

Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu and Tat-Seng Chua (2019). KGAT: Knowledge Graph Attention Network for Recommendation. Paper in ACM DL or Paper in arXiv. In KDD’19, Anchorage, Alaska, USA, August 4-8, 2019.
原文:https://arxiv.org/pdf/1905.07854.pdf
源码:https://github.com/xiangwang1223/knowledge_graph_attention_network(tensorflow / official)** https://github.com/LunaBlack/KGAT-pytorch(pytorch)
文章目录
*
– 1 introduction
– 2 任务解释
–
+
* 2.1 定义
* 2.2 模型结构(framework)
– 3 模型解释
–
+
* 3.1 embedding layer 嵌入层
* 3.2 Attentive Embedding Propagation Layers
*
– 3.2.1 信息传播 – Information Propagation
– 3.2.2 基于知识的注意力 – Knowledge-aware Attention
– 3.2.3 信息聚合 – Information Aggregation
* 3.3 预测层(prediction layer)
– 4 模型学习
1 introduction
传统 CF (协同过滤)算法存在一定的问题:数据稀疏,冷启动,且难以将大量辅助信息(side information)加入利用,例如用户本身特征,物品特征,文本信息,社交网络信息等。
当前的一种利用 side information 的解决方式为将其转化为有监督学习问题:也就是利用 embedding 将物品和用户都利用向量表示,再输入有监督学习的模型中进行处理(比如给定用户和物品,判断用户是否会点击物品的二分类问题,此时的损失函数本身就是交叉熵函数;经过 embedding 以后就是一个简单的有监督问题。)但是这样的处理方式存在一定的问题:其往往先通过 embedding,在下游推荐问题中(也就是有监督问题的处理中)往往考察的是(当前我给出的物品 item 和用户 user 过去发生过交互的物品的相似度),也就是类似于(基于物品的协同过滤)的思路;而难以将(基于用户的协同过滤),也就是寻找到和当前用户相似的用户,再进行推荐的方法进行融合。
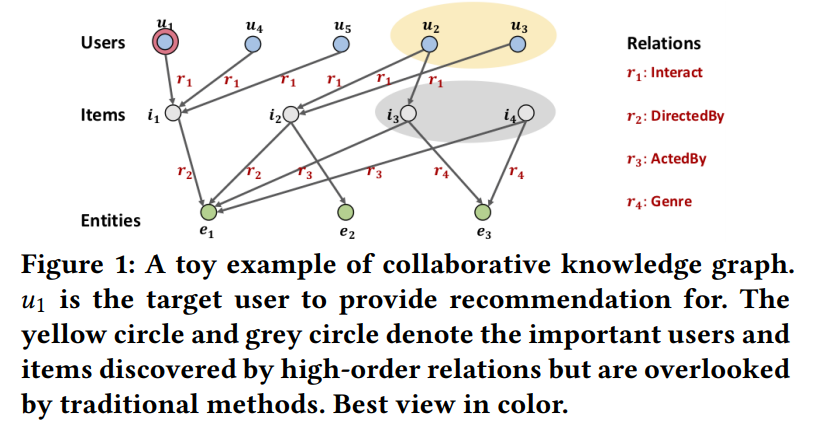

