

申明:此项目是由”跟若海写代码”公众号发布内容整理而来,侵删。
适用:知识图谱推荐入门项目、熟悉neo4j图数据库一般操作等。
目录
1 项目需求分析与方案设计
1.1 需求分析
1.1.1 功能需求
用户的功能需求只有1个,回答用户电影相关的提问。
具体可以细化为以下几种类型:
通过演员问电影,比如某某演员演过哪些电影;
问演员的相关信息,比如某个演员的介绍;
通过电影问演员,比如某某电影包括哪些演员;
问电影的相关信息,比如某某电影的评分是多少,某某电影的剧情是什么;
根据类型问电影,比如某某类型的电影有哪些;
结合演员和评分进行提问,比如某某演员评分大于某值的电影有哪些;
结合电影类型和演员进行提问。
1.1.2 使用需求
需求指出需要通过web应用的形式提供给用户,因此项目应该包含如下几个部分:
web前端
API接口层
算法服务层
数据存储层
1.1.3 性能需求(略)
1.2 产品设计
通过需求分析,进行产品设计,主要包括UI设计和交互设计。设计了两种不同风格的UI形式,一种是聊天机器人的形式,一种是传统搜索的形式。
聊天机器人版
UI界面如下图所示,交互采用被动单轮对话的形式,具体如下。
即整体应用以对话的形式展开,但只是被动的对话,只有当用户输入问题时,应用才会进行响应;
单轮对话,即只用户输入一个问题,系统只输出一个回答,多个问答之间没有关联。
如果应用可以回答问题,则输出答案,如果系统无法识别问题或者没有相关数据,则输出我也不知道答案。
用户首次进入聊天页面时,会提示用户支持的问题类型,并给出几个参考问题。


搜索版
应用整体上以搜索的形式呈现,页面分为三大部分。
第1部分是搜索框和回答区;
第2部分是问题类型提示;
第3部分是应用支持的电影种类、部分电影名称、部分演员列表。

2 搭建项目
2.1 配置环境
2.1.1 安装软件和库
- 安装python包管理工具conda
- 安装python集成开发环境pycharm
参考资料:
《python环境搭建和基础语法》深度学习环境搭建,1 Python环境搭建和基础语法_哔哩哔哩_bilibili
《minicode和jupyter环境搭建》深度学习环境搭建,2 minicode和jupyter环境搭建_哔哩哔哩_bilibili
2.1.2 安装依赖包
- 使用conda创建虚拟环境
- 安装依赖包
*
– numpy
– pandas
– scikit-learn
– py2neo
– matplotlib
– flask
2.2 项目结构
- 根目录
*
– run.py
– run_script.py
- 三层架构
*
– model层
+ question_classify_model.py
+ question_template.py
– service层
+ question_service.py
– controller层
+ qa_server.py
- 静态网页
*
– templates
– static
- 通用目录
*
– common 基础代码,通用代码
– data 数据
– script 脚本
2.3 编写数据库层
电影数据属性图建模
关系型电影数据
- 电影类别csv前5行
gid,gname 12,冒险 14,奇幻 16,动画 18,剧情
- 电影csv前5行
"mid","title","introduction","rating","releasedate" "13","Forrest Gump","阿甘(汤姆·汉克斯 Tom Hanks 饰)于二战结束后不久出生在美国南方阿拉巴马州一个闭塞的小镇,他先天弱智,智商只有75,然而他的妈妈是一个性格坚强的女性,她常常鼓励阿甘“傻人有傻福”,要他自强不息。阿甘像普通孩子一样上学,并且认识了一生的朋友和至爱珍妮(罗宾·莱特·潘 Robin Wright Penn 饰),在珍妮和妈妈的爱护下,阿甘凭着上帝赐予的“飞毛腿”开始了一生不停的奔跑。阿甘成为橄榄球巨星、越战英雄、乒乓球外交使者、亿万富翁,但是,他始终忘不了珍妮,几次匆匆的相聚和离别,更是加深了阿甘的思念。