

同学你好!本文章于2021年末编写,获得广泛的好评!
故在2022年末对本系列进行填充与更新,欢迎大家订阅最新的专栏,获取基于Pytorch1.10版本的理论代码(2023版)实现 ,
Pytorch深度学习·理论篇(2023版)目录地址为:
以下为2021版原文~~~~


1 NLP发展阶段
深度学习在NLP上有两个阶段:基础的神经网络阶段
1.1 基础神经网络阶段
1.1.1 卷积神经网络
将语言当作图片数据,进行卷积操作。
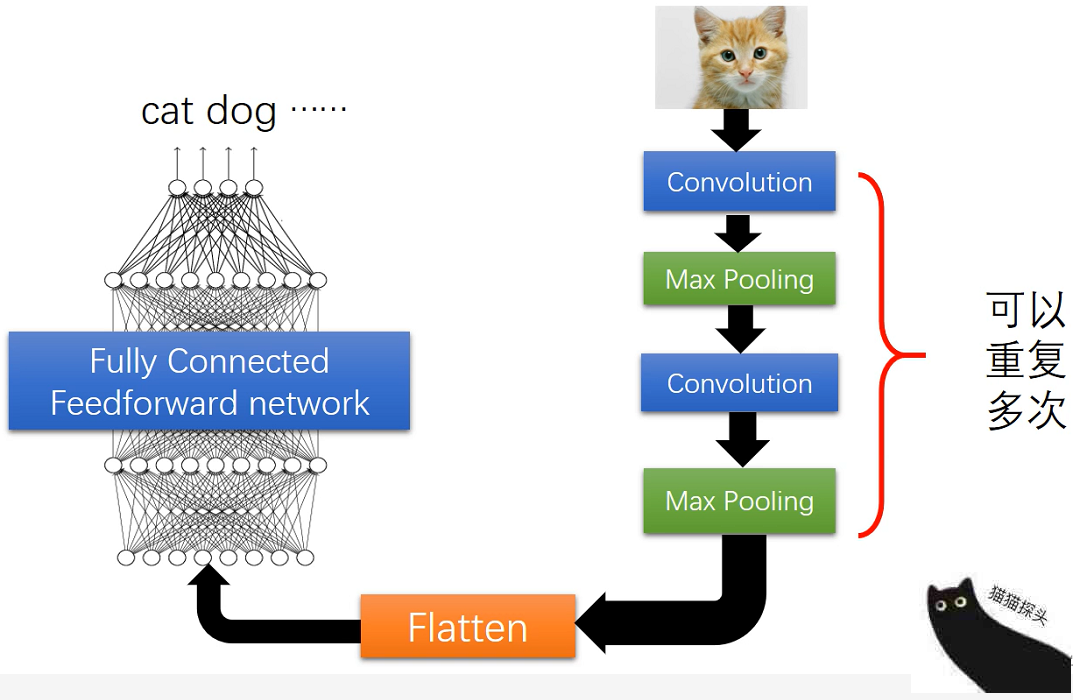
1.1.2 循环神经网络
按照语言文本的顺序,用循环神经网络来学习一段连续文本中的语义。
1.1.3 基于注意力机制的神经网络
是一种类似于卷积思想的网络。它通过矩阵相乘,计输入向量与目的输出之间的相似度,进而完成语义的理解。
1.2 BERTology阶段
通过运用以上3种基础模型,不断地搭建出拟合能力越来越强的模型,直到最终出现了BERT模型。
1.2.1 BERT的发展
BERT模型几乎在各种任务上都优于其他模型, 最终演变出多种BERT的预训练模型 :
- 引入BERT模型中双向上下文信息的广义自回归模型XLNet;
- 改进BERT模型训练方式和目标的RoBERTa和SpanBERT模型;
- 结合多任务和知识蒸馏强化 BERT 模型的MT-DNN模型
1.2.2 关于BERT模型的疑问
试图探究BERT模型的原理及其在某些任务中表现出众的真正原因。BERT模型在其出现之后的一个时段内, 成为NLP任务的主流技术思想。这种思想也称为BERT学。
2 NLP常见的任务
NLP可以细分为自然语言理解(Natural Language Understanding, NLU) 与 自然语言生成(Natural Language Generation,NLG) 两种情况。