比如上图,此时想要为用户 u1 进行推荐,传统 CF 的方法能够帮助找到用户 u4 和 u5,因为他们和 u1 一样都对物品 i1 发生过行为;而利用了 side information 的有监督学习的方法往往能够找到 i2,因为其与用户曾经发生过行为的物品 i1 存在相似之处(都由 e1 导演(和 e1 的关系 r 都是类别 r2),这里的 e1 就是 side information,被利用起来了)。
但是注意,此时图中仍存在没有被利用起来的信息:比如这里的 u2 和 u3 应该是和 u1 相似的用户(因为 i1 和 i2 是相似的物品)但是难以被 CF 或有监督学习的方法捕捉;同理 i3 和 i4 同理也被忽略了:此时 i3 和 i4 同理和 i1 一样都与 e1 存在交互(虽然交互的 r 联系类型不同)。
也就是说上述的方法难以捕捉到一种高阶的关系(high-order relationship),但是捕捉这样的关系同理为整体模型带来了挑战 →
- 更多的实体将被引入模型带来计算的巨大压力,也就是到底选择多少的高阶关系参与进入模型训练的问题;
- 并不是所有的高阶关系都合适,此时需要模型对这些高阶关系进行一定的筛选 / 给予其不同的权重(不然对于 i3 i4 这种被忽略的情况,似乎直接不对 r 分类就可以解决)。简单来说,需要模型给不同的高阶关系以不同的权重,在后续通过注意力机制的方式解决。
解决: 提出 collaborative knowledge graph (CKG)方法,一般可以分为两个思路:
- 基于路径的方法(path-based):本身两个节点之间可能的路径很多,缺点在于需要人工手动设计 meta-path / meta-graph,且并没有针对推荐问题进行优化。
- 基于规则的方法(regularization-based ),注意并不是直接将高阶关系加入到优化推荐模型中,而是以隐式方法对它们进行编码。此时一方面难以保证确实捕捉到了长距离的关系,另一方面难以保证捕捉到的长距离关系确实是有意义的(也就是难以得到较好的解释性)
本文提出一个新的思路: 知识图注意力网络(Knowledge Graph Attention Network (KGAT)),具体优势如下:
- 以端到端的方式实现建模,且较好地捕捉整体 KG 中的高阶关系
- 以显式的方式进行,保障模型的可解释性
- 采用了注意力机制,自动学习权重
- 不需要像 meta-path / meta-graph 那样要求手动设计路径,优于基于路径的方法
; 2 任务解释
2.1 定义
- user-item 二部图(User-Item Bipartite Graph):也就是用户和物品的历史行为记录,类似于用户-物品矩阵,但是本身以图的形式展示。定义G 1 = { ( u , y u , i , i ) ∣ u ∈ U , i ∈ I } \mathcal{G_1} = \lbrace (u, y_{u,i}, i) | u\in U , i\in I\rbrace G 1 ={(u ,y u ,i ,i )∣u ∈U ,i ∈I } 这里的 U 和 I 分别表示用户和物品集合,注意此时只是讨论用户和物品之间的关系,仅限于传统 CF 讨论的关系。如果此时存在联系,则对应的 y u , i = 1 y_{u,i} = 1 y u ,i =1, 否则为 0。
