

论文题目:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
论文链接:https://arxiv.org/pdf/2207.02696.pdf
YOLOv7
近年来,实时目标检测器仍在针对不同的设备进行开发。例如,YOLOX 和 YOLOR 等方法专注于提高各种 GPU 的推理速度。最近,实时目标检测器的发展集中在高效架构的设计上。另一个主流的实时目标检测器是针对 GPU 开发的,它们大多使用 ResNet、DarkNet 或 DLA 作为主干网络,然后使用 CSPNet 策略来优化架构。YOLOv7 方法的发展方向与当前主流的实时目标检测器不同。除了架构优化之外,YOLOv7 还专注于优化训练过程,重点放在一些优化模块和优化方法上,它们可能会增加训练成本以提高目标检测的准确性,但不会增加推理时间。具体来说,YOLOv7 介绍了一些新发现的问题,并针对这些问题设计了有效的解决方法。 对于模型重参数化,首先用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了重参数化模型。此外,使用动态标签分配策略时,具有多个输出层的模型的训练会产生新的问题,即如何为不同分支的输出分配动态目标,针对这个问题,提出了一种新的标签分配方法,称为从粗到细的引导式标签分配。
相关工作
实时目标检测
目前 SOTA 的实时目标检测器主要基于 YOLO 和 FCOS。这些实时目标检测器通常需要以下特性:(1)更快更强的网络架构; (2) 更有效的特征融合方法; (3) 更准确的检测方法; (4) 更鲁棒的损失函数; (5) 更高效的标签分配方法; (6) 更有效的训练方法。
模型重参数化
模型重参数化技术在推理阶段将多个计算模块合并为一个。模型重参数化技术可以看作是一种集成技术,可以分为两类:模块级集成和模型级集成。模型级别的重参数化有两种常见的做法来获得最终的推理模型。一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重求均值。另一种是对不同迭代次数的模型权重进行加权平均。模块级重参数化是最近比较热门的研究方向。这种方法在训练时将一个模块拆分为多个相同或不同的模块分支,在推理时将多个分支模块整合为一个完全等效的模块。然而,并非所有重参数化模块都可以完美地应用于不同的架构。考虑到这一点,YOLOv7 开发了新的重参数化模块,并为各种架构设计了相关的应用策略。
模型缩放
模型缩放是一种放大或缩小模型并使其适合不同计算设备的方法。模型缩放方法通常使用不同的缩放因子,例如输入图像的分辨率、深度(层数)、宽度(通道数)等,以在网络参数的数量、计算量、推理速度和准确性之间实现良好的平衡。网络架构搜索(NAS)是常用的模型缩放方法之一。 NAS 可以自动从搜索空间中搜索到合适的缩放因子。NAS 的缺点是需要非常昂贵的计算来完成对模型缩放因子的搜索。YOLOv7 的作者观察到,所有基于连接的模型,例如 DenseNet、VoVNet,都会在缩放模型深度的同时改变某些层的输入宽度。