有一天,阿甘收到珍妮的信,他们终于又要见面…","8.300000190734863","1994-07-06" "24","Kill Bill: Vol. 1","新娘(乌玛·瑟曼饰)曾经是致命毒蛇暗杀小组(D.I.V.A.S)的一员,企图通过结婚脱离血腥的生活。但是她的前同僚(汉纳、刘玉玲、薇薇卡·A·福克斯、迈克尔·马德森等人扮演)以及所有人的老板比尔(大卫·卡拉丁饰)的到来破坏了这一切。“比尔,”新娘请求说,“我怀孕了,是你的孩子。”但是回答她的是“砰”的一声枪响!4年后她在一家医院醒来,就立刻开始着手一次从得克萨斯到冲绳、东京以及墨西哥的复仇之旅,为了一个目标她要大开杀戒。“当我到达目的地之后,我将杀死比尔。”","7.800000190734863","2003-10-10" "79","英雄","战国末期,赵国有三个名震天下的侠客,他们是:“长空”、“残剑”、“飞雪”。因为他们,秦王十年里没睡过一个安稳觉。可是他们却被一个默默无闻,名叫无名的秦国剑客所杀。消息传来,秦王振奋,急召无名上殿相见。在秦王的大殿里,神秘的烛火燃烧着,秦王与无名只有十步的距离,无名将击杀长空、残剑、飞雪的故事娓娓道来:他利用三人之间爱恨交织的关系,瓦解了他们的力量,各个击破,因此取胜。可秦王机智过人,听出了无名故事中的破绽,说出了另一个故事的**:残剑等三人是主动求败,献出生命,用苦肉计帮助无名上殿,无名才是真正最危险的刺客,而无名告诉秦王:他看错了一个人,那就是残剑。于是真正的故事从头叙起……最后,无名拿起了剑,此时他离秦王只有十步,他的绝技是“十步一杀”。","7.300000190734863","2002-12-19" "82","Miami Vice","故事背景从上世纪80年代变成了现代的迈阿密,美国南部城市迈阿密一直以来都是毒品犯罪的“茂盛”繁殖 地。美国联邦调查局(FBI)更是从来都没有放松过对这一带地区的监控,尤其是那些享誉拉美的大毒枭们,早已成为了警方最为关注的焦点。当前,正有一个棘手的大宗毒品走私案在紧张的调查中。迈阿密警方自然也派出了多位精明强干的警探参与其中,黑人警察里卡多(杰米·福克斯)与詹姆斯·科罗凯特(柯林·法瑞尔)一个正面追查毒品走私的线路,一个则假扮成小毒贩,卧底于一个较大的贩毒团伙内。然而,在时间不长的卧底调查中,个性夸张的詹姆斯不知不觉中陷入了与性感女银行家伊莎贝拉(巩俐)的私密恋情之中。然而,这个亚裔女人实际上就是本地毒品走私集团幕后的重要头目,并且是远近闻名的大毒枭兼军火商蒙托亚(路易斯·多萨)的女人。两人离奇的恋情给整个案件的侦破带来了空前的麻烦和危险。“黑白干探”、性感女毒犯以及凶残的大毒枭……所有的一切“黑白之物”都在一瞬间纠缠在了一起。","5.699999809265137","2006-07-27"
电影和类别关系csv前5行
"mid","gid" "79","12" "82","12" "87","12" "146","12"
人物csv前5行
"pid","birth","death","name","biography","birthplace" "643","1965-12-31",\N,"巩俐","新加坡华裔女演员,祖籍中国山东,毕业于中央戏剧学院,联合国促进和平艺术家,联合国全球环境保护大使。1987年,因主演电影《红高粱》成名,该片获得柏林电影节金熊奖。1992年,凭借主演的电影《秋菊打官司》获得威尼斯国际电影节最佳女演员奖,该片亦获得金狮奖。1993年,主演的电影《霸王别姬》获得金棕榈奖,因而巩俐成为世界影史第二位主演影片包揽欧洲三大国际电影节影片奖的演员。1993年,获得柏林国际电影节金摄影机奖并上榜美国《人物》全球最美50人。1996年,登上美国《时代周刊》封面并上榜全球十大人物。1997年,担任戛纳国际电影节评委会成员。2000年,担任柏林国际电影节评委会主席;同年,获得蒙特利尔国际电影节最佳女演员奖及艺术成就大奖。2002年,担任威尼斯国际电影节评委会主席。2003年,担任东京国际电影节评委会主席。2004年,获得戛纳国际电影节纪念大奖;同年,上榜美国《首映》影史百大伟大表演。