

K-means算法是常用的聚类算法:在给定K值和K个初始类簇中心点的情况下,首先把每个点(即数据记录)分配到离其最近的类簇中心点所代表的类簇中。其次根据一个类簇中内的所有点重新计算该类簇的中心点(取平均值)。然后再迭代的进行分配点和更新类簇中心点的步骤,直至类簇中心点的变化很小(即达到稳定状态,各类簇中数据点不再发生变化),或者达到指定的迭代次数为止。
算法主体
一、簇
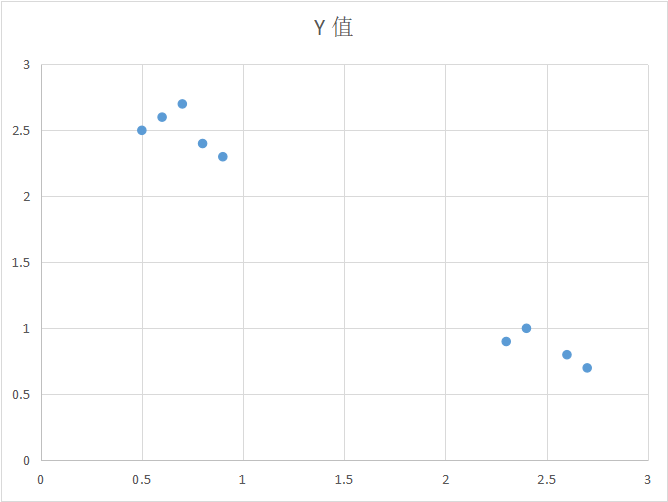

1、簇的属性:簇中所有的数据点应彼此相似;
不同的簇中数据点尽可能不相同;
2、聚类的不同评估度量标准
聚类的主要目的不仅仅是创建簇,而是创建好的,有意义的簇。
有意义的簇评估标准:
标准一:Inertia标准
其实质是计算簇内所有点到簇的质心的距离总和,这个簇内距离总和被称为簇内距离(如下图所
示),而Inertia的最终值是这些簇内距离的总和,且Inertia试图最小化簇内距离,确保簇的紧凑性。
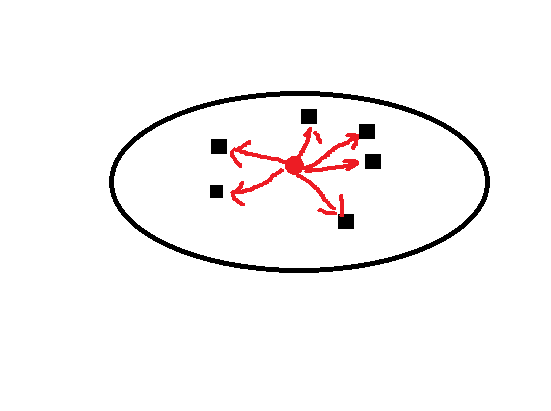
标准二:Dunn Index(邓恩指数)
除了簇内质心和各个数据点的距离,Dunn Index还考虑两个簇内质心的距离,这被称为簇间距离。
Dunn Index的值为簇间距离最小值与簇内距离最大值的比。

根据其标准,Dunn Index值越大,簇越好。即尽可能保证最小簇间距离尽可能大,最大簇内距离尽可能小。
K-means算法:
使用之前记得用pip 安装numpy 和 matplotlib
import pandas as pd
import numpy as np
import random as rd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\BaiduNetdiskDownload\K-means算法代码及数据表\clustering.csv')#根据文件实际位置填写
data.head()
X = data[["LoanAmount","ApplicantIncome"]]
print(X)
#可视化
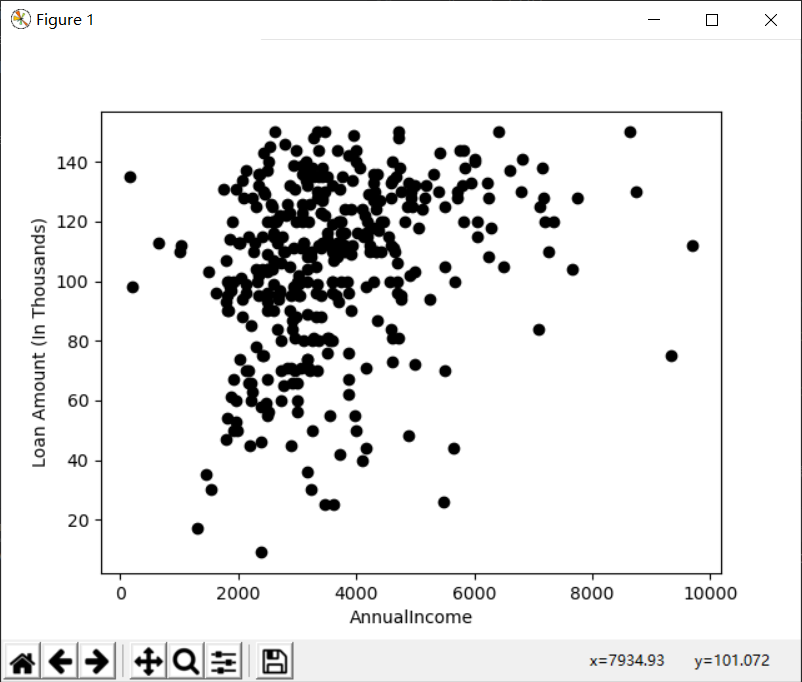
