

引言
最近刚在实验楼做了这个关于知识图谱的课程,想总结点什么,也勾起了我的一点回忆,因为最早我写博客就是为了记录一些我对web与nlp还有爬虫的笔记,博客标签上就是标的这些。结果最后发现这三者我都没有在继续做下去了,而是工作于视频图像,有够戏剧化的,所以这里,想找回一点当年那种感觉。
知识图谱架构
根据一文揭秘!自底向上构建知识图谱全过程,构建知识图谱一般分为3个部分,分别为:
- 信息抽取:从各种类型的数据源中提取出实体、属性以及实体间的相互关系,在此基础上形成本体化的知识表达;
- 知识融合:在获得新知识之后,需要对其进行整合,以消除矛盾和歧义,比如某些实体可能有多种表达,某个特定称谓也许对应于多个不同的实体等;
- 知识加工:对于经过融合的新知识,需要经过质量评估之后(部分需要人工参与甄别),才能将合格的部分加入到知识库中,以确保知识库的质量,见下图:
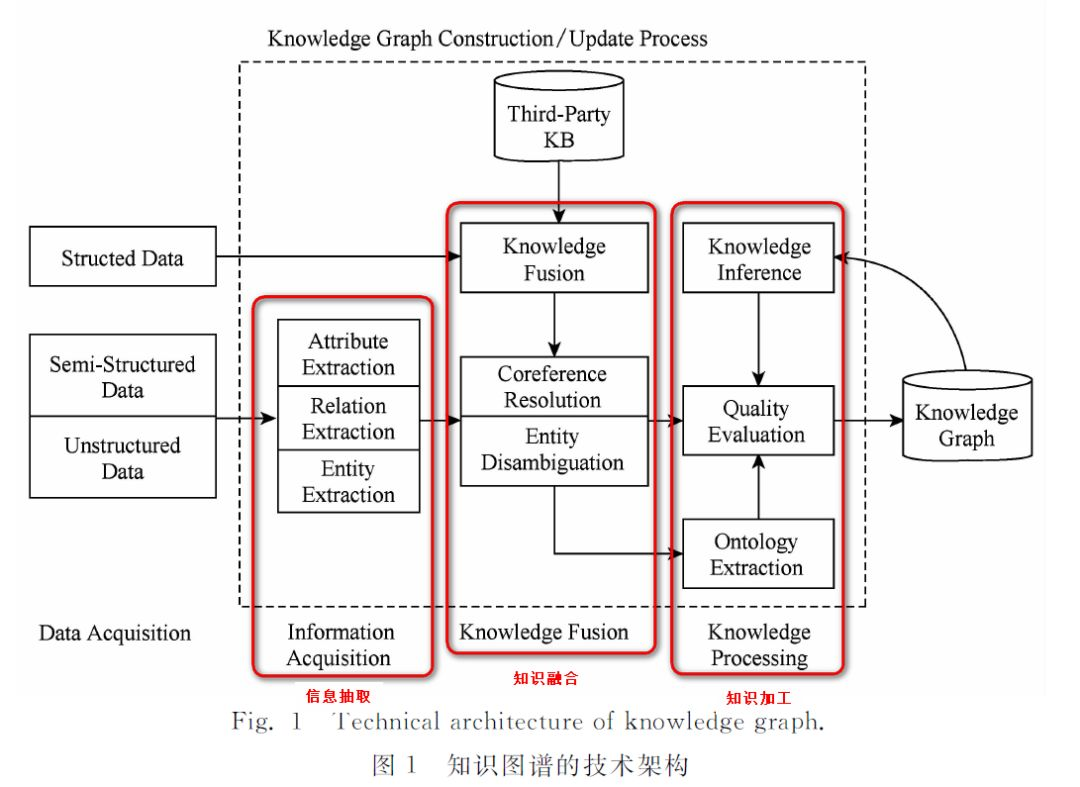

本次实验,只对知识图谱的信息抽取进行分析。
; 什么是信息提取
知识图谱的构建是知识图谱应用的基础。在现实世界中,存在着大量非结构化的数据,如整套金庸小说,或者是百度百科等对金庸小说人物的介绍,如何将这些非结构化的数据提取成结构化的数据,就需要借助自然语言处理等技术了,需要的技术包括但不限于如下:
2.1 命名实体识别
命名实体识别是自然语言处理的一个基础任务,其目的是识别语料中人、地名、书名等命名实体。
命名实体识别的方法基本分为两种:
- 基于规则与词典的方法:为目标实体编写模板,然后在原始语料中进行匹配
- 基于统计机器学习的方法:通过机器学习的方法对原始语料进行训练,然后再利用训练好的模型去识别实体
2.2 关系抽取
文本预料经过实体抽取,得到的是一系列离散的命名实体,为了得到语义信息,还得从语料中提取出实体之间的关联关系,通过关系将实体联系起来,才能够形成网状的知识结构。
知识图谱的本质是一种图形数据库,图数据库的基本含义是以”图”这种数据结构存储和查询数据。图形数据库是 NoSQL 数据库的一种类型,它应用图形理论存储实体之间的关系信息。
常见的图形数据库有 Neo4j,FlockDB,AllegroGrap 等。在本课程中主要学习 Neo4j ,Neo4j 是一个流行的开源图形数据库。Neo4j 基于 Java 实现,兼容 ACID 特性,也支持其他编程语言,如 Ruby 和 Python。
试验环境