- 知识图谱(Knowledge Graph) 也就是更为自由的可以由不同的类型的实体组成的整体异构信息网,本身由节点和有向边组成,节点表示实体 entity,边表示关系 relationship。将此时传统 CF 难以利用的辅助信息都融入知识图谱中进行利用(也就是 side information)
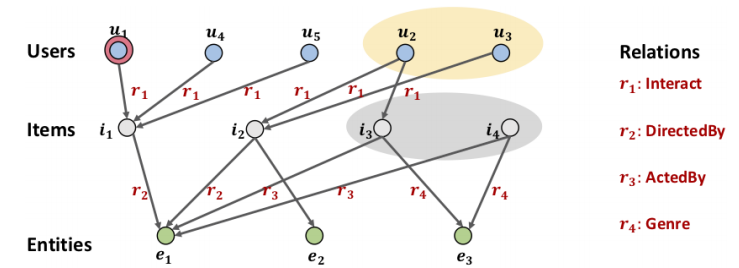
- CKG(Collaborative Knowledge Graph) 也就是一个二部图和 KG 的结合体。考虑整合关系:G = { ( h , r , t ) ∣ h , t ∈ ϵ ′ , r ∈ R ′ } \mathcal{G} = \lbrace (h,r,t) | h,t \in \epsilon’, r\in \mathcal{R}’\rbrace G ={(h ,r ,t )∣h ,t ∈ϵ′,r ∈R ′} 注意这里:ϵ ′ = ϵ ∪ U , R ′ = R ∪ { i n t e r a c t } \epsilon’ = \epsilon \cup \mathcal{U},\text{ } R’ = R\cup\lbrace interact\rbrace \text{ }ϵ′=ϵ∪U ,R ′=R ∪{i n t e r a c t }, ε 本身是实体 entity 集合, R 是关系集合。直观理解就是上面那个图(搬过来在下面放好放好 ↓):在下面部分作为普通的知识图谱的同时,特别地将物品集合提出来,针对物品集合再创建 用户 – 物品 矩阵的部分,可以看作是在正常的知识图谱上接了一个 CF 的稀疏矩阵的形式。
; 2.2 模型结构(framework)
输入: 构造好的 CKG,记作 G \mathcal{G}G,对应的 CF 的用户-物品矩阵 G 1 \mathcal{G_1}G 1 和知识图谱 G 2 \mathcal{G_2}G 2
输出: 能够预测用户 u 点击物品 i 的概率的 prediction function
基本模型结构如下图:
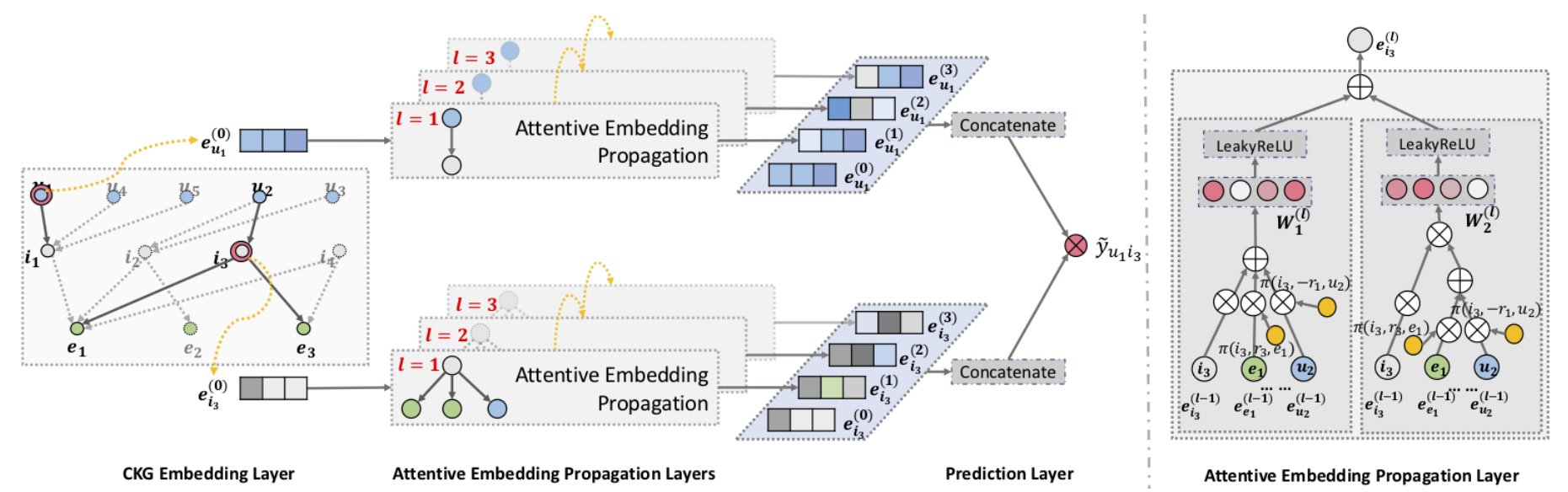
此时分为三个主要的组成部分:
- CKG embedding layer:利用构造的 CKG 结构进行嵌入表示,也就是通过 embedding 得到各个实体的向量表示。
- attentive embedding propagation layer:通过邻居节点递归地传播 embedding来增强表示 → 通过基于知识的注意力来计算权重 → 信息聚合
- prediction layer:也就是预测层,注意这里想要的是用户是否会点击物品,归一化后得到概率。
3 模型解释
3.1 embedding layer 嵌入层
