

基于BERT适配器的词典增强型中文序列标注
- 摘要
- 介绍
- 相关工作
* - 基于词典
- 预训练模型
- 混合模型
- BERT适配器
- 方法
* - Char-Words Pair Sequence(字符-词对序列)
- Lexicon Adapter(词典适配器)
- Lexicon Enhanced BERT(词汇加强型BERT)
- Training and Decoding(训练和解码)
- 实验
* - 数据集
– - 实验设置
– - 结果
– - 结论
摘要
- 基于词汇信息和BERT等预训练模型有各自的优势,我们将它们 结合起来,探索中文序列标注任务。
- 现有的方法仅仅通过浅层和随机初始化的序列层来融合词汇特征,而没有将它们集成到BERT的 底层。
- 本文提出了一种用于中文序列标注的词汇增强型BERT(Licion Enhanced BERT,简称LEBERT),它通过词典适配层将外部词汇知识直接集成到BERT层中。
- 与已有的方法相比,我们的模型在ERT的较低层促进了深度词汇知识融合。在命名实体识别、分词和词性标注三个任务的十个中文数据集上进行实验,结果表明,LEBERT取得了最好的结果。
介绍
序列标注是自然语言处理(NLP)中的一项经典任务,它是为序列中的每个单元分配一个标签。许多重要的语言处理任务,例如词性标注(POS)、命名实体识别(NER)和中文分词,都可以转化为这个问题。目前最先进的序列标记结果是通过神经网络方法实现的。由于中文句子中没有明确的词边界,中文序列标注面临更大的挑战。进行中文序列标注的一种方式是先进行分词(CWS),然后再进行序列标注,但是会受到分词系统传播的分割误差的影响。因此,一些方法直接在字符水平上进行中文序列标注,这已被经验证明更有效。
最近两方面的工作加强了基于字符的神经汉语序列标记。
- 第一种考虑将单词信息整合到基于字符的序列编码器中,以便可以显式建模单词特征。这些方法可以看作是为整合离散结构化知识而设计的神经结构的不同变体。
- 第二种考虑大规模预先训练的上下文嵌入的整合,如BERT,它已被证明能够捕获隐含的词级句法和语义知识。
由于离散和神经表征的不同性质,这两种工作是相辅相成的。最近的工作考虑了词汇特征与中文词性标注的结合、汉语分词以及汉语词性标注。其主要思想是将来自BERT和词典特征的上下文表示集成到神经序列标记模型中(如图1(a))。然而,这些方法没有充分利用ERT的表示能力,因为外部特征没有集成到底层。
受Bert Adapter工作的启发,我们提出了Licion Enhanced BERT(LEBERT),以直接整合BERT的变形器层之间的词典信息。具体地说,通过将汉语句子与现有词典进行匹配,将该句子转换为字符词对序列。词典适配器被设计为使用字符到单词的双线性注意机制动态地提取每个字符最相关的匹配词。词典适配器在BERT中的相邻转换器之间应用(如图1(b)所示),以便词典功能和BERT表示通过BERT内的多层编码器充分交互。在训练期间,我们对BERT和词典适配器进行了微调,以充分利用单词信息,这与BERT适配器(它修复了BERT参数)有很大不同。
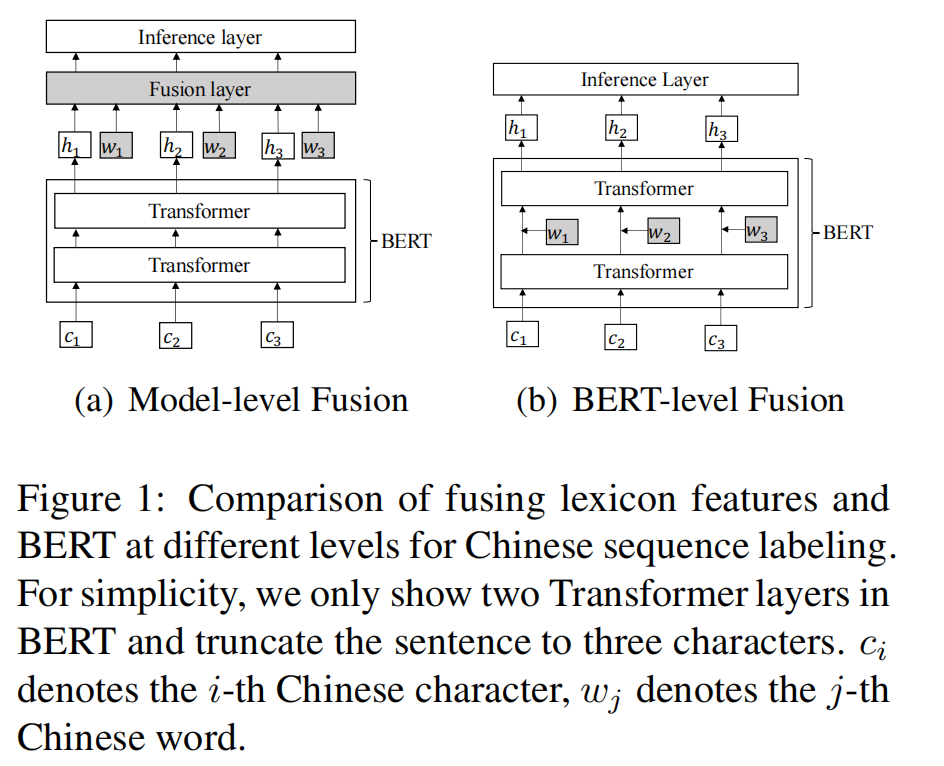

图1是不同层次融合词典特征和BERT进行中文序列标注的比较。为简单起见,在BERT中只显示了两个Transformer层,并将句子截断为三个字符。c i c_i c i 表示第i i i个汉字,w j w_j w j 表示第j j j个汉字。
我们考察了LEBERT算法在三个中文序列标注任务上的有效性,包括中文词性标注任务、中文分词任务和中文词性标注任务。在10个基准数据集上的实验结果表明了该模型的有效性,所有数据集上的每个任务都获得了最先进的性能。此外,我们还进行了全面的比较和详细的分析,从经验上证实了底层特征集成有助于跨度边界检测和跨度类型的确定。
; 相关工作
我们的工作涉及到现有的利用词汇特征和预先训练的模型来改进中文序列标注的神经网络方法。
基于词典
基于词典的模型旨在利用词汇信息来增强基于字符的模型。Zhang和Yang(2018)引入了一种 lattice LSTM用于中文NER,它同时编码字符和单词。通过在训练效率(Gui等人,2019a;Ma等人,2020年)、模型退化(Liu等人,2019年)、图结构(Gui等人,2019b;丁等人,2019年)以及消除对词汇的依赖性(朱和王,2019年)等方面的努力,它得到了进一步的提高。词典信息也被证明对中文分词(CWS)和词性标注(POS)有帮助。Yang等人(2019)将 lattice LSTM应用于CWS,表现出良好的性能。Zhao等人(2020)通过词典增强的适应性注意改进了CWS的结果。Tian等人(2020b)增强了基于字符的中文词性标注模型,增加了N元语法的多通道注意。