这里因为是一个介绍性的实验,并没有将整个构建知识图谱完整一套进行建立,所以如果是想大致浏览整个流程,只需要普通的能搭建neo4j的服务器以及python环境如下:
pip install tensorflow==1.13.1
pip install keras==2.2.4
pip install git+https://www.github.com/keras-team/keras-contrib.git
pip install py2neo
命名实体识别实验原理
1. 命名实体识别任务
命名实体识别是自然语言处理中的一项基础任务,命名实体指文本中具有特定意义的实体,通常包括人名,地名,专有名词等。
如在文本”张无忌,金庸武侠小说《倚天屠龙记》人物角色,中土明教第三十四代教主。武当七侠之一张翠山与天鹰教紫微堂主殷素素之子,明教四大护教法王之一金毛狮王谢逊义子。” 中,
- 人名实体有:张无忌,张翠山,殷素素,谢逊
- 书名实体有:倚天屠龙记
- 门派实体有:明教,武当,天鹰教
因此,命名实体识别任务通常包括两部分
- 实体的边界识别:如正确识别”张翠山”,而不是”张翠”或”张翠山与”等
- 确定实体的类型:如张无忌为人名实体,而不是门派实体或者书名实体
命名实体的标注方法有多种,在本实验中使用 BMEO 标注方法
- B 实体词首
- M 实体词中
- E 实体词尾
- O 非实体
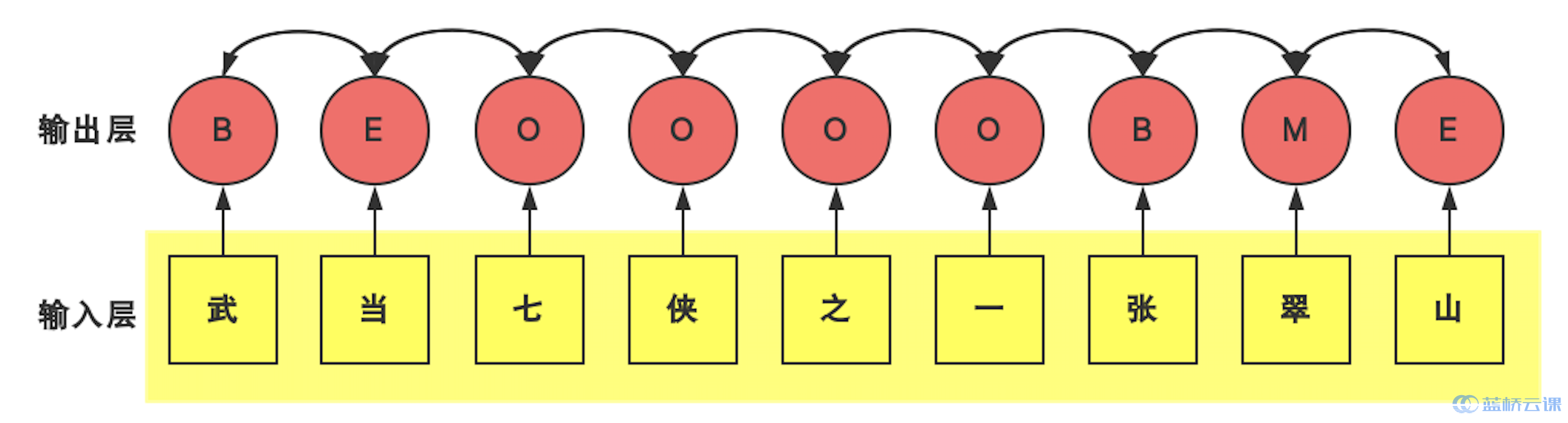
结合实体类型,”武当七侠之一张翠山与天鹰教紫微堂主殷素素之子” 这份文本就会被标注为”武/门派_B 当/门派_E 七/O 侠/O 之/O 一/O 张/人名_B 翠/人名_M 山/人名_E 与/O 天/门派_B 鹰/门派_M 教/门派_E 紫/O 微/O 堂/O 主/O 殷/人名_B 素/人名_M 素/人名_E 之/O 子/O”
2. 序列标注
命名实体识别任务本质上是一个序列标注问题,即给序列中的每一帧进行分类,在这里每一帧代表一个字。如”武当七侠之一张翠山”,不考虑实体类型,则共有四个标签 BMEO。既然是分类问题,就很自然地想到逐帧分类:即训练一个判别器,输入一个字,输出该字的类别,如下图所示:

但是实际上,并不是说”张”这个字一定代表实体词首,有可能是”张开”这个词的起始,但”张开”并非实体。因此,每一帧都是上下文关联的,如”张”后面跟着”翠山”,那么”张”就是实体词首,反之则不一定,如下图所示:
同时目标输出序列本身会带有一些上下文的关联,比如实体词尾前一帧不可能是非实体,实体词中后一帧要么是实体词中要么是实体词尾。这与普通的分类任务不同。如果一个输入有 n n n 帧,每一帧的标签有 k k k 种可能性,那么理论上就有 k n k^n k n 种不同的输出。如下图所示,每一个点代表一个标签的可能性,点之间的连线表示标签之间的关联,而每一条完整的路径,表示一种输出。
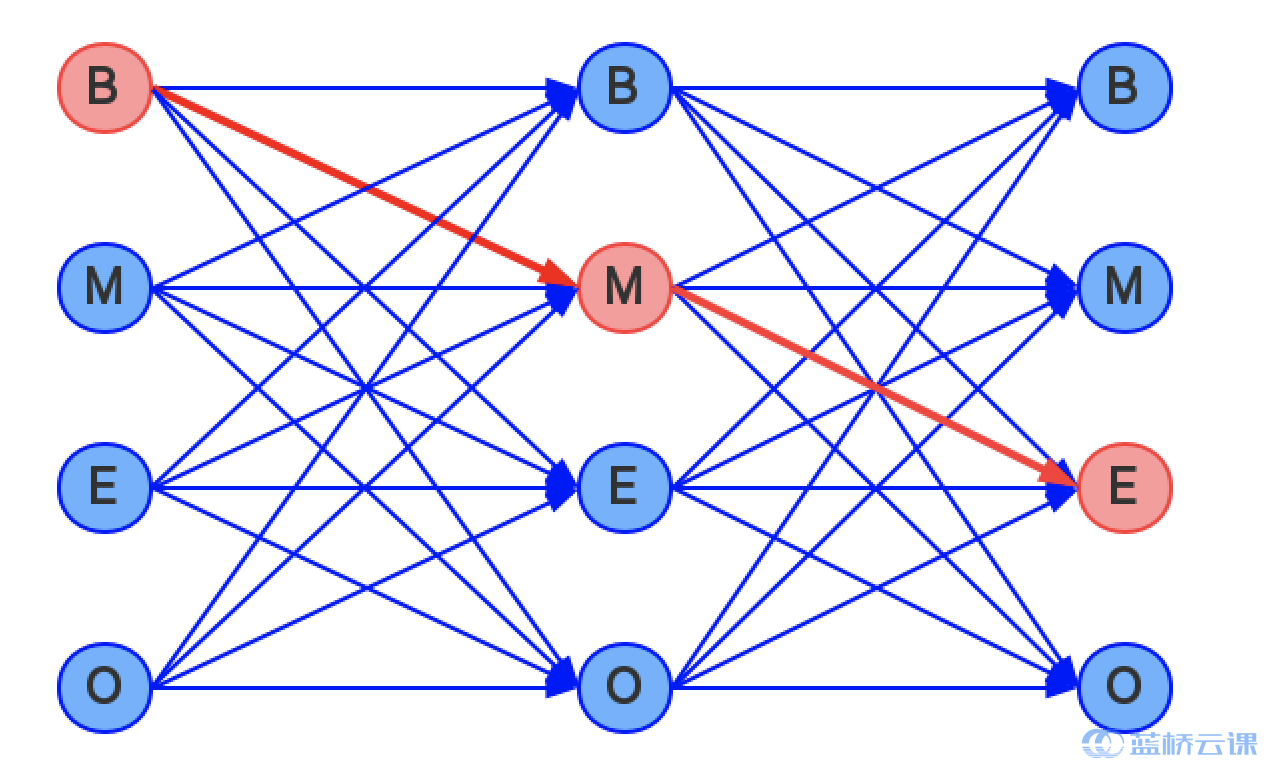
综上所述,逐帧分类是将序列标注看成 n n n 个 k k k 分类问题,而真正的序列标注是 1 个 k n k^n k n 分类问题。
;3. 条件随机场
条件随机场(conditional random field,简称 CRF),是是一种鉴别式机率模型。在序列标注问题中,我们要计算的是条件概率 P ( y 1 , . . . , y n ∣ x ) , x = ( x 1 , . . . , x n ) P(y_1,…,y_n|x), x=(x_1,…,x_n)P (y 1 ,…,y n ∣x ),x =(x 1 ,…,x n ) 。可以理解为给予图中的边以权重,并找到权重最高的一条路径作为输出。
CRF 中定义了特征函数来给边赋予权重,特征函数定义为 f ( s , i , l i , l i − 1 ) f(s,i,l_i,l_{i-1})f (s ,i ,l i ,l i −1 )
- s s s 输入的句子
- i i i 句子s s s 中第i i i 个词
- l i l_i l i 第i i i 个词的标签
- l i − 1 l_i-1 l i −1 第i − 1 i-1 i −1 个词的标签
定义好特征函数后,给每一个特征函数f j f_j f j 赋予一个权重λ j \lambda_j λj ,从而,对于输入 s s s 和 标注序列 l l l,l l l 的评分为
s c o r e ( l ∣ s ) = ∑ j = 1 m ∑ i = 1 n λ j f j ( s , i , l i , l i − 1 ) score(l|s)=\sum^m_{j=1}\sum^n_{i=1}\lambda_j f_j(s,i,l_i,l_{i-1})s c o r e (l ∣s )=∑j =1 m ∑i =1 n λj f j (s ,i ,l i ,l i −1 )