也就是通过 CKG 得到实体的向量表示。在这里使用的是 Trans 系的 embedding 方式(原论文用到的是 TransR)
具体 Trans 系的方法还是用的很多的,这里就只简单提两句,具体参考
直观来说可以理解为,我构建一个针对三元组的评分标准:g ( h , r , t ) = ∣ ∣ W r e h + e r − W r e t ∣ ∣ 2 2 g(h,r,t) = || W_re_h + e_r – W_re_t||_2^2 g (h ,r ,t )=∣∣W r e h +e r −W r e t ∣∣2 2 ,此时三元组的得分 g ( h , r , t ) g(h,r,t)g (h ,r ,t ) 越低,我认为这个三元组是越可信的(也就是 h 和 t 之间更可能确实存在关系 r)
则此时我通过不断优化下面的损失函数来训练模型得到一个更好的 embedding 表示:
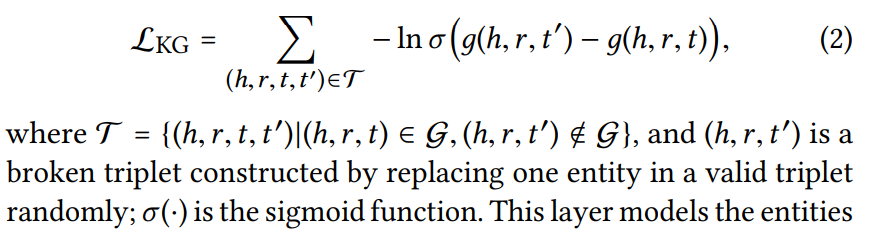
也就是说上述的 loss 越小,说明 sigmoid 函数出来的结果越贴近 1,也就是 sigmoid 内部的结果很大,也就是 我随意选择的 t’ 构成的三元组(也就是随机替换掉一个有效实体构造的实际上无效的三元组 = 噪声)的得分要比正常的三元组的得分高很多,此时分越高就是越不可信的。
; 3.2 Attentive Embedding Propagation Layers
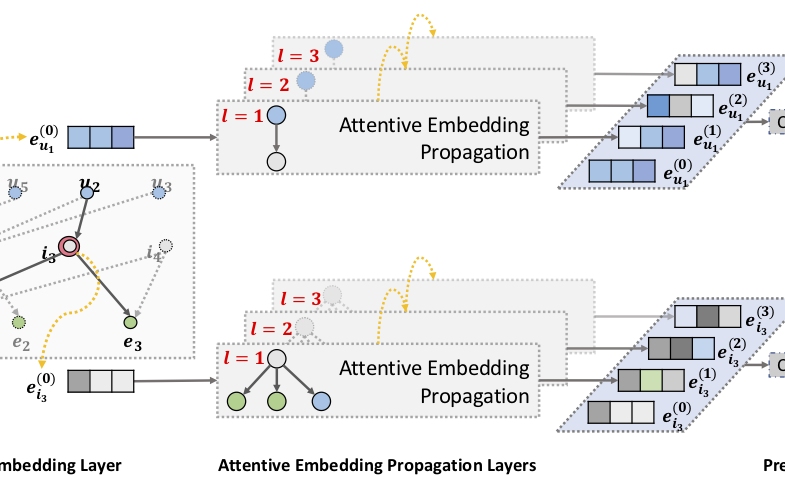
这里主要分为三个部分。输入的是 embedding 结束的 u 和 i (实体)
3.2.1 信息传播 – Information Propagation
考虑:此时如果从 a 指向 b,尾节点的信息同样可以用来丰富头节点 a 的信息,此时利用 ego 网络的思路:
对于一个实体 h,此时用 Nh 来表示所有以 h 为头节点的三元组的集合,也就是节点 h 的 ego 网络:N h = { ( h , r , t ) ∣ ( h , r , t ) ∈ G } N_h = \lbrace (h,r,t) | (h,r,t)\in\mathcal{G}\rbrace N h ={(h ,r ,t )∣(h ,r ,t )∈G }。
衡量 h 的 ego 网络的 embedding 表达方式,定义:e N h = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t e_{N_h} = \sum_{(h,r,t)\in N_h}{\pi(h,r,t) e_t}e N h =(h ,r ,t )∈N h ∑π(h ,r ,t )e t ,这里的 π ( h , r , t ) \pi(h,r,t)π(h ,r ,t ) 也就是这个三元组对应的权重,用以控制有多少的尾节点的信息 et 可以通过 r 传递给头节点 h。也就是说(所有以 h 为头节点的三元组的集合 = h 的 ego 网络)的 e(也就是 embedding 表示) 定义为(这些三元组的尾节点的 embedding 表示的线性组合)