预训练模型
基于Transformer的预训练模型,如BERT(Devlin等人,2019年),在中文序列标注方面表现出了优异的性能。Yang(2019)在BERT上简单地添加了Softmax,在CWS上实现了最先进的性能。Meng等人(2019)Hu和Verberne(2020)的研究表明,对于中文NER和中文词性标注,使用BERT的字符特征的模型比基于静态嵌入的方法有很大的优势。
混合模型
最近的工作试图通过利用词典和预先训练的模型各自的优势来整合它们。Ma等人(2020)将独立的特征、BERT表示和词典信息连接在一起,并将它们输入到中文NER的浅融合层(LSTM)中。Li等人(2020)提出了一种Flat-Lattice Transformer来处理字符-单词图,但融合仍处于模型级。类似地,字符n-gram特征和BERT向量被串联以用于联合训练CWS和词性标注(Tian等人,2020b)。我们的方法与上述试图将词典信息和BERT相结合的方法是一致的。不同的是,我们将词汇集成到底层,允许在BERT内进行深入的知识交互。
还有一项工作是使用词典来指导预训练。ERNIE(Sun等人,2019a,b)利用实体级和词级掩蔽以隐式方式将知识集成到BERT中。Jia等人(2020)提议的实体增强的BERT,进一步使用特定于领域的语料库和实体集以及精心设计的字符-实体转换器对BERT进行预训练。Zen(Diao等人,2020)使用多层N-gram编码器增强了中文BERT,但受到N-gram词汇表小的限制。与上述的预训练方法相比,我们的模型使用适配器将词典信息集成到BERT中,效率更高,并且不需要原始文本或实体集。
BERT适配器
BERT Adapter(Houlsby等人,2019年)旨在了解下游任务的特定任务参数。具体地说,它们在预先训练的模型层之间添加适配器,并且仅针对特定任务调优添加的适配器中的参数。Bapna和Firat(2019年)将特定于任务的适配器层注入到预先训练的模型中,用于神经机器翻译。MAD-X(Pfeiffer等人,2020)是一个基于适配器的框架,可以实现高可移植性和参数高效地传输到任意任务。Wang等人。(2020)提出了K-Adapter,将知识注入到预先训练的模型中,并进行进一步的预训练。与它们类似,我们使用词典适配器将词典信息集成到BERT中。主要的区别是,我们的目标是在底层更好地融合词汇和BERT,而不是有效的训练。为了实现这一点,我们对BERT的原始参数进行了微调,而不是固定它们,因为由于这两个信息之间的差异,直接向BERT注入词典特征会影响性能。
方法
提出的词汇增强型BERT的主要架构如图2所示。与BERT相比,LBERT有两个主要的不同之处。首先,在将中文句子转换为字词对序列的情况下,LBERT将汉字特征和词典特征都作为输入。其次,在转换器层之间附加一个词典适配器,使得词典知识能够有效地集成到BERT中。
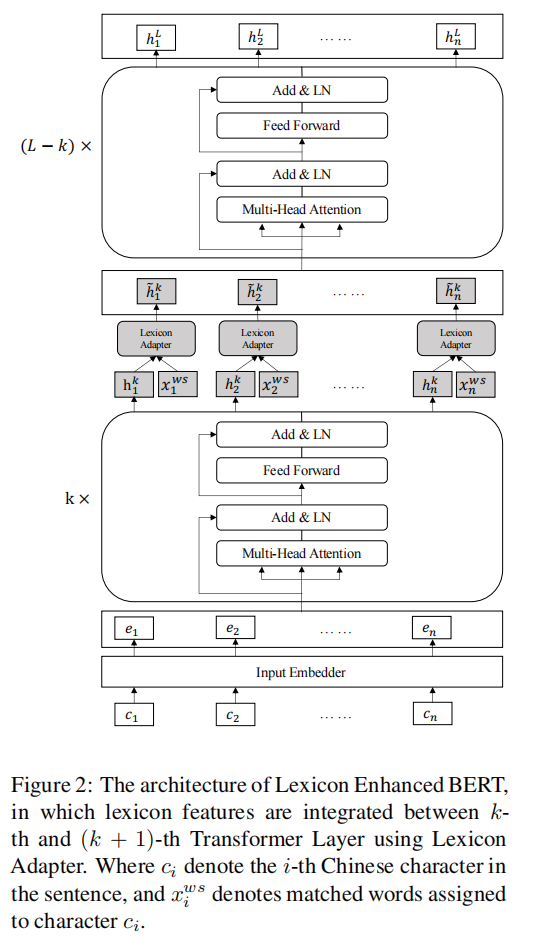
图2 为 Licion Enhanced BERT的体系结构,其中使用Licion Adapter在第k层和第(k+1)转换器层之间集成词典功能。其中c i c_i c i 表示句子中的第i i i个汉字,x n w s x_{n}^{ws}x n w s 表示分配给字符c i c_i c i 的匹配词。
; Char-Words Pair Sequence(字符-词对序列)
汉语句子通常被表示为一个字符序列,只包含字级特征。为了充分利用词典信息,我们将字符序列扩展为字符-词对序列。
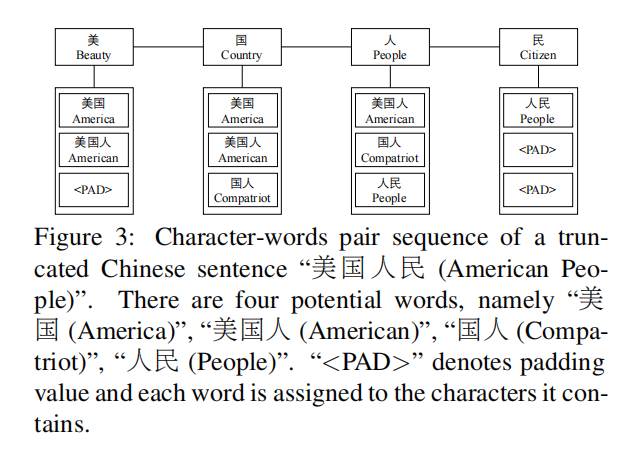
在给定一个汉语词典D D D和一个有n n n个字符的句子s c = c 1 , c 2 , . . . , c n s_c={c_1,c_2,…,c_n}s c =c 1 ,c 2 ,…,c n 的情况下,我们通过将字符序列与D D D进行匹配来找出句子中的所有潜在单词。具体来说,我们首先在D D D的基础上建立一个T r i e Trie T r i e,然后遍历句子的所有字符子序列,并将它们与T r i e Trie T r i e进行匹配,从而得到所有的潜在单词。以截短的句子”美国人民(American People)”为例,我们可以找到四个不同的词,即”美国(America)”、”美国人(American People)”、”国人(Compatriot)”、”人民(People)”。随后,对于每个匹配的单词,我们将其分配给它包含的字符。如图3所示,匹配的单词”美国(America)”被分配给字符”美”和”国”,因为它们构成该单词。最后,我们将每个字与指定的词配对,并将汉语句子转换为字词对序列,即
