

NLP NLU NLG 简介
NLP
1.含义:机器语言和人类语言之间进行沟通的”翻译官”,目的是为了实现人机交流。
2.组成:


3.典型应用:
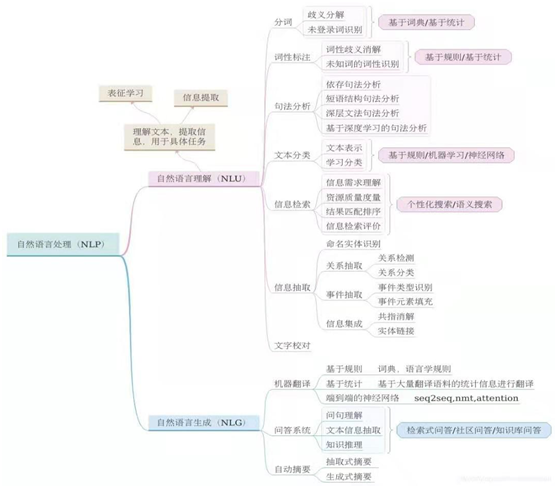
; NLU
1.含义:计算机能够理解自然语言文本的意义
2.难点:
(1)语言的多样性:语言组成没有规律,组合方式多样灵活
(2)语言的歧义性:一词多义
(3)语言中的噪声:存在多字、少字、错字、噪音等问题
(4)语言的知识依赖:依赖于先天经验和知识
(5)语言的上下⽂:不同上下文,语义各不同
3.层次结构:
(1)语音分析:要根据音位规则,从语音流中区分出一个个独立的音素,再根据音位形态规则找出音节及其对应的词素或词。
(2)词法分析:找出词汇的各个词素,从中获得语言学的信息。
(3)句法分析:对句子和短语的结构进行分析,目的是要找出词、短语等的相互关系以及各自在句中的作用。
(4)语义分析:找出词义、结构意义及其结合意义,从而确定语言所表达的真正含义或概念。
(5)语用分析:研究语言所存在的外界环境对语言使用者所产生的影响。
4.技术发展历程:
(1)基于规则的方法 :通过总结规律来判断自然语言的意图,常⻅的⽅法有:CFG、JSGF等。
l 上下文无关文法(CFG):验证字符串是否符合某个规则文法G
(2) 基于统计的方法 :对语言信息进行统计和分析,并从中挖掘出语义特征,常⻅的方法有:SVM、HMM等。
l 隐马尔科夫模型HMM
l 最大熵马尔可夫模型MEMM
l 条件随机场CRF
(3)基于深度学习的⽅法:CNN,RNN,LSTM
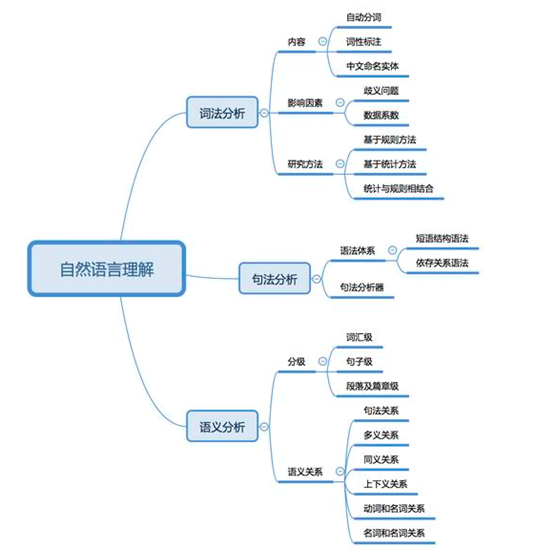
5.知识图谱:
6. 典型应用:机器翻译、机器客服、智能音箱
NLG
1.含义:将非语言格式的数据转换成⼈类可以理解的语言格式
2.模式:
(1)text-to-text:文本到语言的生成
(2)data-to-text:数据到语言的生成
(3)image-to-text:图像到语言的生成
3.方式:
(1)简单的数据合并:自然语言处理的简化形式,将数据转换为文本(通过类似Excel的函数)。
(2)模板化的NLG:这种形式的NLG使用模板驱动模式来显示输出。数据动态地保持更改,并由预定义的业务规则集生成。
(3)高级NLG:这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果以可理解的方式呈现,如一般用基于深度学习的encoder-decoder结构来实现。
4.步骤:
第一步:内容确定 – Content Determination