3.2.2 基于知识的注意力 – Knowledge-aware Attention
这里利用基于知识的注意力来计算前面需要的 π ( h , r , t ) \pi(h,r,t)π(h ,r ,t ):π ( h , r , t ) = ( W r e t ) T t a n h ( ( W r e h + e r ) ) \pi(h,r,t) = (W_re_t)^Ttanh((W_re_h+e_r))π(h ,r ,t )=(W r e t )T t a n h ((W r e h +e r )) π ( h , r , t ) = e x p ( π ( h , r , t ) ) ∑ ( h , r ′ , t ′ ) ∈ N h e x p ( π ( h , r ′ , t ′ ) ) \pi(h,r,t) = \frac{exp(\pi(h,r,t))}{\sum_{(h,r’,t’)\in N_h}{exp(\pi(h,r’,t’))}}π(h ,r ,t )=∑(h ,r ′,t ′)∈N h e x p (π(h ,r ′,t ′))e x p (π(h ,r ,t ))
这里的 W r ∈ R d × d W_r\in R^{d\times d}W r ∈R d ×d,
则如上的计算可以理解为:到底 有多少尾节点 t 的信息可以通过关系 r 传递给头节点 h,主要取决于在关系 r 空间上 h 和 t 的距离。此时距离越近越容易将 t 的信息传递给 h,在 h 的 ego 网络的 embedding 中得到更大的表示权重。
注意最后还是要 softmax 归一化得到权重。
3.2.3 信息聚合 – Information Aggregation
考虑聚合头节点本身的 embedding(也就是 eh)的信息和头节点对应的 ego 网络的 embedding(也就是 e N h e_{N_h}e N h ) 来重新得到 h 结点的 embedding 表示。此时定义 h 头节点的新的 embedding 表示:e h ( 1 ) = f ( e h , e N h ) e_h^{(1)} = f(e_h, e_{N_h})e h (1 )=f (e h ,e N h ),这里的 f ( . ) f(.)f (.) 可以使用以下三种可能的聚合器:
- GCN 聚合:先将两个向量相加,再进行非线性的转换f G C N = L e a k y R e L U ( W ( e h + e N h ) ) f_{GCN} = LeakyReLU(W(e_h+e_{N_h}))f G C N =L e a k y R e L U (W (e h +e N h ))