s c w = ( c 1 , w s 1 ) , ( c 2 , w s 2 ) , . . . , ( c n , w s n ) s_{cw}={(c_1,ws_1),(c_2,ws_2),…,(c_n,w_sn)}s c w =(c 1 ,w s 1 ),(c 2 ,w s 2 ),…,(c n ,w s n ),其中 c i c_i c i 表示句子中的第i i i个字符,w s i ws_i w s i 表示分配给c i c_i c i 的匹配词。
Lexicon Adapter(词典适配器)
句子中的每个位置由两类信息组成,即字级特征和词级特征。与现有的混合模型一致,我们的目标是将词典功能与BERT相结合。具体地说,受最近关于BERT Adapter的研究(Houlsby等人,2019年;Wang等人,2020)的启发,我们提出了一种新颖的词典适配器(LA),如图4所示,它可以直接向BERT注入词典信息。
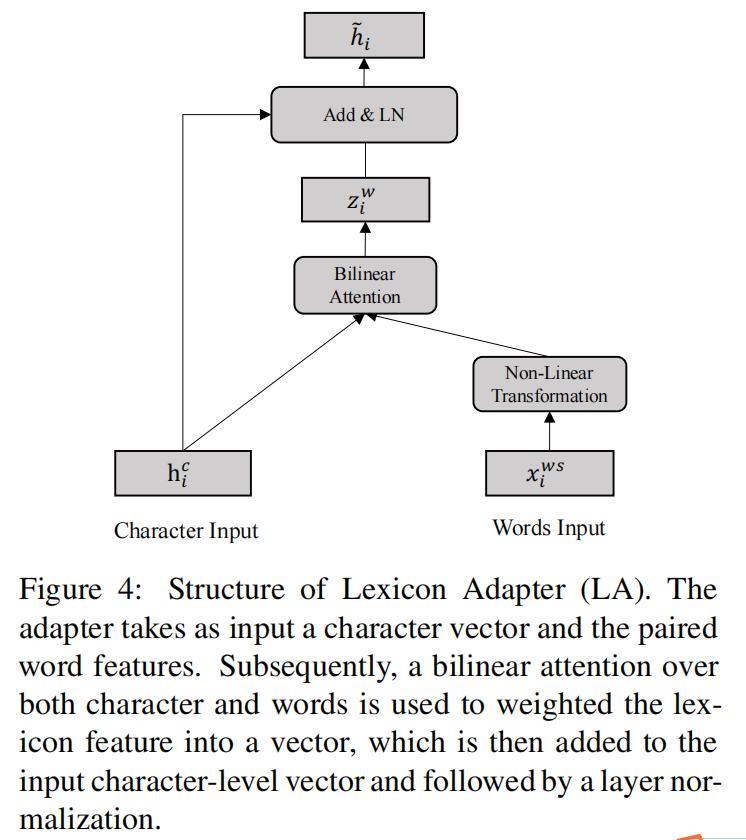
词典适配器接收两个输入,一个字符和成对的单词。对于字符-词对序列中第i i i个位置,输入记为( h i c , x i w s ) \left( h_{i}^{c},x_{i}^{ws} \right)(h i c ,x i w s ),其中h i c h_{i}^{c}h i c 是字符向量,是BERT中某个transformer层的输出,x i w s = { x i 1 w , x i 2 w , . . . , x i m w } x_{i}^{ws}=\left{ x_{i1}^{w},x_{i2}^{w},…,x_{im}^{w} \right}x i w s ={x i 1 w ,x i 2 w ,…,x i m w }是一个单词嵌入的集合。 x i w s x_{i}^{ws}x i w s 中的第j j j个单词表示如下:
x i j w s = e w ( w i j ) x_{ij}^{ws}=e^w\left( w_{ij} \right)x i j w s =e w (w i j )
其中,e w e^w e w是预先训练的单词嵌入查找表,而w i j w_{ij}w i j 是w s i ws_i w s i 中的第j j j个单词。
要对齐这两种不同的表示形式,我们对单词向量应用非线性转换:
v i j w = W 2 ( tan h ( W 1 x i j w + b 1 ) ) + b 2 v_{ij}^{w}=W_2\left( \tan\text{h}\left( W_1x_{ij}^{w}+b_1 \right) \right) +b_2 v i j w =W 2 (tan h (W 1 x i j w +b 1 ))+b 2
其中,W 1 W_1 W 1 是d c d_c d c -by-d w d_w d w 矩阵,W 2 W_2 W 2 是d c d_c d c -by-d c d_c d c 矩阵,b 1 b_1 b 1 ,b 2 b_2 b 2 是标量偏差,d w d_w d w 和d c d_c d c 分别表示词嵌入的维度和BERT的隐藏层维度。
如图3所示,每个字符都与多个单词配对。然而,对每项任务的贡献因词而异。例如,在中文词性标注方面,”美国(America)”和”人民(People)”两个词优于”美国人(American)”和”国人(Compatriot)”,因为它们是句子的基本事实切分。为了从所有匹配的单词中挑选出最相关的单词,我们引入了字符到单词的注意机制。
具体地说,我们将分配给第i i i个字符的所有v i j w v_{ij}^{w}v i j w 表示为V i = ( v i 1 w , . . . , v i m w ) V_i=\left( v_{i1}^{w},…,v_{im}^{w} \right)V i =(v i 1 w ,…,v i m w ),其大小为m m m-by-d c d_c d c ,m m m是所分配字的总数。每个单词的关联性可以计算为:
a i = s o f t max ( h i c W a t t n V i T ) a_i=soft\max \left( h_{i}^{c}W_{attn}V_{i}^{T} \right)a i =s o f t max (h i c W a t t n V i T )
其中,W a t t n W_{attn}W a t t n 是双线性关注度的权重矩阵。因此,可以通过以下方式获得所有单词的加权和:
z i w = ∑ j = 1 m a i j v i j w z_{i}^{w}=\sum_{j=1}^m{a_{ij}v_{ij}^{w}}z i w =j =1 ∑m a i j v i j w
最后,通过以下步骤将加权词典信息注入字符向量:
h ~ = h i c + z i w \tilde{h}=h_{i}^{c}+z_{i}^{w}h ~=h i c +z i w
接下来是dropout layer和normalization layer。
; Lexicon Enhanced BERT(词汇加强型BERT)
Licion Enhanced BERT(LEBERT)是Licion Adapter(LA)和BERT的组合,LA被应用于图2所示的BERT的某一层,具体地说,LA被附加在BERT内的某些transformer之间,从而向BERT注入外部词汇知识。
给定一个具有n n n个字符的中文句子s c = { c 1 , c 2 , . . . , c n } s_c=\left{ c_1,c_2,…,c_n \right}s c ={c 1 ,c 2 ,…,c n },构建相应的字符-词对序列s c w = { ( c 1 , w s 1 ) , ( c 2 , w s 2 ) , . . . , ( c n , w s n ) } s_{cw}=\left{ \left( c_1,ws_1 \right) ,\left( c_2,ws_2 \right) ,…,\left( c_n,ws_n \right) \right}s c w ={(c 1 ,w s 1 ),(c 2 ,w s 2 ),…,(c n ,w s n )},字符{ c 1 , c 2 , . . . , c n } \left{ c_1,c_2,…,c_n \right}{c 1 ,c 2 ,…,c n }首先输入到嵌入器,嵌入器通过添加token、分段、位置嵌入输出E = { e 1 , e 2 , . . . , e n } E=\left{ e_1,e_2,…,e_n \right}E ={e 1 ,e 2 ,…,e n },然后我们将E E E输入 Transformer编码器,每一层变压的动作如下:
G = L N ( H l − 1 + M H A t t n ( H l − 1 ) ) G=LN\left( H^{l-1}+MHAttn\left( H^{l-1} \right) \right)G =L N (H l −1 +M H A t t n (H l −1 ))
H l = L N ( G + F F N ( G ) ) H^l=LN\left( G+FFN\left( G \right) \right)H l =L N (G +F F N (G ))
其中,H l = { h 1 l , h 2 l , . . . , h n l } H^l=\left{ h_{1}^{l},h_{2}^{l},…,h_{n}^{l} \right}H l ={h 1 l ,h 2 l ,…,h n l }表示第l l l 层输出,H 0 = E H^0=E H 0 =E,L N LN L N表示层归一化,M H A t t n MHAttn M H A t t n表示多头注意力机制,F F N FFN F F N表示具有RELU作为隐藏激活函数的两层前馈网络。
为了在第k k k层和k + 1 k+1 k +1层Transformer之间加入词典信息,首先在k k k个连续的Transformer之后得到输出H k = { h 1 k , h 2 k , . . . , h n k } H^k=\left{ h_{1}^{k},h_{2}^{k},…,h_{n}^{k} \right}H k ={h 1 k ,h 2 k ,…,h n k },然后,每对( h i k , x i w s ) \left( h_{i}^{k},x_{i}^{ws} \right)(h i k ,x i w s )通过词典适配器,该词典适配器将i t h i_{th}i t h 对转化为h ~ i k \tilde{h}{i}^{k}h ~i k :
h ~ i k = L A ( h i k , x i w s ) \tilde{h}{i}^{k}=LA\left( h_{i}^{k},x_{i}^{ws} \right)h ~i k =L A (h i k ,x i w s )
由于BERT中有L = 12 L=12 L =1 2层Transformer,最后,我们得到了用于序列标注任务的第L L L个Transformer 的输出H L H^L H L。
Training and Decoding(训练和解码)