2005年,入选中国电影百年50位有突出贡献艺术家。2006年,上榜美国《时代周刊》60年亚洲英雄;同年,上榜美国《华盛顿邮报》全球年度5位伟大演员。2010年,法国文化部授予其“艺术与文学勋章”司令勋位。2014年,担任上海国际电影节评委会主席;同年,二度上榜日本《电影旬报》百大外国女星。2015年,入选联合国16位影响人类文化艺术家。","Shenyang, Liaoning Province, China" "695","1937-03-16","1999-04-14","乔宏","","Shanghai, China" "1336","1963-04-26",\N,"李连杰","李连杰(Jet Li),1963年4月26日生于北京市,华语影视男演员、导演、制作人 、武术运动员、商人。1971年进入北京什刹海体校,从而开始武术运动员的生涯。1975年参加全运会武术套路比赛,获得全能冠军。1979年因伤退出武术界。1982年主演个人首部电影《少林寺》,该片打破华语电影在中国内地的票房纪录。1986年自导自演动作片《中华英雄》。1991年主演的动作片《黄飞鸿之壮志凌云》奠定其在影坛的地位。1992年凭借武侠片《笑傲江湖Ⅱ:东方不败》获得更多关注。1995年获得第32届台湾电影金马奖大陆人士特别奖 。1998年赴美国好莱坞发展,同年出演其在好莱坞的首部电影《致命武器4》。2001年担任动作片《变种元素》的制作人。2002年因主演武侠片《英雄》而成为美国《时代周刊》的封面人物 。2003年凭借动作片《宇宙追缉令》获得第12届MTV电影奖最佳打斗场面提名。2008年凭借动作片《投名状》获得第27届香港电影金像奖最佳男主角 。2009年成为中国企业家俱乐部会员。2010年入选美国《时代周刊》“年度最具影响力人物百人榜” 。2011年参与创办太极禅国际文化发展有限公司。2013年在《中华武术》三十年颁奖盛典中,获得“中华武术30年最具武术影响力人物奖”。2016年主演古装片《封神传奇》 。李连杰热心公益慈善。2007年创建公益组织壹基金。2009年担任世界卫生组织亲善大使。2010年担任国际红十字会亲善大使。2014年在《中国慈善家》“中国慈善名人榜”中排名第二位。","Beijing, China" "1337","1962-06-27",\N,"梁朝伟","","Hong Kong"
- 人物和电影关系csv前5行
"pid","mid" "163441","13" "240171","24" "1336","79" "1337","79"
电影属性图建模
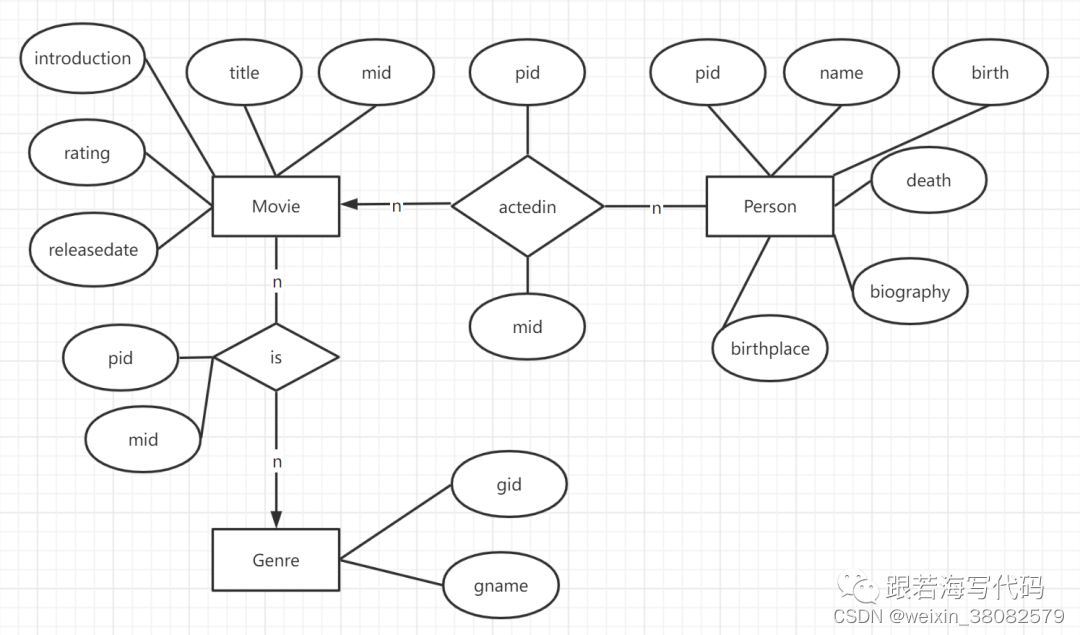
电影数据导入
def load_genre():
genre_node_cql = '''LOAD CSV WITH HEADERS FROM "file:///genre.csv" AS line
MERGE (p:Genre{gid:toInteger(line.gid),name:line.gname})
'''
movie_neo4j.run(genre_node_cql)
def load_person():
person_node_cql = '''LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS line
MERGE (p:Person { pid:toInteger(line.pid),birth:line.birth,
death:line.death,name:line.name,
biography:line.biography,
birthplace:line.birthplace})
'''
movie_neo4j.run(person_node_cql)
def load_movie():
movie_node_cql = '''LOAD CSV WITH HEADERS FROM "file:///movie.csv" AS line
MERGE (p:Movie{mid:toInteger(line.mid),title:line.title,introduction:line.introduction,
