

命名实体识别
(在联合抽取中,命名实体识别是一个部分,也会影响到关系抽取的质量,对于命名实体识别,目前主要涉及在细粒度命名实体识别、嵌套、不连续命名实体识别等)
相关的方法主要有两大类:基于span的方式、基于tag的方式
SPANNER: Named Entity Re-/Recognition as Span Prediction
这篇文章主要分析基于span的方法的优劣势,比较了seq——label的方式,最后提出了ensemble learn的方法,提高了命名实体识别的准确度。
基于span的命名实体识别:主要包括三个模块:
(1)是句子向量表示—–方法:(预训练模型、glove、bert、BiLSTM)
(2)是span表示,一般会加上对应的实体类型
(3)是span的预测,判断span是否为实体(softmax)
研究内容:
(1)模型变量对于模型效果的影响
在实验一中,作者将不同的变量逐次加入到模型中,分别是
(1)boundary 编码(span的头尾位置token的embedded的cat)
(2)span length 编码(对应于span部分的tokens的embedded)
在解码方式中, 提到启发式解码,这里我没有太懂。(heuristic decoding,)
结论:说明不同实验变量的作用
(2)span model和seq model的互补性分析
在这一节中,主 要为了说明不同模型在什么条件下最有效,以两种模型F1-score的差值最为基准绘制的图。
对于 语料按实体连续度、句子长度、实体长度、 density of OOVs(这里也乜有太懂OOVs是什么?)各自分为了四类,分别是 extra-small (XS), small (S), large (L), and
extra-large (XL)
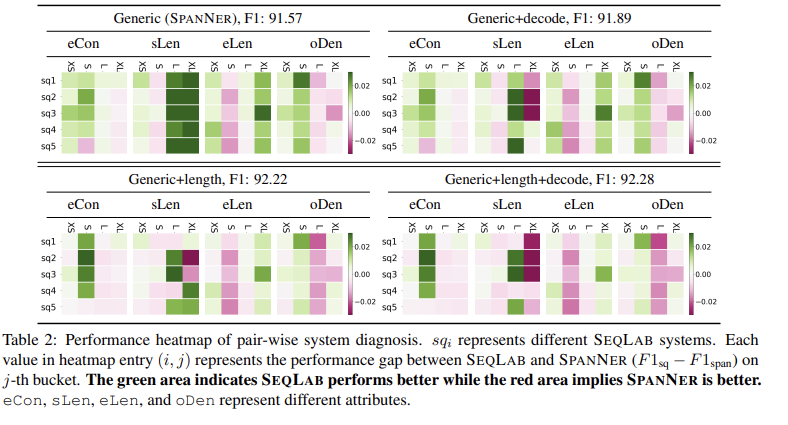

绿色表示seq模型表现好,粉色表示span模型表现好。
从图中的结论:
(1)s pan适合处理中等句子,连续度高的实体、实体长度中等的,OOVS多的语料;
(2)引入启发式解码和span length后,span模型的效果开始改善。
(3)seq 模型适合处理句子长度长的、实体长度长,连续度低的,OOVS少的语料。(i) entities are long and with lower label consistency
; (3)模型的ensemble learning
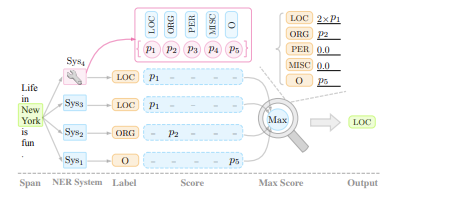
对于多个模型预测的结果,做分析,选择最大的做为span的标签。
这里的图是不是给的不太好,因为最后得到的是span和对应的标签,每个span的预测是怎么得到的?是前一节中提到的所有的可能吗?还是模型预测出的span?
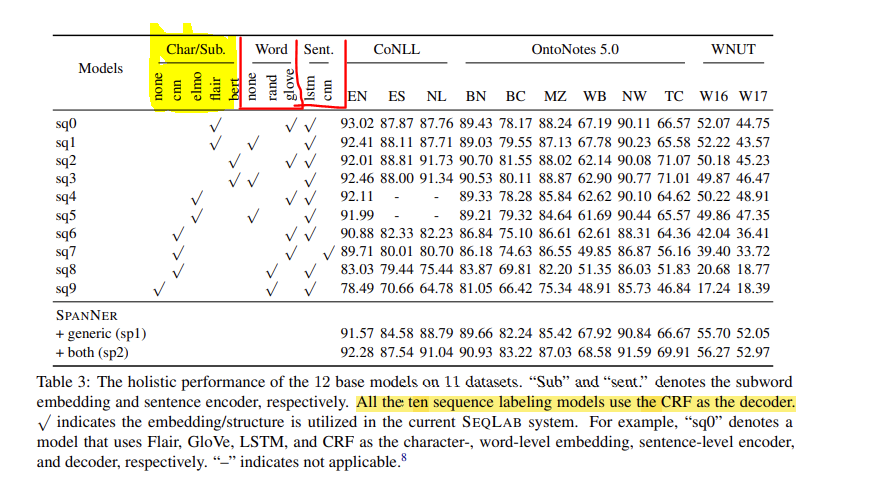
实验是在采用不同的 子词嵌入技术以及不同的word向量表示技术和sent编码技术上进行的,比较了不同模型的结果。
最后的实验, 是比较了不同模型的联合策略,基于投票的方式(选择多个模型中分值最高的、加权求值),基于堆叠的方式(随机森林、支持向量机等),然后就说明了文中的模型的优势。
但是,文中的模型,不同样也是在多个模型的基础上,对每个label求得分值,确定最终的标签吗?
(创新性,目前我没有太看出来)
Original: https://blog.csdn.net/Hekena/article/details/123618579
Author: 做好当下,一切随缘吧
Title: SPANNER: Named Entity Re-/Recognition as Span Prediction
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/556806/
转载文章受原作者版权保护。转载请注明原作者出处!