考虑到连续标签之间的相关性,我们使用CRF层对序列进行标注。给定最后一层H L = { h 1 L , h 2 L , . . . , h n L } H^L=\left{ h_{1}^{L},h_{2}^{L},…,h_{n}^{L} \right}H L ={h 1 L ,h 2 L ,…,h n L }的隐藏输出,我们首先计算分数P P P为:
O = W 0 H L + b 0 O=W_0H^L+b_0 O =W 0 H L +b 0
对于标签序列y = { y 1 , y 2 , . . . , y n } y=\left{ y_1,y_2,…,y_n \right}y ={y 1 ,y 2 ,…,y n },我们将其概率定义为:
p ( y ∣ s ) = exp ( ∑ i ( O i , y i + T y i − 1 , y i ) ) ∑ y ~ exp ( ∑ i ( O i , y ~ i + T y ~ i − 1 , y ~ i ) ) p\left( y|s \right) =\frac{\exp \left( \sum_i{\left( O_{i,yi}+T_{yi-1,yi} \right)} \right)}{\sum_{\tilde{y}}{\exp \left( \sum_i{\left( O_{i,\tilde{y}i}+T_{\tilde{y}i-1,\tilde{y}i} \right)} \right)}}p (y ∣s )=∑y ~exp (∑i (O i ,y ~i +T y ~i −1 ,y ~i ))exp (∑i (O i ,y i +T y i −1 ,y i ))
其中T T T是转移分数矩阵,y ~ \tilde{y}y ~表示所有可能的标签序列。
给定N N N个标记数据{ s j , y j } ∣ j = 1 N \left{ s_j,y_j \right} \mid_{j=1}^{N}{s j ,y j }∣j =1 N ,通过最小化语句级负对数似然损失函数来训练模型,如下所示:
L = − ∑ i log ( p ( y ∣ s ) ) L=-\sum_i{\log \left( p\left( y|s \right) \right)}L =−i ∑lo g (p (y ∣s ))
在解码时,利用维特比算法找出得分最高的标签序列。
实验
我们进行了一系列广泛的实验来研究LEBERT的有效性。此外,我们的目标是在相同的设置下对模型级别的融合和BERT级别的融合进行实证比较。使用标准F1-score得分(F1)作为评估指标。
数据集
我们在10个数据集上评价了该方法的三种不同的序列标注任务,这些任务包括中文NER、中文分词和中文词性标注。数据集的统计数据如表1。
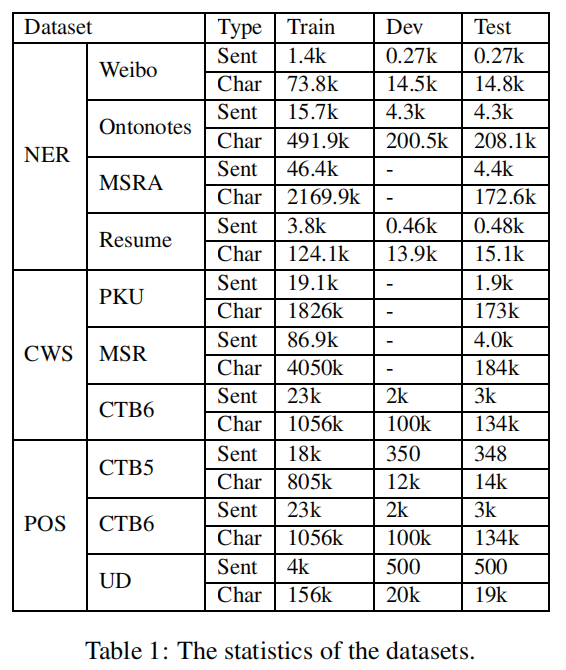
; Chinese NER
我们在四个基准数据集上进行了实验,包括Weibo NER(Peng and Dredze,2015,2016)、OntoNotes(Weischedel et al.,2011)、Resume NER(Zhang and Yang,2018)和MSRA(Levow,2006)。微博是社交媒体领域的数据集,来自新浪微博;而OntoNotes和MSRA数据集则属于新闻领域。简历NER数据集由高管简历组成,Zhang 和Yang(2018)对其进行了标注。
Chinese Word Segmentation
对于中文分词,我们使用了三个基准数据集,即PKU、MSR和CTB6,前两个来自SIGHAN 2005 Bakeoff(Emerson,2005),最后一个来自Xue等人(2005)。对于MSR和PKU,我们跟踪他们的官方培训/测试数据拆分。对于CTB6,我们使用与Yang和Xue(2012)中所述的相同的分割。
Chinese POS Tagging
对于词性标注,使用了三个中国基准数据集,包括来自宾夕法尼亚中文树库(Xue et al., 2005)的CTB5和CTB6和中国通用依赖GSD树库(UD) (Nivre et al., 2016)。CTB数据集为简体中文,UD数据集为繁体中文。继shao et al.(2017)之后,在进行pos标记实验之前,我们首先将UD数据转化为简体中文。此外,UD具有通用的和特定语言的POS标签,我们沿用之前的工作(Shao et al., 2017;Tian et al., 2020a),指的是带有两个标记集的语料库,分别为UD1和UD2。我们在实验中使用了官方的train/dev/test拆分。
实验设置