rating:toFloat(line.rating),releasedate:line.releasedate})
'''
movie_neo4j.run(movie_node_cql)
def load_movie_person_rel():
movie_person_rel = '''LOAD CSV WITH HEADERS FROM "file:///person_to_movie.csv" AS line
match (from:Person{pid:toInteger(line.pid)}),(to:Movie{mid:toInteger(line.mid)})
merge (from)-[r:actedin{pid:toInteger(line.pid),mid:toInteger(line.mid)}]->(to)
'''
movie_neo4j.run(movie_person_rel)
def load_movie_genre_rel():
movie_genre_rel = '''LOAD CSV WITH HEADERS FROM "file:///movie_to_genre.csv" AS line
match (from:Movie{mid:toInteger(line.mid)}),(to:Genre{gid:toInteger(line.gid)})
merge (from)-[r:is{mid:toInteger(line.mid),gid:toInteger(line.gid)}]->(to)
'''
movie_neo4j.run(movie_genre_rel)
3 核心功能模块
前面四节我们主要是对电影问答项目涉及的知识进行了介绍,包括知识图谱的简介,图数据的使用和案例,从本节开始正式进入项目开发。首先我们要完成问答框架的搭建,在问答应用中,我们接收的是用户的自然语言问句,首先需要对自然语言问句进行解析,这里涉及到自然语言处理的一些知识,比如分词、命名实体识别,同时我们需要对问句进行分类,这里涉及到机器学习中分类相关的算法,特别是对文本的分类处理办法。在把自然语言问句进行分类之后,我们需要进行查询语句转换,把分好类的问题转换为图数据库或其他数据库的查询语言,从而在数据库中查询出我们想要的结果,最后将查询结果返回给用户,就完成了整个问答流程,具体如下图所示。

项目目录:

下面这段代码是上述流程的体现,我们把上述流程写道Service层中的QuestionService类中,在QuetionService的get_answer方法中,接受控制层传入的自然语言问句,然后调用model层的分类方法和查询语句方法,最后把结果返回给控制层。
class QuestionService:
"""
问答核心类,接受问题输入,构造查询语句,输出查询结果
"""
def __init__(self):
print()
self.classify_model = QuestionClassify()
self.question_template = QuestionTemplate()
def get_answer(self, question):
print()
# 通过分类器获取分类
question_category = self.classify_model.predict(question)
print(f"{question}的分类是:{question_category}")
# self.classify_model.get_question_category_desc(question_category)
try:
answer = self.question_template.get_question_answer(question, question_category)
except BaseException as e:
traceback.print_exc()
answer = "我也还不知道!"