首先,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于”REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
5.典型应用:
(1)应用目标:能够大规模的产生个性化内容;帮助人类洞察数据,让数据更容易理解;加速内容生产。
(2)自动写新闻(自动定稿),聊天机器人(机器客服),BI(商业智能)的解读和报告生成
(3)论文写作,摘要生成,自动作诗,新闻写作、报告生成,
方法汇总
1.多任务学习:是在多个任务下训练的模型之间共享参数的方法,在神经网络中通过捆绑不同层的权重轻松实现
2.词嵌入:Word2vec有两种不同的实现方法:CBOW和skip-gram。它们在预测目标上有所不同:一个是根据周围的词语预测中心词语,另一个则恰恰相反。在预处理和初始化中具有重要作用。
3.CNN:卷积层只需要在时序维度上移动,卷积操作中每个时间步的状态只依赖于局部上下文
4.RNN:递归神经网络具有树状层结构,网络节点按其连接顺序对输入信息进行递归的人工神经网络,与传统神经网络最大的区别在于RNN每次计算都会将前一词的输出结果送入下一词的隐藏层中一起训练,最后仅仅输出最后一个词的计算结果
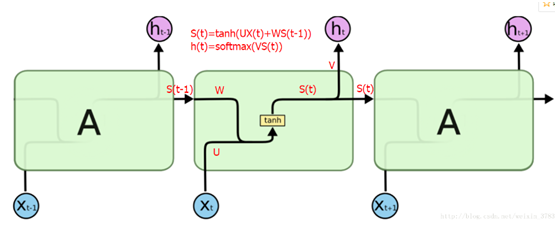
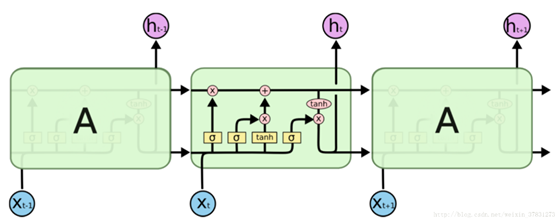
5.LSTM:长短期记忆网络
(1)遗忘门(forget)、输入门(input)、输出门(output)
(2)网络结构:
6.构递归神经网络:
自下而上构建序列的表示, 树中的每个节点是通过子节点的表征计算得到的。
7.编解码格式网络:
8.注意力机制
9.对抗学习:GAN
10.语言预训练模型:预训练模型指的是首先在大规模无监督的语料上进行长时间的无监督或者是自监督的预先训练(pre-training),获得通用的语言建模和表示能力。之后在应用到实际任务上时对模型不需要做大的改动,只需要在原有语言表示模型上增加针对特定任务获得输出结果的输出层,并使用任务语料对模型进行少许训练即可,这一步骤被称作微调(fine tuning)。
11.Transformer:
(1)没有用任何CNN或者RNN的结构
(2)编解码格式网络+跳跃连接
(3)多头注意力机制+全连接前馈网络+residual+layer ormalization+位置编码
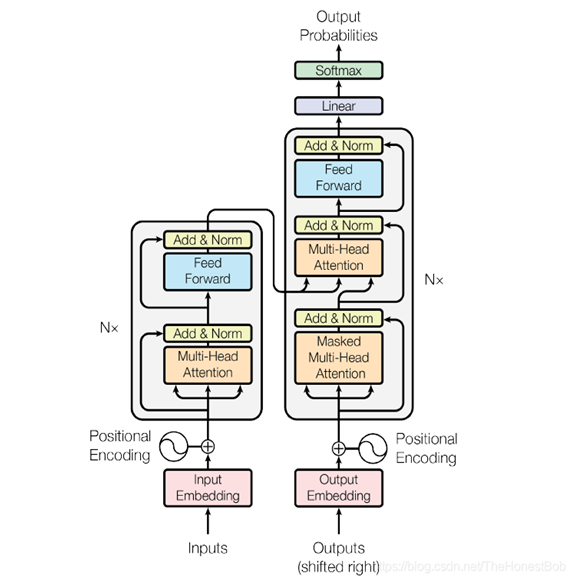
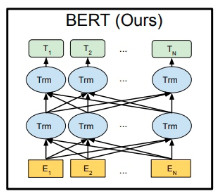