我们的模型是基于BERT BASE(Devlin等人,2019年)构建的,有12层Transformer,并使用HuggingFace4的Chinese-BERT检查点进行初始化。我们使用了Song等人的200维预训练单词嵌入(2018),它使用定向跳转语法模型对新闻和网页文本进行训练。本文使用的词典D D D是预训练词嵌入的词表。我们在BERT中的第一个和第二个变压器之间应用了Licion Adapter,并在训练过程中对BERT和预先训练的单词嵌入进行了微调。
超参数
我们使用Adam优化器,对于BERT的原始参数,初始学习率为1e-5,对于LEBERT引入的其他参数,初始学习率为1e-4,对于所有数据集的训练,最batch为20。序列的最大长度设置为256,MSRA NER的训练批次大小为20,其他数据集的训练批次大小为4。
Baselines
为了评估所提出的LEBERT算法的有效性,我们在实验中将其与以下方法进行了比较。
- BERT:为了评估所提出的Lebert算法的有效性,我们在实验中将其与以下方法进行了比较。
- BERT+Word:一种强模型级融合基线方法,输入BERT向量和双线性注意力加权词向量的级联,分别使用LSTM和CRF作为融合层和推理层。
- ERNIE:BERT的扩展,使用实体级别的掩码来指导预训练。
- ZEN:通过额外的多层N-gram变压器编码器和预训练,明确地将Ngram信息集成到BERT中。
此外,我们还比较了每个任务的最新模型。
结果
Chinese NER
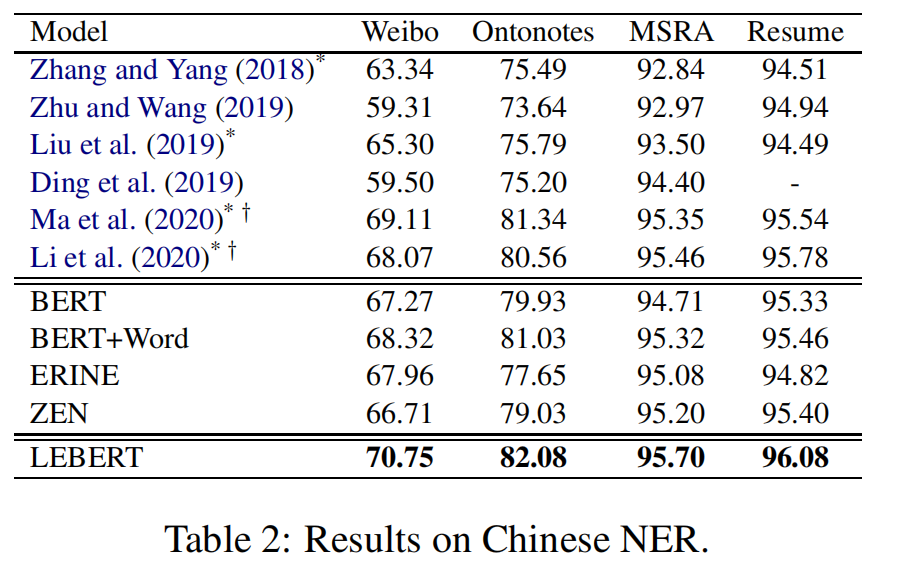
在同一块中是最先进的模型,使用浅层融合层来集成词典信息和BERT。混合模型,包括现有的最先进的模型,BERT+WORD和建议的Lebert,取得了比词典增强模型和BERT基线都更好的性能。这证明了将BERT和词汇特征相结合对中文NER的有效性。与模型级融合模型(Ma等人,2020;Li等人,2020)和BERT+WORD模型相比,我们的BERT级融合模型Lebert在不同领域的所有四个数据集上的F1得分都有所提高,这表明我们的方法在整合Word和BERT方面更有效。结果还表明,我们的基于适应性的方法Lebert,只嵌入一个额外的预训练单词,性能优于这两个词典引导的预训练模型(Ernie和Zen)。这可能是因为Ernie中词汇的隐含整合和禅宗中预先定义的n-gram词汇量的限制限制了效果。
; Chinese Word Segmentation
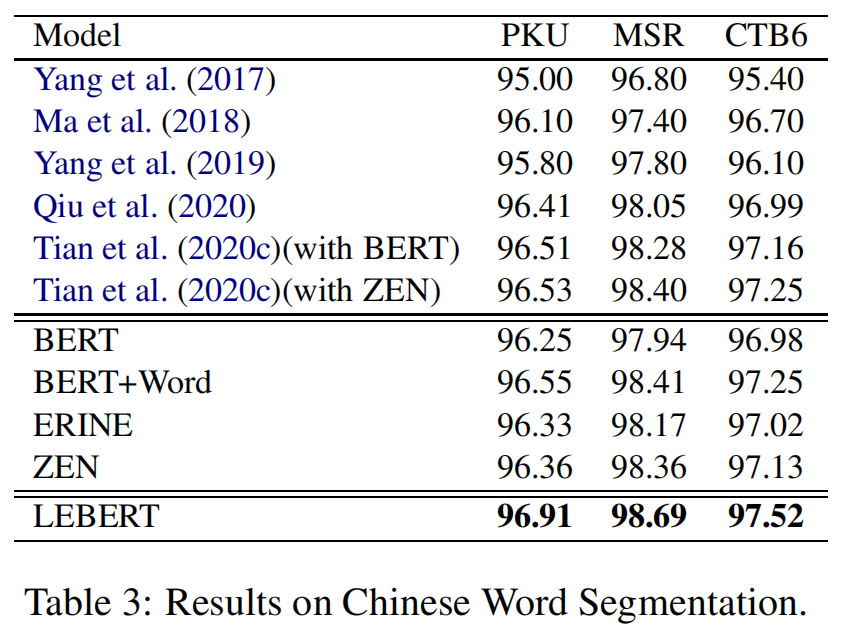
我们在表3中报告了我们模型的F1评分和中文分词的基线方法。(2019)将格子LSTM应用到基于字符的CWS模型中,将单词特征集成到基于字符的CWS模型中。邱等人的研究成果。(2020)研究了多个异构分词标准在单标准中文分词中的优势。田等人。(2020c)设计了一个单词记忆网络,将单词信息融入到基于预训练的CWS模型中,并显示出良好的性能。与这些方法相比,结合词库特征和BERT的模型(BERT+WORD和LEBERT)具有更好的性能。此外,我们提出的Lebert算法比模型级融合基线(BERT+WORD)和词典制导的预训练模型(Ernie和Zen)都有更好的性能,取得了最好的效果。
Chinese POS Tagging

我们在表4中报告了四个汉语词性标注基准的F1得分。最新的模型(田等人,2020a)使用双向注意来联合训练汉语分词和汉语词性标注,以纳入自动分析的知识,如词性标签、句法成分和依存关系。类似于Bert+Word Baseline,Tian et al.。(2020b)使用多通道注意在模型级别将字符-图形特征与BERT集成。如表4所示,结合单词信息和BERT的混合模型((Tian et al.,2020b),BERT+WORD,Lebert)的性能优于BERT基线,表明词典特征可以进一步提高BERT的性能。在这些方法中,Lebert取得了最好的效果,证明了BERT级融合的有效性。与在中文NER和CWS上的结果一致,我们基于BERT适配器的方法优于词汇引导的预训练方法(Ernie和Zen)。
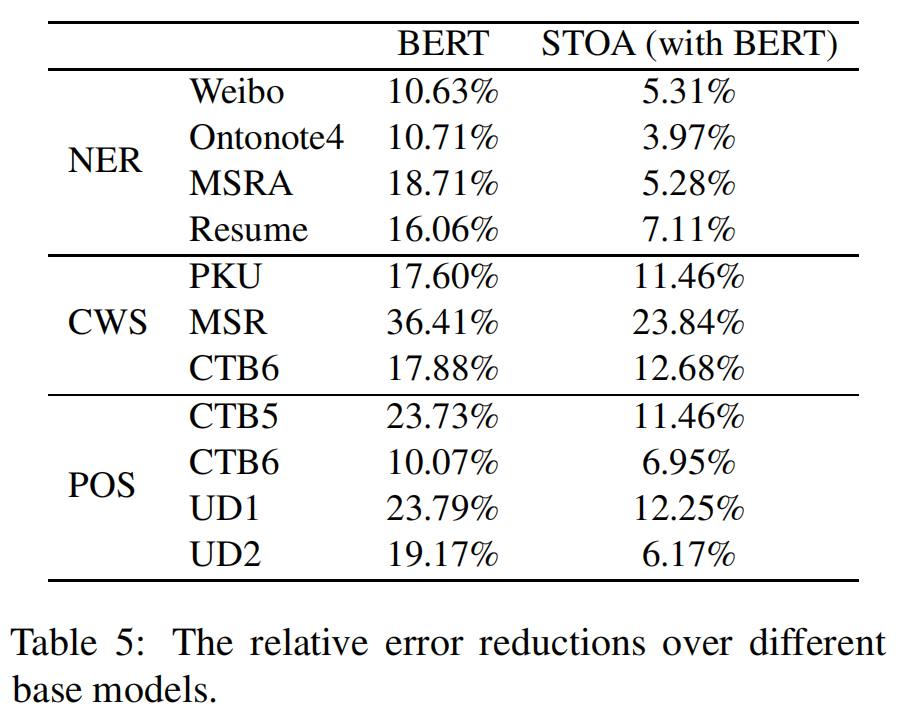
我们提出的模型在所有数据集上都取得了最先进的结果。为了更好地展示我们方法的优势,我们还在表5中总结了BERT基线和基于BERT的最新模型的相对误差降低。结果表明,与基线模型相比,相对误差降低是显著的。
; Model-level Fusion vs. BERT-level Fusion
与模型级融合模型相比,LEBERT直接将词典特征集成到BERT中。我们从Span F1、Type ACC和句子长度三个方面对这两种模型进行了评估,选择BERT+词作为模型级融合基线,因为它在所有数据集上都表现良好。我们还与BERT基准进行了比较,因为LEBERT和BERT+Word都在此基础上进行了改进。
Span F1 & Type Acc.