return answer
3.1 问题分类
朴素贝叶斯
贝叶斯思想
贝叶斯学派的思想可以概括为先验概率+数据=后验概率。
也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。
sklearn中的朴素贝叶斯
- 朴素贝叶斯是一类比较简单的算法,scikit-learn中朴素贝叶斯类库的使用也比较简单。
- 相对于决策树,KNN之类的算法,朴素贝叶斯需要关注的参数是比较少的,这样也比较容易掌握。
GaussianNB,MultinomialNB和BernoulliNB。
- GaussianNB就是先验为高斯分布的朴素贝叶斯,
-
MultinomialNB就是先验为多项式分布的朴素贝叶斯,
-
BernoulliNB就是先验为伯努利分布的朴素贝叶斯。
-
如果样本特征的分布大部分是连续值,使用GaussianNB会比较好。
- 如果如果样本特征大部分是多元离散值,使用MultinomialNB比较合适。
- 如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用BernoulliNB。
利用朴素贝叶斯做问题匹配
构造训练数据
def load_train_data():
train_x = []
train_y = []
file_path_list = file_util.get_file_list(os.path.join(constant.DATA_DIR, "question"))
for file_item in file_path_list:
# 获取文件名中的label
label = re.sub(r'\D', "", file_item)
if label.isnumeric():
label_num = int(label)
# 读取文件内容
with (open(file_item, "r", encoding="utf-8")) as file:
lines = file.readlines()
for line in lines:
# 分词
word_list = list(jieba.cut(str(line).strip()))
# print(word_list)
train_x.append(" ".join(word_list))
train_y.append(label_num)
return train_x, train_y
文本向量化
利用tfidf做文本向量化
self.tfidf_vec = TfidfVectorizer()
self.train_vec = self.tfidf_vec.fit_transform(self.train_x).toarray()
训练模型
def train_model_nb(self):
"""
利用朴素贝叶斯分类器训练模型
:return:
"""
nb = MultinomialNB(alpha=0.01)
nb.fit(self.train_vec, self.train_y)
return nb
预测
def predict(self, question):
# 词性标注
text_cut_gen = nlp_util.posseg(question)
# 获取模板
# 替换nr(人名) nm(物品) ng(名词词素)
# 原始问题
text_src_list = []
# 一般化的问题,把人名替换为nr,依此类推
text_normal_list = []
for item in text_cut_gen:
text_src_list.append(item.word)
if item.flag in ['nr', 'nm', 'ng']:
text_normal_list.append(item.flag)
else:
text_normal_list.append(item.word)
question_normal = [" ".join(text_normal_list)]
question_src = [" ".join(text_src_list)]
question_vector = self.tfidf_vec.transform(question_normal).toarray()
predict = self.model.predict(question_vector)[0]
return predict
单元测试
def test_question_classify():
# question = "章子怡演过哪些电影"
question = "英雄的主演有谁"
# question = "哈利波特的主演有谁"
question_classify = QuestionClassify()
result = question_classify.predict(question)
print(f"{question} category:{result}")
3.2 问句解析
解析问句中的实体
# 获取电影名字
def get_movie_name(self):
## 获取nm在原问题中的下标
tag_index = self.question_flag.index("nm")
## 获取电影名称
movie_name = self.question_word[tag_index]
return movie_name
# 获取人物名字
def get_name(self, type_str):
name_count = self.question_flag.count(type_str)
if name_count == 1:
## 获取nm在原问题中的下标
tag_index = self.question_flag.index(type_str)
## 获取电影名称
name = self.question_word[tag_index]
return name
else:
result_list = []
for i, flag in enumerate(self.question_flag):
if flag == str(type_str):
result_list.append(self.question_word[i])
return result_list
# 获取数字,如评分
def get_num_x(self):
x = re.sub(r'\D', "", "".join(self.question_word))
return x
根据问题和模板选择相应的查询
def get_question_answer(self, question, template_id):
question = nlp_util.question_posseg(question)
# 预处理问题
question_word, question_flag = [], []
for one in question:
word, flag = one.split("/")
question_word.append(str(word).strip())
question_flag.append(str(flag).strip())
