

基本概念不再介绍,直接进行关键点的总结叙述。
kmeans算法又名k均值算法,K-means算法中的k表示的是聚类为k个簇,means代表取每一个聚类中数据值的均值作为该簇的中心,或者称为质心,即用每一个的类的质心对该簇进行描述。
其算法思想大致为:先从样本集中随机选取 k个样本作为簇中心,并计算所有样本与这 k个”簇中心”的距离,对于每一个样本,将其划分到与其距离最近的”簇中心”所在的簇中,对于新的簇计算各个簇的新的”簇中心”。
根据以上描述,我们大致可以猜测到实现kmeans算法的主要四点:
(1)簇个数 k 的选择
(2)各个样本点到”簇中心”的距离
(3)根据新划分的簇,更新”簇中心”
(4)重复上述2、3过程,直至”簇中心”没有移动
优缺点:
优点:容易实现
缺点:可能收敛到局部最小值,在大规模数据上收敛较慢
四大过程步骤:
Step1.K值的选择
k 的选择一般是按照实际需求进行决定,或在实现算法时直接给定 k 值。
说明:
A.质心数量由用户给出,记为k,k-means最终得到的簇数量也是k
B.后来每次更新的质心的个数都和初始k值相等
C.k-means最后聚类的簇个数和用户指定的质心个数相等,一个质心对应一个簇,每个样本只聚类到一个簇里面
D.初始簇为空
Step2.距离度量
将对象点分到距离聚类中心最近的那个簇中需要最近邻的度量策略,在欧式空间中采用的是欧式距离,在处理文档中采用的是余弦相似度函数,有时候也采用曼哈顿距离作为度量,不同的情况实用的度量公式是不同的。
2.1.欧式距离
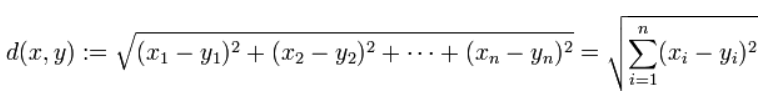

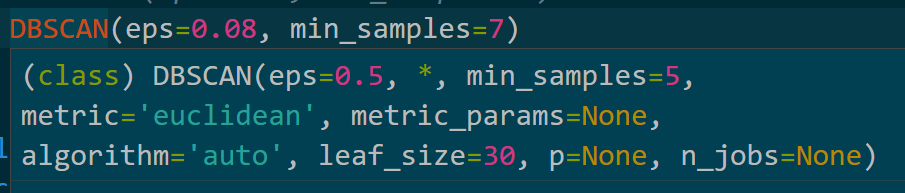
像DBSCAN中就有metric 参数进行距离度量方式的设定。
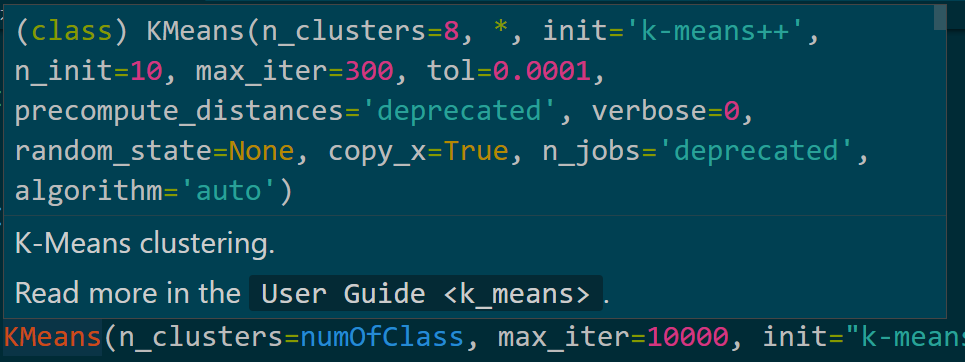
k-means就没有
如果有兴趣自己优化,可以直接进入库底层代码进行修改。
按住 Ctrl+鼠标左键 点击对应方法即可进入底层代码

底层代码文件名称为 _kmeans.py
2.2.曼哈顿距离
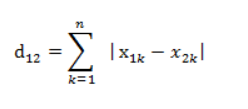
2.3.余弦相似度
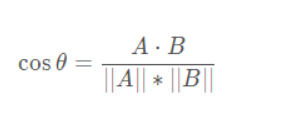
A与B表示向量(x1,y1),(x2,y2)
分子为A与B的点乘,分母为二者各自的L2相乘,即将所有维度值的平方相加后开方
说明:
A.经过step2,得到k个新的簇,每个样本都被分到k个簇中的某一个簇
B.得到k个新的簇后,当前的质心就会失效,需要计算每个新簇的自己的新质心
Step3.新质心的计算
对于分类后的产生的k个簇,分别计算到簇内其他点距离均值最小的点作为质心(对于拥有坐标的簇可以计算每个簇坐标的均值作为质心)
说明:
A.比如一个新簇有3个样本:[[1,4], [2,5], [3,6]],得到此簇的新质心=[(1+2+3)/3, (4+5+6)/3]
B.经过step3,会得到k个新的质心,作为step2中使用的质心
Step4.是否停止K-means
质心不再改变,或给定loop最大次数loopLimit
说明:
A当每个簇的质心,不再改变时就可以停止k-menas
B.当loop次数超过looLimit时,停止k-means
C.只需要满足两者的其中一个条件,就可以停止k-means
C.如果Step4没有结束k-means,就再执行step2-step3-step4
D.如果Step4结束了k-means,则就打印(或绘制)簇以及质心
Original: https://blog.csdn.net/qq_38563206/article/details/120940393
Author: ASS-ASH
Title: K-means聚类及距离度量方法小结
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/549502/
转载文章受原作者版权保护。转载请注明原作者出处!