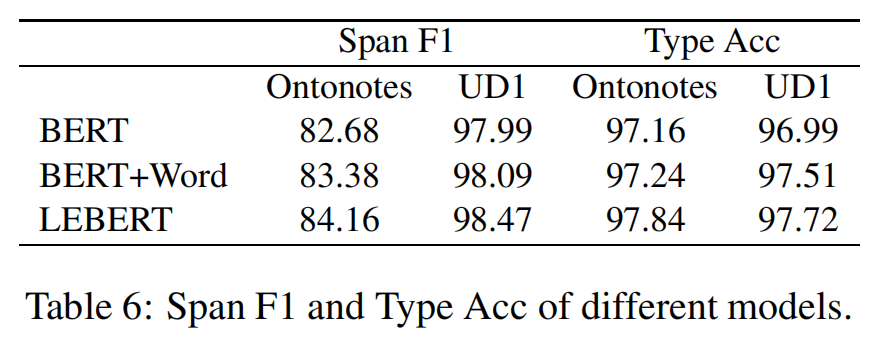
SPAN F1表示NER中的实体或词性标注中的单词的跨度的正确性,而ACC类型表示完全正确的预测与跨度正确的预测的比例。表6显示了三个模型在Ontonotes和UD1数据集上的结果。我们可以发现,在两个数据集上,Bert+Word和Lebert都比Bert在Span F1和Type ACC上表现得更好。结果表明,词典信息对跨区边界检测和跨度分类有一定的贡献。具体而言,Span F1在Ontonotes上的改善幅度大于Acc型,而在UD1上的改善幅度较小。与BERT+WORD相比,Lebert有了更多的改进,证明了通过BERT级融合增强词汇特征的有效性。
; Sentence Length.
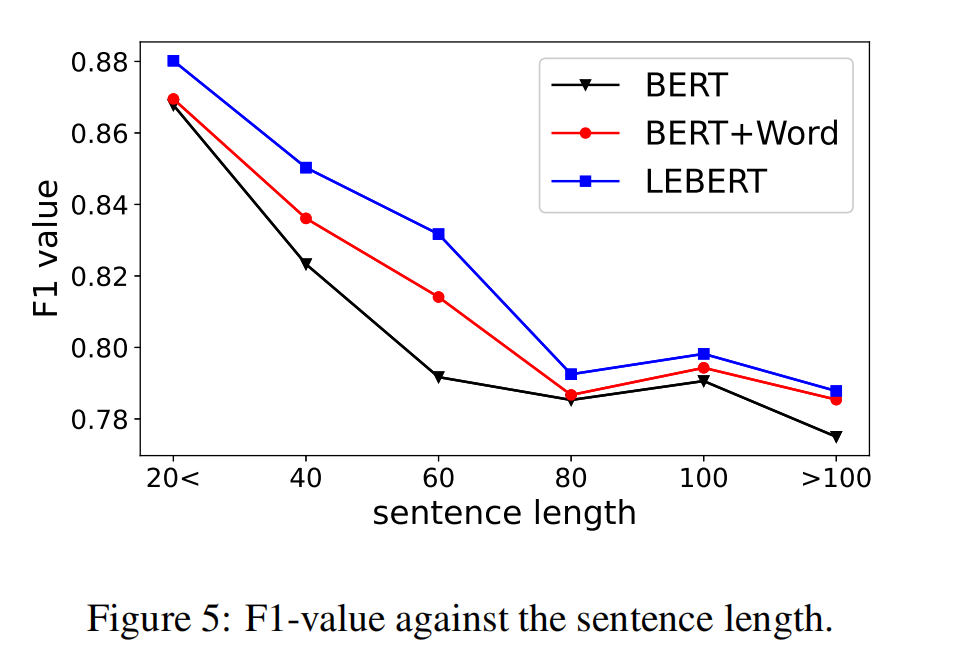
图5显示了Baseline和Lebert on Ontonotes数据集的F1值趋势。所有模型都呈现出相似的性能-长度曲线,随着句长的增加而减小。我们推测,由于复杂的语义,长句更具挑战性。即使是词典增强型模型也可能无法选择正确的单词,因为随着句子变长,匹配词的数量会增加。BERT的F1-得分相对较低,而BERT+WORD由于使用了词汇信息而取得了较好的成绩。与BERT+WORD相比,随着句长的增加,Lebert的表现更好,表现出更强的稳健性,说明词库信息得到了更有效的利用。
Case Study.