2.1 基于文章处理的任务
2.1.1 含义
主要是对文章中的全部文本进行处理,即 文本挖掘。该任务的文章为单位,模型会对文章中的全部文本进行处理,得到该篇文章的语义。当得到语义之后,便可以在模型的输出层,按照具体任务输出相应的结果。
2.1.2 基于文章处理任务的细分
- 序列到类别:如文本分类和情感分析。
- 同步序列到序列:是指为每个输入位置生成输出,如中文分词、命名实体识别和词性标注。
- 异步序列到序列:如机器翻译、自动摘要。
2.2 基于句子处理的任务/序列级别任务
主要包括句子分类任务(如情感分类)、句子推断任务(推断两个句子是否同义)及句子生成任务(如回答问题、图像描述)等。
2.2.1 句子分类任务及相关数据集
句子分类任务常用于评论分类、病句检查等场景,常用的数据集如下:
- SST-2(Stanford Sentiment Treebank):这是一个二分类数据集,目的是判断一个句子(句子来源于人们对一部电影的评价)的情感。
- CoLA(Corpus of Linguistic Acceptability):这是一个二分类数据集,目的是判断一个英文句子的语法是否正确。
2.2.2 句子推断任务及相关数据集
句子推断任务(又称基于句子对的分类任务)的输入是两个成对的句子,其目的是判断两个句子的意思是蕴含、矛盾的,还是中立的。常用在智能问答,智能客服及多轮对话中。常见数据集如下:
- MNLI:这是GLUEDatasets数据集中的一个数据集,是一个大规模的、来源众多的数据集,目的是判断两个句子语义之间的关系。
- QQP(Quora Question Pairs):这是一个二分类数据集,目的是判断两个来自Quora的问题句子在语义上是否是等价的。
- QNLI(Question Natural Language Inference):这也是一个二分类数据集,每个样本包含两个句子(一个是问题,另一个是答案)。正向样本的答案与问题相对应,负向样本则相反。
- STS-B(Semantic Textual Similarity Benchmark):这是一个类似回归问题的数据集,给出一对句子,使用1~5的评分评价两者在语义上的相似程度。
- MRPC(Microsoft Research Paraphrase Corpus)这是一个二分类数据集,句子对来源于对同一条新闻的评论,判断这一对句子在语义上是否相同。
- RTE(Recognizing Textual Entailment):这是一个二分类数据集,类似于MNLI数据集,但是数据量较少。
- SWAG(Situations With Adversarial Generations):这是一个问答数据集,给一个陈述句子和4个备选句子,判断前者与后者中的哪一个最有逻辑的连续性,相当于阅读理解问题。
2.2.3 句子生成任务及数据集
句子生成任务:属于类别(实体对象)到序列任务,如文本生成、回答问题和图像描述。
典型数据集如下:
SQuAD数据集的样本为语句对(两个句子)。其中,第一个句子是一段来自某百科的文本,第二个句子是一个问题(问题的答案包含在第一个句子中)。这样的语句对输入模型后,要求模型输出一个短句作为问题的答案。
SQuAD2.0,它整合了现有的SQuAD数据集中可回答的问题和50000多个由公众编写的难以回答的问题,其中那些难以回答的问题与可回答的问题语义相似。它弥补现有数据集中的不足。现有数据集要么只关注可回答的问题,要么使用容易识别的自动生成的不可回答的问题作为数据集。
为了在SQuAD2.0数据集中表现得更好,模型不仅要在可能的情况下回答问题,还要确定什么时候段落的上下文不支持回答。
2.3基于句子中词的处理任务
基于句子中词的处理任务又叫作token级别任务,常用于完形填空(Cloze)、预测句子中某个位置的单词(或实体词)、对句子中的词性进行标注等。
2.3.1 token级别任务与BERT模型
token级别任务也属于BERT模型预训练的任务之一,即完形填空,根据句子中的上下文token,推测出当前位置应当是什么token。
BERT模型预训练时使用了遮蔽语言模型(Masked Language Model,MLM)。该模型可以直接用于解决token级别任务,即在预训练时,将句子中的部分token用[masked]这个特殊的token进行替换,将部分单词遮掩住。该模型的输出就是预测[masked]对应位置的单词。这种训练的好处是不需要人工标注的数据,只需要通过合适的方法,对现有语料库中的句子进行随机的遮掩即可得到可以用来训练的语料,训练好的模型就可以直接使用。
2.3.2 token级别任务与序列级别任务
在某种情况下,序列级别任务也可以拆分成token级别任务来处理。
SQuAD数据集是一个基于句子处理的生成式数据集。这个数据集的特殊性在于最终的答案包含在样本的内容之中,是有范围的,而且是连续分布在内容之中的。
2.3.3 实体词识别任务及常用模型
实体词识别(Named Entity Recognition,NER)任务也称为实体识别、实体分块或实体提取任务。它是信息提取的一个子任务,旨在定位文本中的命名实体,并将命名实体进行分类,如人员、组织、位置、时间表达式、数量、货币值、百分比等。
本质:对句子中的每个token标注标签,然后判断每个token的类别,可以用于快速评估简历、优化搜索引擎算法、优化推荐系统算法等。
常见的实体词识别模型包括:
- SpaCy模型是一个基于Python的命名实体识别统计系统,它可以将标签分配给连续的令牌组。SpaCy模型提供了一组默认的实体类别,这些类别包括各种命名或数字实体,如公司名称、位置、组织、产品名称等。这些默认的实体类别还可以通过训练的方式进行更新。
- Stanford NER模型是一个命名实体Recognizer,用Java实现。它提供了一个默认的实体类别,如组织、人员和位置等,可支持多种语言。
Original: https://blog.csdn.net/qq_39237205/article/details/124215479
Author: LiBiGo
Title: 【Pytorch神经网络理论篇】 36 NLP中常见的任务+BERT模型+发展阶段+数据集
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/545062/
转载文章受原作者版权保护。转载请注明原作者出处!