对分数进行指数化和标准化,就可以得到标注序列 l l l 的概率值 p ( l ∣ s ) p(l|s)p (l ∣s ),如下所示
p ( l ∣ s ) = exp [ s c o r e ( l ∣ s ) ] ∑ l ′ exp [ s c o r e ( l ′ ∣ s ) ] p(l|s)=\frac{\exp[score(l|s)]}{\sum_{l’}\exp[score(l’|s)]}p (l ∣s )=∑l ′exp [s c o r e (l ′∣s )]exp [s c o r e (l ∣s )]
4. BiLSTM-CRF
长短期记忆网络(Long Short-Term Memory,简称 LSTM),是循环神经网络(Recurrent Neural Network,简称 RNN)的一种,BiLSTM 是由前向 LSTM 与后向 LSTM 组合而成,由于其设计的特点,在自然语言处理任务中都常被用来建模上下文信息。
与 CRF 不同的是,BiLSTM 依靠神经网络超强的非线性拟合能力,在训练时将数据变换到高维度的非线性空间中去,从而学习出一个模型。虽然 BiLSTM 的精度非常的高,但是在预测时,会出现一些明显的错误,如实体词尾后一帧依然预测为实体词尾等,而在 CRF 中,因为特征函数的存在,限定了标签之间的关系。因此,将 CRF 接到 BiLSTM 上,就可以将两者的特点结合,取长补短,通过 BiLSTM 提取高效的特征,让 CRF 的学习更加有效。
实体抽取实验原理
1. 关系抽取任务
在本实验中,我们关心的是有监督的关系抽取任务,即已知所有文本中包含的关系种类。此时关系抽取的任务形式就是一个文本分类的问题——任务的输入是一句话以及这句话中包含的两个实体,输出是关系类别。
如文本”杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。”中,一共有四个人名实体,要获得”杨康”与”杨铁心”的关系,那么就要把”杨康”,”杨铁心”,”杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。” 这三个数据都输入到算法中。
2. 数据预处理
首先对数据进行位置编码,按句子中各个词离实体的距离进行编码。
如”杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。”中,实体为”杨康”和”杨铁心”。然后记录句子中每个字与实体首字之间的距离。
