

来源: AINLPer 微信公众号( 每日更新…)
编辑: ShuYini
校稿: ShuYini
时间: 2021-11-18
昨天给大家分享的是一篇EMNLP2021关于关系提取的文章,文章中将关系提取看作端到端任务进行处理,在关系提取和关系分类上都取得了不错的效果。今天给大家再分享一篇关于命名实体识别的文章。
注意!! 是中文命名实体识别呦。
NER存在的问题及解决方案
在统计机器学习算法之后,命名实体识别进入了神经网络时代。研究人员开始基于字符嵌入和词嵌入使用循环神经网络(RNN)来识别句子中的命名实体,解决了传统统计方法存在的特征工程问题;然后,2015年双向长短期记忆 (Bi-LSTM) 网络首次被应用于中文命名实体识别,成为基线模型之一,命名实体识别任务的性能因此得到了极大的提高;最后基于Transformer的大规模预训练语言模型也应用到命名实体识别任务中来,自注意力机制可以更好地捕捉句子中的长距离依赖,并行设计适合海量计算,这些预训练的模型大大提升命名实体识别的性能。
但特定问题上我们仍然需要更多的知识来提高它们的表现。在中文 NER 中,字符替换是一种复杂的语言现象。由于共享相同的组件或具有相似的发音,一些汉字非常相似。人们用相似的字符替换命名实体中的字符以生成新的搭配,但指的是同一个对象。它在互联网时代变得更加普遍,经常被用来避免互联网审查或只是为了好玩。这种字符替换对那些预先训练好的语言模型并不友好,因为新的搭配是偶然的。结果,它总是导致NER任务中无法识别或识别错误。
针对上面我们遇到的问题,该篇文章 提出了一种基于多特征融合嵌入(MFE)的中文命名实体识别方法,以加强中文的语言模式并处理中文命名实体识别中的字符替换问题。 MFE 将语义、字形和语音特征融合在一起。 在字形域中,我们将汉字分解成组件来表示结构特征,以便具有相似结构的字符可以具有紧密的嵌入空间表示;除此之外还提出了一种改进的语音系统,使计算汉字之间的语音相似度变得合理。实验表明,我们的方法 提高了中文 NER 的整体表现,尤其是在非正式语言环境中表现良好。


本篇文章的主要贡献:
• 特别针对汉字替换问题,提出了汉字的多特征融合嵌入方法。
• 对于汉字替换中的字形特征,采用”五笔画”编码方式,表示汉字的结构模式,使得具有相似字形结构的汉字在嵌入空间中更加接近。
• 为了表示汉字替换中的语音特征,我们提出了一种名为”转拼音”的新方法,使评估汉字之间的语音相似性成为可能。
• 实验表明,我们的方法提高了 NER 模型的整体性能,并且可以更有效地找到替代的中文 NER。
MFE 算法介绍:
如下图所示,本文 Multi-feature Fusion Embedding 主要由语义嵌入、带有”五笔画”的字形嵌入和合成语音嵌入三部分组成,我们认为它们在中文命名实体识别中是互补的。 所有三个嵌入部分的选择和设计都是基于相似性这一个简单原则

采用这种方法 Multi-feature Fusion Embedding 可以更好地表示汉字在嵌入空间中的分布。
预训练模型选择
在中文句子中,单个字符并不代表一个词,因为中文语法中没有自然分词。从技术上讲,我们有两种选择来 获取中文嵌入。第一种方式是 词嵌入,即试图将中文句子分成词并得到词的嵌入,但受限于分词工具的准确性。另一种是 字符嵌入,将汉字映射到语义空间中的不同嵌入向量。在实践中,它在命名实体识别中表现更好。我们的工作需要使用字符嵌入,因为字形和语音嵌入是针对单个汉字的。 BERT Kenton & Toutanova (2019) 有中文版本,可 以更准确地表达汉字的语义特征,因此在NER任务中表现更好。
“五笔画”编码
如下图所示:汉字’pu3’(某处靠近河流)被汉字书写习惯分成四个不同的字根,稍后将它们映射到英文字符,以便我们通过引入one-hot来对它们进行编码。 对于每个字符根,我们可以得到一个 25 维向量。 在本文中,为了降低空间复杂度,我们将这些 25 维向量汇总为字形嵌入向量。 我们还列出了两个不同的字符,”fu3″(”甫”:官方职位)和”qiao2″(”桥”:桥梁),并计算它们之间的相似度。 “pu3″和”fu3″这两个字符在嵌入空间中具有相似的分量,而”qiao2″和”pu3″则相距更远,这为NER模型提供了额外的识别模式。

