与结点表示融合从而提供辅助知识。他们首先在问题基础上编码文本和实体,然后通过聚合句子表示以改善实体表示。除了文本语料外,知识库嵌入也被用以预测知识库的缺失关系,缓解知识库的稀疏性。受到KB补全任务的启发,Saxena et al. [2020] 利用预训练的知识库嵌入扩充实体表示并解决KB的不完整性问题;
- 理解复杂语义。一般来说,基于IR的方法通过神经网络(如LSTM)直接将问题编码成低维向量生成推理指令。这种生成的静态推理指令不能有效表示复杂问题的组合语义。为了有效理解问题,最近的工作动态地在推理阶段更新推理指令。为了关注推理时尚未分析的问题成分,Miller et al. [2016],Zhou et al. [2018] 和 Xu et al. [2019] 提出在推理阶段使用信息检索更新推理指令。He etal. [2021] 提出使用动态注意力机制关注问题的不同成分。这种机制可以促进模型关注问题传达的其他信息,并为后续推理步骤提供指导。除了分解问题语义的思路以外,Sun et al. [2018] 提出用图的上下文信息来增强问题的表示。他们通过每步聚合来自主题实体的信息更新推理指令;
- 推理的不可解释性。传统的基于IR的方法通过计算问题和实体的语义相似度进行排序,这种模式下中间过程的可解释性不强。由于复杂问题往往涉及多条事实,系统需要更透明的推理过程才能更好地预测答案。多跳推理是提高推理的透明度的一种方法。Zhou et al. [2018] 和 Xu et al. [2019] 提出让每步预测的关系或实体可追溯和观察。他们输出中间预测结果作为可解释的推理路径。但是,这种方法不能完全利用关系的语义信息进行边到边的推理。因此,Han et al. [2020b] 通过确定一组由相同关系连接的实体构造了一个更稠密的”超图”,以模拟人的每步关系推理过程并输出序列化的关系路径使得推理过程可解释;
- 弱监督训练。类似于基于SP的方法,在弱监督的情况下,模型缺乏中间结果的标注,会使得奖励信号稀疏,训练难度更大。这种情况会导致虚假推理的问题出现 [He et al., 2021]。为了缓解这一问题,Qiu et al.[2020a] 将推理过程形式化定义为在KB上扩展推理路径的过程,并采用奖励构造策略提供中间奖励。为了检验每步的推理路径,他们使用了问题和推理路径的语义相似度提供反馈。在此之外,一个更直接的想法是导出伪中间状态并利用这些信号辅助训练。受到图上双向搜索策略的启发,He et al. [2021] 提出通过同步双向推理过程学习中间推理实体分布。但是,少有研究者关注实体链接步骤。研究者们利用现有的工具定位主题实体,这可能会对后续推理产生错误回传问题。为了在没有标注的情况下精确定位主题实体,Zhang et al. [2018] 提出通过变分学习算法联合建模主题实体识别和后续推理以训练实体链接模块。
-结论及未来工作展望-
本文试图为复杂 KBQA 的典型挑战和相应的解决方案提供一个全面的视角。我们介绍了常用的数据集并总结了基于 SP 的方法以及基于 IR 的方法。现有的复杂 KBQA 方法一般都可归为这两类。除此之外,还有一些其他方法,例如,Talmor 和 Berant [2018] 将一个复杂的问题通过规则分解为多个简单问题的组合,这种方法关注于问题分解而不是基于知识库的推理或逻辑形式生成。我们相信复杂的KBQA 仍然是一个前景良好的研究领域。
但是,本篇综述中提出的许多挑战仍然是开放问题,亟待探索。在此我们指出了几个可能的未来研究方向:
- 渐进式的KBQA系统。现存的方法大多先线下在数据集上训练,然后部署上线回答用户问题。这种泾渭分明的两阶段设计不能适应现实世界中的知识的爆炸性增长速度,从而不能很好地回答新问题。用户的反馈可能为KBQA系统提供改善的机会。Abujabal et al. [2018] 使用用户反馈纠正答案并进一步提升。Zheng et al. [2018a] 设计了一种交互性的方法使得用户直接参与解析过程。在未来,渐进式的KBQA系统是使得线上系统表现持续改善的关键;
- 鲁棒性与可解释性。现存的方法在假数据设独立同分布的数据集上取得了良好的表现,但却不能很好地回答分布外的问题。在少量学习(few-shot learning)的场景下,只有小规模的可用的训练数据。之前的一些研究 [Hua et al., 2020a; He et al., 2021] 对此问题略有探讨,但还远远没有分析具体的挑战并给出解决方案。组合泛化(compositional generalization)是另一个典型的场景,其中一些推理元素在训练集中高频出现。为了支持这个领域的更多研究工作,Gu et al. [2020] 和 Keysers et al. [2020] 提出了相关的数据集GrailQA和CFQ。模型期望能够处理分布外的数据,进行可视化的推理过程。设计可解释的和鲁棒的KBQA算法也是未来研究的重要方向;
- 更多通用知识库。由于知识库的不完整性,研究者们常常引入额外信息补全知识库以提升复杂KBQA的表现。也有一些其他的任务(如图像问答、常识回答)可以被形式化定义成建立在不同KB上的KBQA问题。例如,在图像问答中,从图片中提取的场景图(scene graph)可以被认为是一种特殊的KB [Hudson and Manning, 2019]。除了由显式的结构化知识构成的KB以外,一些研究者还提出在隐式的知识库上进行推理。Petroni et al. [2019] 分析了预训练模型中的关系化知识,一些后续的工作 [Bouraoui et al., 2020; Jiang et al., 2020] 进一步证明了这在完形填空任务中的有效性。在未来,更宽泛的KB可能在KBQA研究中展现更大的影响力。
Original: https://blog.csdn.net/weixin_48167662/article/details/118993312
Author: PKUMOD
Title: 论文导读 | 复杂知识库问答综述:方法,挑战和解决方案
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557683/
转载文章受原作者版权保护。转载请注明原作者出处!