如
杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。012345678910111213141516171819202122232425
pos_1=[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25],0 就是杨康的起始位置
杨康,杨铁心与包惜弱之子,金国六王爷完颜洪烈的养子。-3-2-1012345678910111213141516171819202122
pos_2=[-3,-2,-1,0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],0 就是杨铁心的起始位置
数据入库方法
主要有三种方式为:
- load csv 批量导入方法
- neo4j-admin import 批量导入方法
- Cypher 实战用法
它们相应的优缺点为:
CREATE 语句LOAD CSV 语句Batch InserterBatch ImportNeo4j-admin import适用场景1 ~ 1 w nodes1 w ~ 10 w nodes千万以上 nodes千万以上 nodes千万以上 nodes速度1000 nodes/s5000 nodes/s数万 nodes/s数万 nodes/s数万 nodes/s优点使用方便,可实时插入使用方便,可加载本地和远程 CSV;可实时插入速度相比于前两个有数量级的提升基于 Batch Inserter,可直接运行编译好的 jar 包,可以在已存在的数据库中导入数据比 Batch Import 占用更少的资源缺点速度慢需要将数据转换成 CSV需要转成 CSV;只能在 JAVA 中使用;必须停止 Neo4j需转成 CSV;必须停止 Neo4j需要转成 CSV;必须停止 Neo4j;只能生成新的数据库,而不能在已存在的数据库中插入数据
Original: https://blog.csdn.net/submarineas/article/details/123310704
Author: submarineas
Title: 知识图谱构建实验笔记(一):环境搭建与试验原理介绍
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/555579/
转载文章受原作者版权保护。转载请注明原作者出处!