拼音嵌入
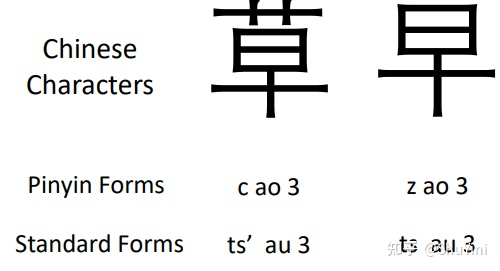
但是,”拼音”系统有一个重要的缺陷。一些相似的读音用完全不同的音标表示。对于上图中的示例,”cao3″(草)和”zao3″(早期)的发音非常相似,因为两个助词”c”和”z”的发音几乎相同,许多母语人士可能会混淆它们。这种相似性无法用拼音系统中的音标来表示,其中”c”和”z”是独立的助词。为此本文提出了”转拼音”系统来表示字符发音,其中助词和元音被转换成标准形式,并保持在”拼音”系统中的音调。转换后,’c’变成’ts’,’z’变成’ts0’,只是语音权重不同。我们还对现有的映射规则进行了一些调整,使”拼音”中相似的音标可以具有相似的发音。通过结合”拼音”和国际标准音标系统,可以很好地描述和评估汉字发音之间的相似性。
多特征融合嵌入
这里并不是直接融合这三个特征部分,因为每个部分都来自不同的域。 这里给出三种融合方案:
Concat 连接三个嵌入部分似乎是最直观的方式,我们可以将它们放在一起,让 NER 模型做其他工作。 在本文中,我们选择这种融合策略是因为它表现得非常好。
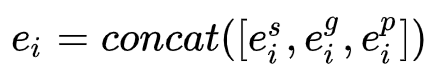
Concat+Linear 如果我们放置一个线性层来帮助进一步融合它们也是有意义的。 从技术上讲,它可以节省空间并提高NER模型的训练速度. 【作者不推荐使用】
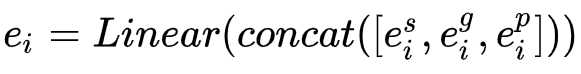
Multiple LSTMs 还有一种复杂的方法来融合所有三个特征。 有时,我们将不同的功能混合在一起是没有意义的。 所以,我们也可以让他们分开,从不同方面训练NER模型,并使用一个线性层来计算结果的加权平均值。 在这项工作中,我们使用 BiLSTM 从不同的嵌入中提取模式,并使用一个线性层来计算加权平均值。