12.BERT
(1)自监督的预训练任务集合:Masked LM和Next SentencePrediction。
(2)以TransformerEncoder为主干网络的双向结构
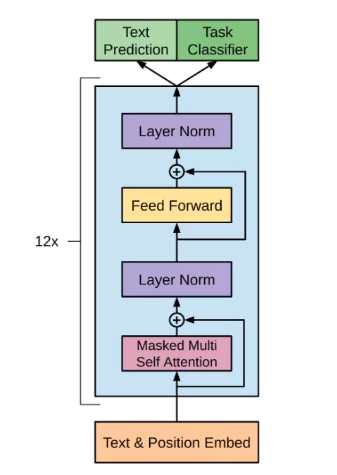
13.GPT-3
(1)1750亿个参数,96层带有128头的attention的单向Transformer结构,自回归语言建模
(2)只需要更少的领域数据,且不需要经过精调就可完成任务
14.XLNet
(1)自回归语言建模:一种使用上下文词来预测下一个词的模型,缺点:它只能使用前向上下文或后向上下文,这意味着它不能同时使用前向和后向上下文
(2)自编码语言:它可以从向前和向后的方向看到上下文,它假设预测(掩蔽)的标记彼此独立
(3) 针对Transformer的缺点引入了2个解决方法:分割循环机制和相对位置编码
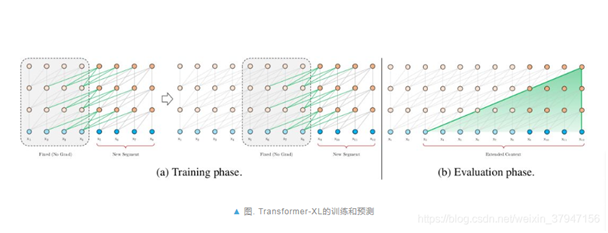
(4)双通道自注意力:计算内容表征通道和语境表征通道 (目的:首先它希望预测自己到底是哪个字符,其次还要能预测后面的字符是哪个)
(5)排列语言建模:随机排列选取预测,泛化能力更强
15.ERNIE
(1)ERNIE在处理中文语料时,通过对预测汉字进行建模,可以学习到更大语义单元的完整语义表示。模型结构主要包括 2个模块,下层模块的文本编码器( T-Encoder)主要负责捕获来自输入标记的基本词汇和句法信息,上层模块的知识编码器( K-Encoder)负责从下层获取的知识信息集成到文本信息中,以便能够将标记和实体的异构信息表示成一个统一的特征空间中。
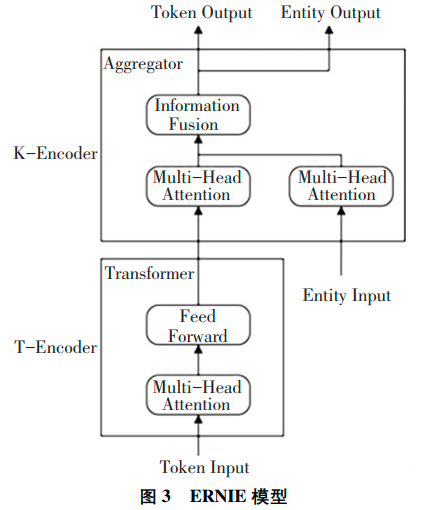
(2)建立海量数据中的实体概念等先验语义知识,学习完整概念的语义表示,即在训练模型时采用遮盖单词的方式通过对词和实体概念等语义单词进行遮盖,使得模型对语义知识单元的 表示更贴近真实世界。此外,ERNIE模型引入多源语料训练,其中包括百科类、新闻资讯类、论坛对话等数据。
; 此外,我自己还制作了一个详细介绍NLP预训练模型的PPT,希望大家批评指正
Original: https://blog.csdn.net/weixin_44517291/article/details/115508909
Author: 我bu
Title: NLP NLU NLG 简介
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/548467/
转载文章受原作者版权保护。转载请注明原作者出处!