plt.scatter(X["ApplicantIncome"],X["LoanAmount"],c='black')
plt.xlabel('AnnualIncome')
plt.ylabel('Loan Amount (In Thousands)')
plt.show()
第1步:选择簇的个数
K=3
第2步:随机选择观察值作为簇心
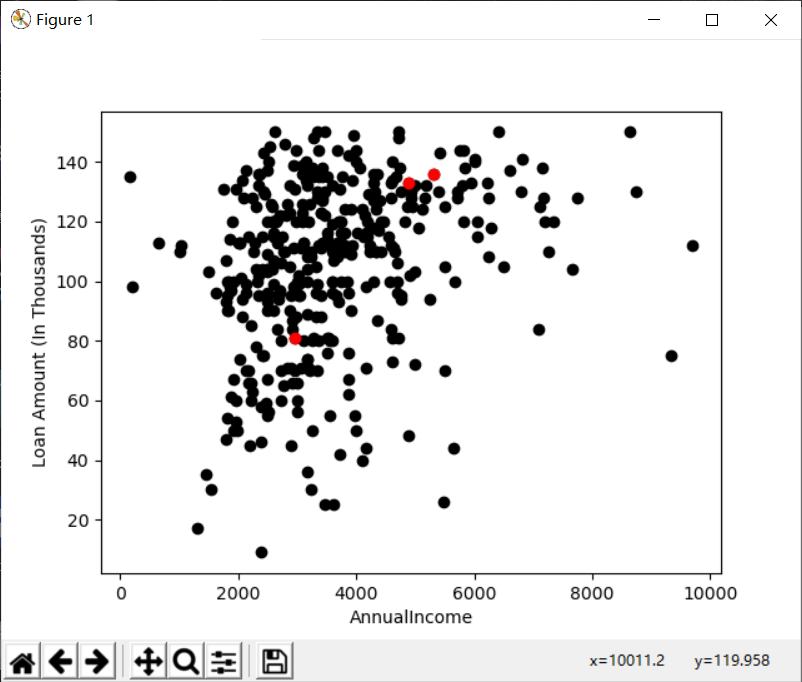
Centroids = (X.sample(n=K))
plt.scatter(X["ApplicantIncome"],X["LoanAmount"],c='black')
plt.scatter(Centroids["ApplicantIncome"],Centroids["LoanAmount"],c='red')
plt.xlabel('AnnualIncome')
plt.ylabel('Loan Amount (In Thousands)')
plt.show()
第3步:将所有点分配给到某个质心距离最近的簇
第4步:重新计算新形成的簇的质心
第5步:重复第三步和第四步
diff = 1
j=0
while(diff!=0):
XD=X
i=1
for index1,row_c in Centroids.iterrows():
ED=[]
for index2,row_d in XD.iterrows():
d1=(row_c["ApplicantIncome"]-row_d["ApplicantIncome"])**2
d2=(row_c["LoanAmount"]-row_d["LoanAmount"])**2
d=np.sqrt(d1+d2)
ED.append(d)
X[i]=ED
i=i+1
C=[]
for index,row in X.iterrows():
min_dist=row[1]
pos=1
for i in range(K):
if row[i+1] < min_dist:
min_dist = row[i+1]
pos=i+1
C.append(pos)
X["Cluster"]=C