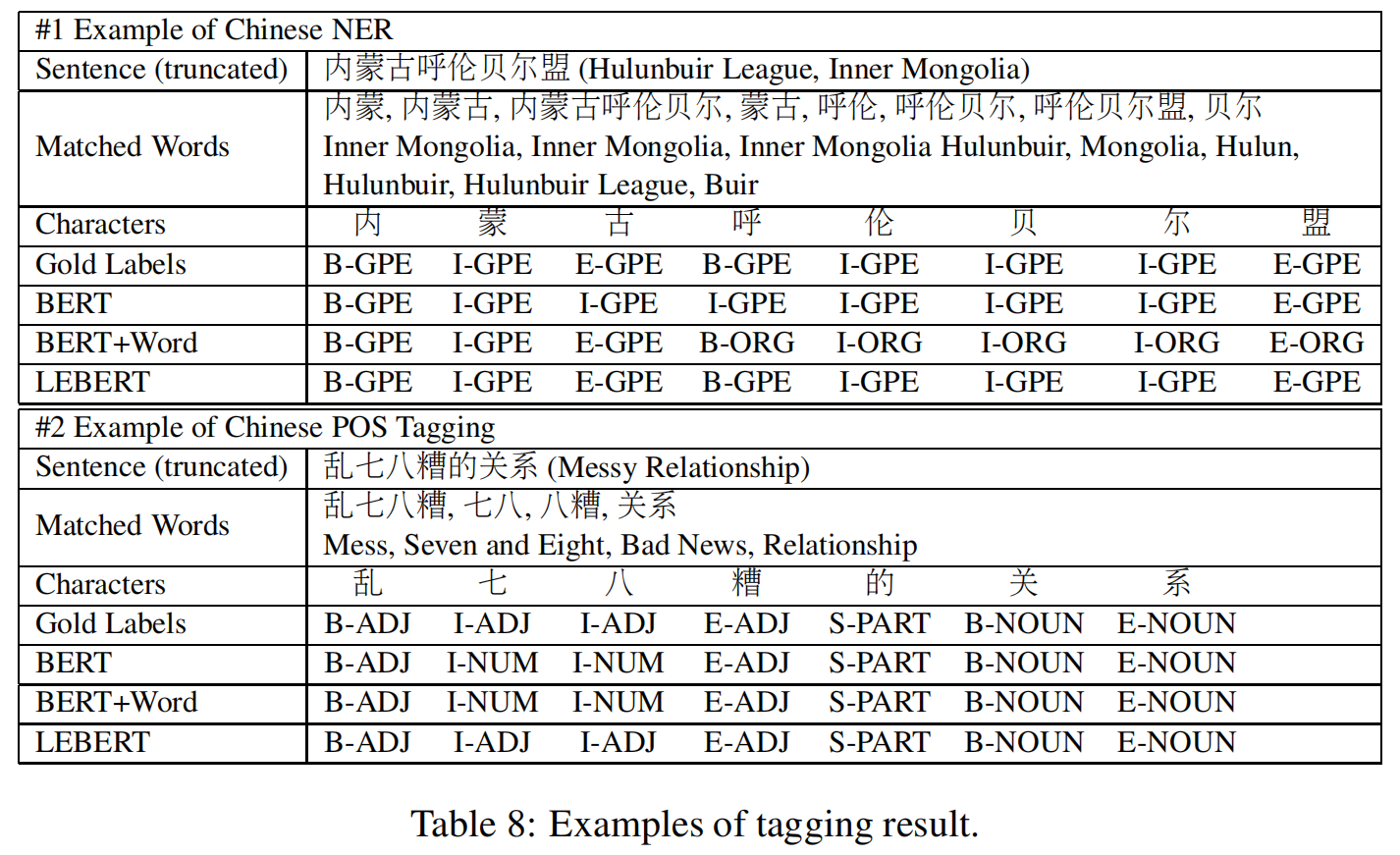
表8分别显示了中文NER和中文词性标注在Ontonotes和UD1数据集上的标注结果。在第一个例子中,Bert不能确定实体边界,但是Bert+Word和Lebert可以正确地分割它。然而,BERT+词模型未能预测出实体”呼伦贝尔盟(呼伦贝尔联盟)”的类型,而勒伯特做出了正确的预测。这很可能是因为较低层的融合有助于捕获由Bert和Licion提供的更复杂的语义。在第二个示例中,三个模型可以找到正确的跨度边界,但是BERT和BERT+WORD都对跨度类型做出了错误的预测。虽然BERT+WORD可以使用单词信息,但它被不相关的单词”七八(Seven And Eight)”所干扰,预测它为NUM。相反,Lebert不仅可以整合词汇特征,还可以选择正确的单词进行预测。
; 讨论
Adaptation at Different Layers.
我们探讨了在Ontonotes数据集上应用词典适配器(LA)在ERT的不同转换器层之间的影响。评估了不同的设置,包括在变压器的一层、多层和所有层之后应用LA。对于一层,在k∈{1,3,6,9,12}层之后应用LA;对于多层,分别使用{1,3},{1,3,6},{1,3,6,9}层。所有层表示在BERT中的每个变形器层之后使用的LA。

结果如表7所示。浅层获得了更好的性能,这可能是因为浅层促进了词典特征和BERT之间更多层次的交互。在ERT的多层上应用LA会损害性能,一个可能的原因是多层上的集成导致过度拟合。
; Tuning BERT or Not.
直观地说,在没有微调的情况下将词汇整合到Bert中可能会更快(Houlsby等人,2019年),但由于词汇特征和Bert(离散表示与神经表示)的不同特征,性能较低。为了评估其影响,我们在Ontonotes和UD1数据集上进行了微调BERT参数和不微调BERT参数的实验。从结果中我们发现,在没有微调BERT的情况下,Ontonotes上的F1分数下降了7.03点(82.08UD75.05),UD1上下降了3.75点(96.06UD92.31),这说明了微调BERT对于我们的词典整合的重要性。
结论
本文提出了一种将词典特征和BERT相结合的中文序列标注新方法,该方法利用词典适配器直接在BERT中的转换器层之间注入词典信息。与模型级融合方法相比,Lebert允许在BERT级深度融合词典特征和BERT表示。大量实验表明,提出的Lebert算法在3个中文序列标注任务的10个数据集上取得了最好的性能。
Original: https://blog.csdn.net/sunshine_10/article/details/118438691
Author: All in .
Title: ACL2021_Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548774/
转载文章受原作者版权保护。转载请注明原作者出处!