网络结构
扩展的聚合网络
在大多数设计高效架构的文献中,考虑因素主要为参数的数量、计算量和计算密度。作者提出的E-ELAN 使用扩张、打乱等操作来实现在不破坏原有梯度路径的情况下不断增强网络的学习能力。在架构方面,E-ELAN 只改变了计算块的架构,策略是使用组卷积来扩展卷积的通道数。首先对计算层的所有卷积应用相同的组参数和通道乘数。然后,每个卷积计算出的特征图会根据设置的组参数g 被打乱成 g 个组,再将它们连接在一起。因此,每组特征图的通道数将与原始架构中的通道数相同。
基于拼接模型的模型缩放策略
模型缩放的主要目的是调整模型的一些属性,生成不同大小的模型,以满足不同推理速度的需求。作者发现,对基于拼接 (concat) 模型的深度放大或缩小时,模型的宽度会随之增大或减小,如图 1 中的 (a) 和 (b) 所示。
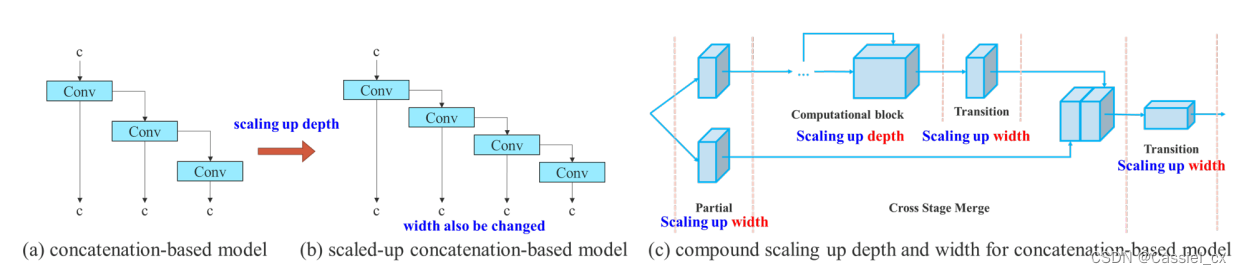

图 1 基于拼接的模型缩放
因此,必须为基于拼接的模型提出相应的复合模型缩放方法。当缩放一个计算块的深度因子时,还必须计算该块的输出通道的变化。然后对过渡层进行等量变化的宽度因子缩放,结果如图 1 (c) 所示。
计划重参数化卷积
在提出的计划重参数化模型中,作者发现一个带有残差或拼接连接的层,该层中的 RepConv 不应该有恒等连接。 在这些情况下,它可以被不包含恒等连接的 RepConvN 替换。
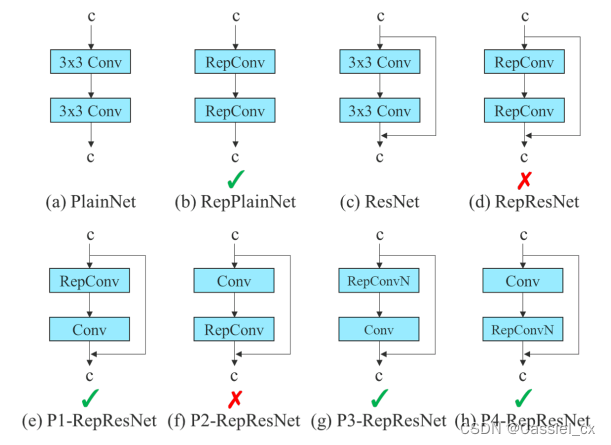
图 2 计划重参数化模型
由粗到细的监督信息
深度监督是一种常用于训练深度网络的技术。它的主要概念是在网络的中间层添加额外的辅助头。 即使对于像 ResNet 和 DenseNet 这样通常收敛良好的网络,深度监督仍然可以显着提高模型在许多任务上的性能。图 3 (a) 和 (b) 分别显示了没有和有深度监督的目标检测器结构。在此,将负责最终输出的 head 称为 lead head,用于辅助训练的 head 称为 auxiliary head。
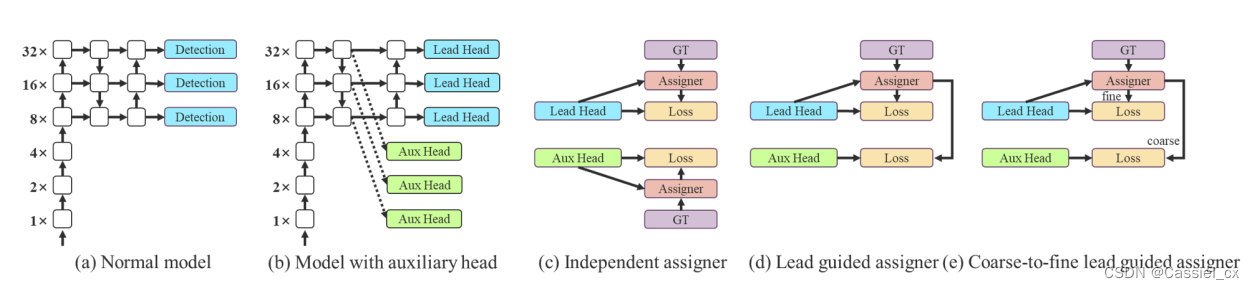
图 3 辅助头和主导头的标签分配
在以前的深度网络训练中,标签分配通常根据给定的规则直接将 GT 生成标签。然而,近年来,以目标检测为例,研究人员往往会利用网络预测输出的质量以及 GT 并使用一些计算和优化方法来生成可靠的标签。目前最流行的方法如图 3 (c) 所示,就是将辅助头和主导头分离开来,然后利用各自的预测结果和 GT 进行标签分配。YOLOv7 提出了一种新的标签分配方法,该方法使用主导头预测的结果作为指导来生成由粗到细的分层标签,这些标签分别用于辅助头和主导头地学习。YOLOv7 提出的两种深度监督标签分配策略分别如图 3 (d) 和 (e) 所示。