assert len(question_flag) == len(question_word)
self.question_word = question_word
self.question_flag = question_flag
self.raw_question = question
# 根据问题模板来做对应的处理,获取答案
answer = self.q_template_dict[template_id]()
if len(answer) == 0:
answer = "抱歉,我还不知道这个答案"
return answer
构造查询类别
class QuestionTemplate():
def __init__(self):
self.q_template_dict = {
0: self.get_movie_rating,
1: self.get_movie_releasedate,
2: self.get_movie_type,
3: self.get_movie_introduction,
4: self.get_movie_actor_list,
5: self.get_actor_info,
6: self.get_actor_act_type_movie,
7: self.get_actor_act_movie_list,
8: self.get_movie_rating_bigger,
9: self.get_movie_rating_smaller,
10: self.get_actor_movie_type,
11: self.get_cooperation_movie_list,
12: self.get_actor_movie_num,
13: self.get_actor_birthday
}
self.neo4j_conn = Neo4jQuery()
# 0:nm 评分
def get_movie_rating(self):
return final_answer
# 1:nm 上映时间
def get_movie_releasedate(self):
return final_answer
# 3:nm 简介
def get_movie_introduction(self):
return final_answer
# 4:nm 演员列表
def get_movie_actor_list(self):
return final_answer
# 6:nnt ng 电影作品
def get_actor_act_type_movie(self):
return final_answer
# 7:nnt 电影作品
def get_actor_act_movie_list(self):
return final_answer
def get_actorname_movie_list(self, actorname):
return final_answer
def get_movie_rating_smaller(self):
return final_answer
def get_cooperation_movie_list(self):
return final_answer
def get_actor_movie_num(self):
return final_answer
def get_actor_birthday(self):
return final_answer
3.3 查询语句转换
查询语句转换
获取评分
def get_movie_rating(self):
# 获取电影名称,这个是在原问题中抽取的
movie_name = self.get_movie_name()
cql = f"match (m:Movie)-[]->() where m.title='{movie_name}' return m.rating"
print(cql)
answer = self.neo4j_conn.run(cql)[0]
print(answer)
answer = round(answer, 2)
final_answer = movie_name + "电影评分为" + str(answer) + "分!"
return final_answer
获取上映时间
def get_movie_releasedate(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[]->() where m.title='{movie_name}' return m.releasedate"
print(cql)
answer = self.neo4j_conn.run(cql)[0]
final_answer = movie_name + "的上映时间是" + str(answer) + "!"
return final_answer
获取电影类型
def get_movie_type(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[r:is]->(b) where m.title='{movie_name}' return b.name"
print(cql)
answer = self.neo4j_conn.run(cql)
answer_set = set(answer)
answer_list = list(answer_set)
answer = "、".join(answer_list)
final_answer = movie_name + "是" + str(answer) + "等类型的电影!"
return final_answer
获取电影介绍
def get_movie_introduction(self):
movie_name = self.get_movie_name()
cql = f"match(m:Movie)-[]->() where m.title='{movie_name}' return m.introduction"
print(cql)
answer = self.neo4j_conn.run(cql)[0]
final_answer = movie_name + "主要讲述了" + str(answer) + "!"
return final_answer
获取演员列表
获取演员介绍
获取演员演过的指定类型的电影列表
获取演员演过的电影列表
获取演员演过的评分大于特定分值的电影列表
获取演员演过的评分小于特定分值的电影列表
获取演员演过电影的所有类型
获取演员的合作演员
获取演员演过的电影数量
获取演员的生日
Original: https://blog.csdn.net/weixin_38082579/article/details/125389322
Author: weixin_38082579
Title: 知识图谱推荐之neo4j电影智能问答项目
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557482/
转载文章受原作者版权保护。转载请注明原作者出处!