Centroids_new = X.groupby(["Cluster"]).mean()[["LoanAmount","ApplicantIncome"]]
if j == 0:
diff=1
j=j+1
else:
diff = (Centroids_new['LoanAmount'] - Centroids['LoanAmount']).sum() + (Centroids_new['ApplicantIncome'] - Centroids['ApplicantIncome']).sum()
print(diff.sum())
Centroids = X.groupby(["Cluster"]).mean()[["LoanAmount","ApplicantIncome"]]
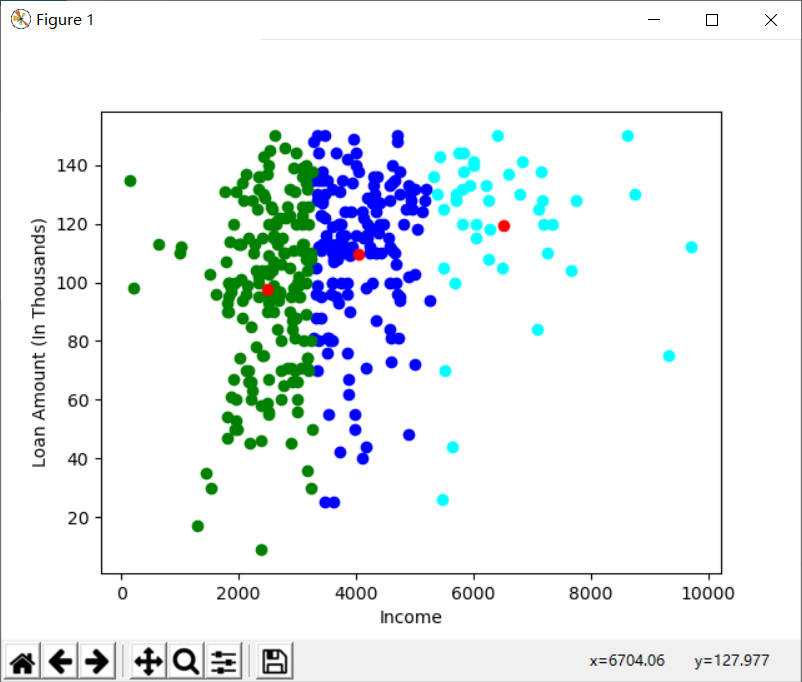
color=['blue','green','cyan']
for k in range(K):
data=X[X["Cluster"]==k+1]
plt.scatter(data["ApplicantIncome"],data["LoanAmount"],c=color[k])
plt.scatter(Centroids["ApplicantIncome"],Centroids["LoanAmount"],c='red')
plt.xlabel('Income')
plt.ylabel('Loan Amount (In Thousands)')
plt.show()
运行结果:
数据集
https://download.csdn.net/download/m0_52854170/35405604?spm=1001.2014.3001.5503
Original: https://blog.csdn.net/m0_52854170/article/details/121022034
Author: 我心如凪
Title: (笔记)K-means算法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/550926/
转载文章受原作者版权保护。转载请注明原作者出处!