- GraphSage 聚合:将两个表示方法直接先接在一起,再通过非线性的转换:f G r a p h S a g e = L e a k y R e L U ( W ( e h ∣ ∣ e N h ) ) f_{GraphSage} = LeakyReLU(W(e_h||e_{N_h}))f G r a p h S a g e =L e a k y R e L U (W (e h ∣∣e N h ))
- Bi-Interaction 聚合:某种程度上是以上两种方式的合体:f B i − I n t e r a c t i o n = L e a k y R e L U ( W 1 ( e h + e N h ) ) + L e a k y R e L U ( W 2 ( e h ⊙ e N h ) ) f_{Bi-Interaction} = LeakyReLU(W_1(e_h+e_{N_h}))+LeakyReLU(W_2(e_h \odot e_{N_h} ))f B i −I n t e r a c t i o n =L e a k y R e L U (W 1 (e h +e N h ))+L e a k y R e L U (W 2 (e h ⊙e N h )),注意这里满足W 1 , W 2 ∈ R d ′ × d W_1, W_2 \in R^{d’\times d}W 1 ,W 2 ∈R d ′×d,⊙ \odot ⊙指的是元素一一对应相乘
这里采用迭代的方式,也就是重复上面的过程多次:用当前的 e h ( l − 1 ) e_h^{(l-1)}e h (l −1 ) 代替 eh 来计算新的 e h ( l ) e_h^{(l)}e h (l ),也就是满足:e N h l − 1 = ∑ ( h , r , t ) ∈ N h π ( h , r , t ) e t ( l − 1 ) e_{N_h}^{l-1} = \sum_{(h,r,t)\in N_h} \pi(h,r,t) e_t^{(l-1)}e N h l −1 =(h ,r ,t )∈N h ∑π(h ,r ,t )e t (l −1 ) e h ( l ) = f ( e h ( l − 1 ) , e N h ( l − 1 ) ) e_h^{(l)} = f(e_h^{(l-1)}, e_{N_h}^{(l-1)})e h (l )=f (e h (l −1 ),e N h (l −1 ))
注意此时对于 e h ( l − 1 ) e_h^{(l-1)}e h (l −1 ),就确实是存储了节点 h 的 (l-1) 跳(l-1-hop)的信息的:举个例子,对于计算e h ( 1 ) e_h^{(1)}e h (1 )的时候,因为综合了e N h ( 0 ) e_{N_h}^{(0)}e N h (0 ) 的信息,也就是综合了 h 结点的一跳的尾节点 e t ( 0 ) e_t^{(0)}e t (0 ) 的信息;但是计算 e h ( 2 ) e_h^{(2)}e h (2 ) 的时候,同理会用到 h 结点的一条的尾节点更新后的信息,也就是 e t ( 1 ) e_t^{(1)}e t (1 ),但是计算 e t ( 1 ) e_t^{(1)}e t (1 ) 的时候,本身会用到 h 的 尾节点 t 的一跳的尾节点的信息,也就是 h 的两跳的尾节点的信息。