实验结果
1、在中文简历、人民日报、MSRA、微博、替代测试数据集上,对语义嵌入进行比较
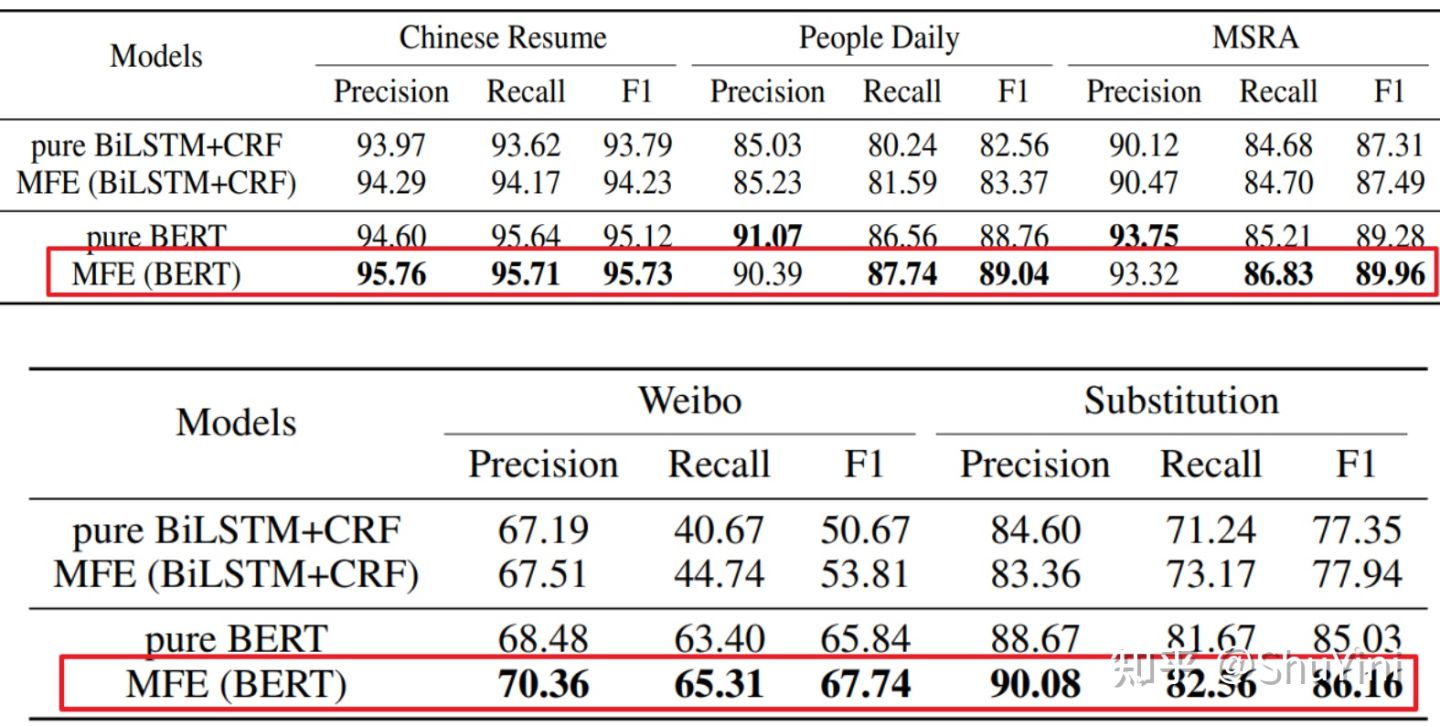
2、多种特征混合方式的对比

; 推荐阅读
1、【南洋理工&&含源码】鲁棒问答的内省蒸馏(IntroD)
2、【NLP论文速递】邮件主题生成 && 舆论检测及立场分类
3、【英国谢菲尔德大学&&含源码】社交媒体舆论控制(RP-DNN)
4、【硬核干货,请拿走!!】历年IJCAI顶会论文整理(2016-2021)
6、 必看!!【AINLPer】自然语言处理(NLP)领域知识&&资料大分享
7、收藏!「自然语言处理(NLP)」你可能用到的数据集(一)
8、收藏!「自然语言处理(NLP)」你可能用到的数据集(二)
9、重磅!「自然语言处理(NLP)」一千多万公司企业注册数据集
10、收藏!!「自然语言处理(NLP)」学术界全球知名学者教授信息大盘点(全)!
11、「自然语言处理(NLP)论文推送」清华大学XQA数据集(含源码)!
最后不是最后
关注 AINLPer 微信公众号( 每日都有最新的论文推荐给你!!)
Original: https://blog.csdn.net/yinizhilianlove/article/details/121483405
Author: yinizhilianlove
Title: 中文命名实体识别—基于多特征融合嵌入
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531143/
转载文章受原作者版权保护。转载请注明原作者出处!