通过不断的传递和迭代,此时将结点 h 的多跳的信息都传入了 h 的 embedding 编码中。且通过注意力机制保证了不同信息的不同权重。也就是说,既实现了高阶信息的传递,同时利用注意力机制让模型自动地为不同的高阶信息赋予不同的权重。

; 3.3 预测层(prediction layer)
3.2 部分经过 L 次迭代后,此时可以得到每一个 用户 u 和物品 i 的各 L 个不同的表示(包含着不同的 L 跳的信息){ e u ( 1 ) , . . . , e u ( L ) } ; { e i ( 1 ) , . . . , e i ( L ) } \lbrace e_u^{(1)}, …, e_u^{(L)}\rbrace ;\text{ } \text{ } \text{ } \text{ } \lbrace e_i^{(1)}, …, e_i^{(L)}\rbrace {e u (1 ),…,e u (L )};{e i (1 ),…,e i (L )}
加上原来的表示 embedding,直接采用 层聚合机制 将 L+1 个表示进行拼接,得到每一个 用户 u 和物品 i 的最终表示,记作 e u ∗ , e i ∗ e_u^, e_i^e u ∗,e i ∗ e u ∗ = e u ( 0 ) ∣ ∣ . . . ∣ ∣ e u ( L ) ; e i ∗ = e i ( 0 ) ∣ ∣ . . . ∣ ∣ e i ( L ) e_u^ = e_u^{(0)}|| … || e_u^{(L)}; \text{ } \text{ } \text{ } \text{ } e_i^ = e_i^{(0)}|| … || e_i^{(L)}e u ∗=e u (0 )∣∣…∣∣e u (L );e i ∗=e i (0 )∣∣…∣∣e i (L )
也就是说此时既保证了原来结点的特征(也就是 L = 0 的初始的 embedding 的结果)参与了结点的最终表示;同时可以通过调整 L 控制让多远的信息参与进入结点的 embedding 表示,以控制信息传播(propagation)的强度。
预测部分就比较简单了,直接通过 u 和 i 的最终表示的内积来进行预测:y ^ ( u , i ) = e u ∗ T e i ∗ \hat{y}(u,i) = {e_u^}^T e_i^y ^(u ,i )=e u ∗T e i ∗
4 模型学习
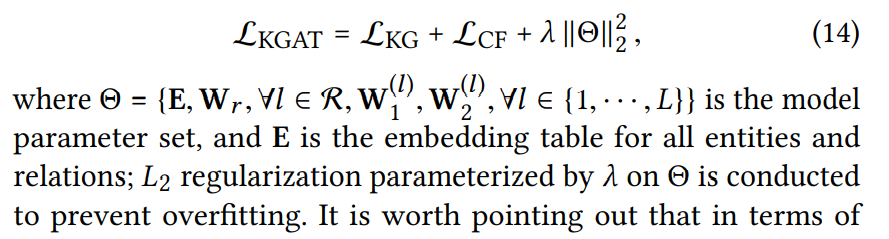
整体的损失函数应该就是 embedding 层的损失函数(也就是 KG 部分的损失函数)+ 推荐部分 CF 的 BPR loss + L2正则化
注意这里 CF 部分的损失函数如下:
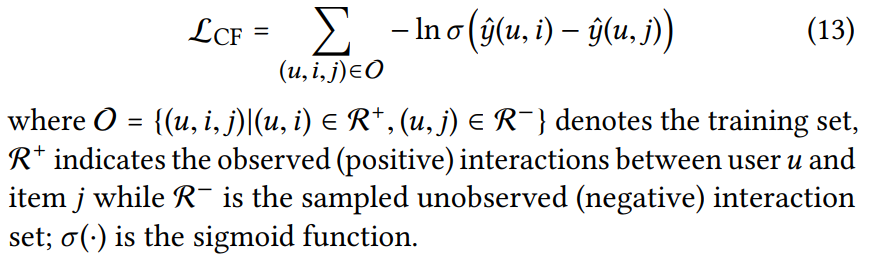
这里的 i 是确实和 u 发生了交互的物品,j 是没有和 u 发生交互的商品,分别用模型去预测 u 是否会和 i j 发生交互,如果一个模型效果不错,对应 i 的yhat 应该大,而对应 j 的应该小,整体经过 sigmoid 函数后应该贴近 1,取对数后贴近 0 ,此时损失函数的值较小。
具体训练的时候还是采用梯度下降的方式。
实验结果:在所利用的三个数据集上均有提升,具体实验在这里不赘述了,参考原文。
数据集的情况:
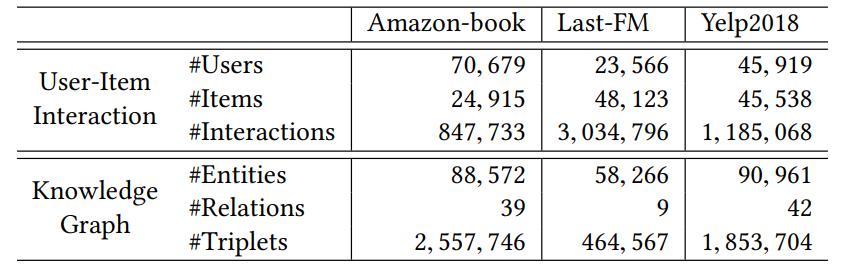
最后结果:注意较 RippleNet 也是有所提升的
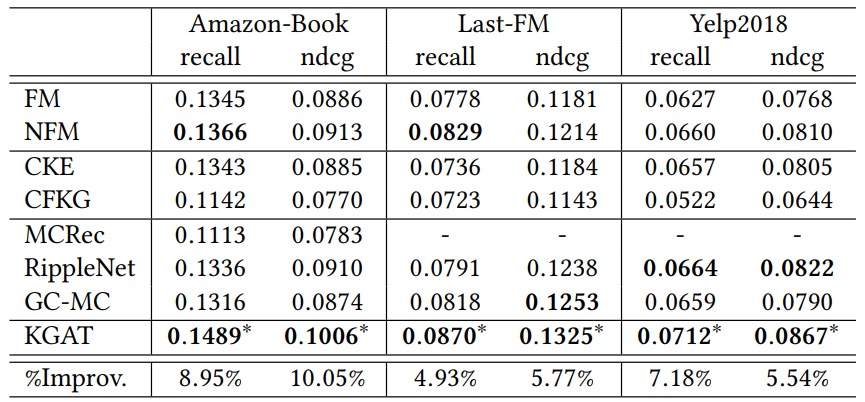
最后提一下中间的几个点:
超参数 L 的选取:也就是到底吸纳多远的信息进入模型训练:
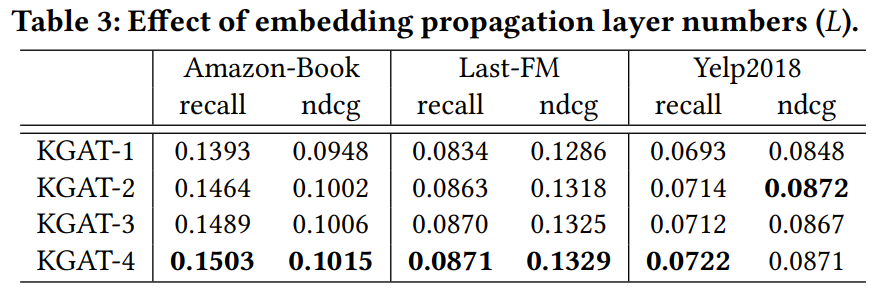
注意并不一定是越远的信息均加入就会越好,原文提及对于 Yelp 数据集这类不是这么稀疏的数据集(densest),如果 L 过大反而容易造成重合+引入更多的噪声。
It is worthwhile pointing out that KGAT slightly outperforms some baselines in the densest user group (e.g., the < 2057 group of Yelp2018). One possible reason is that the preferences of users with too many interactions are too general to capture. High-order connectivity could introduce more noise into the user preferences, thus leading to the negative effect.
多种聚合方式的选取(aggregator)
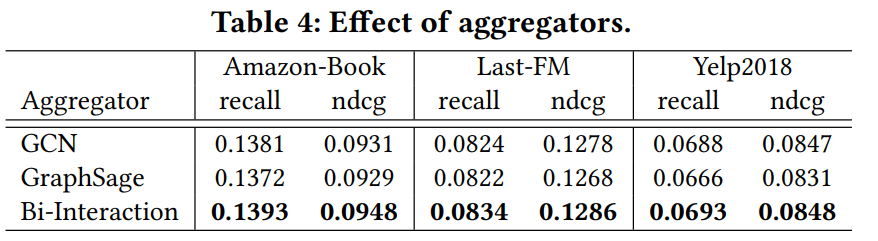
Bi-Interaction 作为前两种的综合好像效果不错,当然具体实验的时候如果时间允许还是均尝试一下比较好。
阅读仓促,存在错误 / 不足欢迎指出!期待进一步讨论~
转载请注明出处。知识见解与想法理应自由共享交流,禁止任何商用行为!Original: https://blog.csdn.net/m0_46522688/article/details/113763408
Author: HicSuntLeones
Title: 【论文笔记】KGAT:融合知识图谱的 CKG 表示 + 图注意力机制的推荐系统
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/557052/
转载文章受原作者版权保护。转载请注明原作者出处!