图 3 (d) 主要根据主导头的预测结果和 GT 计算并生成标签。这样做的原因是因为主导头具有较强的学习能力,所以由它生成的标签应该更能代表源数据和目标之间的分布和相关性。此外,还可以将这种学习视为一种广义残差学习。通过这种方式进行学习,主导头能更关注残差信息。
图 3 (e) 也使用了主导头的预测结果以及 GT 来生成标签。然而,这个过程生成了粗标签和细标签,其中细标签用于监督主导头,而粗标签则监督辅助头。在辅助头的训练中,通过放宽正样本分配过程的约束 (比如,假设主导头为每个 GT 分配 5 个正样本,而辅助头则分配 10 个正样本;主导头中对前 10 个最大 IOU 值求和取整,而辅助头则求前 20 个),将更多的点视为正样本。这样做的原因是辅助头的学习能力不如主导头强,为了避免丢失需要学习的信息,作者重点优化辅助头的召回率。
正负样本分配策略
YOLOv7 的正负样本分配策略为 YOLOv5 与 YOLOX 样本分配策略的结合体,步骤如下:
(1)将 GT 与 anchors 进行比较,如果它们的宽高比在一定范围内,则将 GT 与该层特征图中的anchors 匹配。随后将像素点均分为四小块,计算 GT 中心点处于哪个小块,将最接近该小块的两个像素点上的 anchors 也视为候选正样本;
(2)计算候选正样本与 GT 之间的 IOU,取前 K 个最大 IOU 的值并求和取整,这个整数 N 表示与该 GT 匹配的正样本个数;
(3)计算每个候选正样本的损失 (包括回归损失和分类损失,类似于 YOLOX 的 SimOTA) ,从候选正样本中选取前 N 个损失最小的样本为最终的正样本。
训练中用到的 tricks
(1)直接将 batch normalization layer 连接到 convolutional layer,这样做的目的是在推理阶段将批归一化的均值和方差整合到卷积层的偏置和权重中。
(2)YOLOR 中的隐式知识可以在推理阶段通过预计算简化为向量,该向量可以与前一个或后一个卷积层的偏置和权重相结合。
(3)指数移动平均 (EMA) 模型:EMA 是一种在 mean teacher 中使用的技术。
这些 tricks 会在附录中详细介绍 (目前还没有附录)。
实验
与 SOTA 目标检测方法的性能对比如图 4 所示
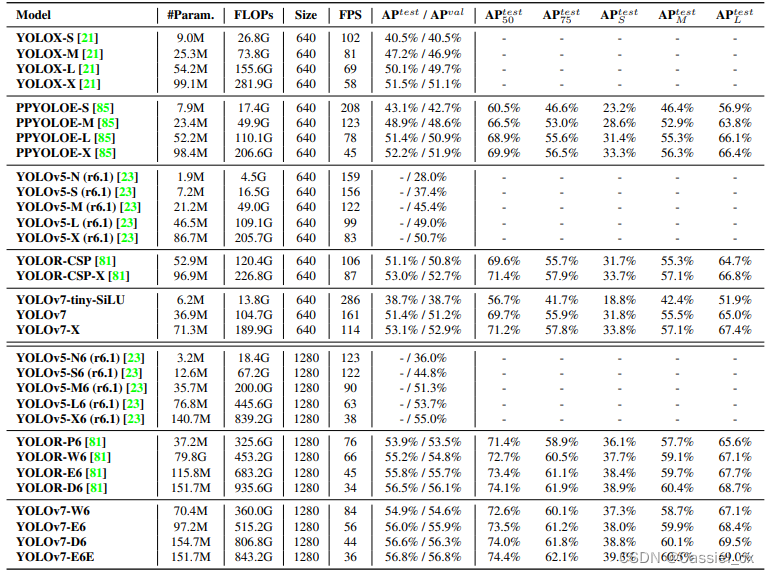
图 4 性能对比
模型缩放策略和重参数化的消融实验结果分别如图 5 和 6 所示
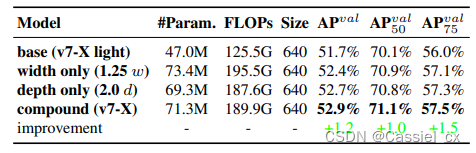
图 5 模型缩放消融实验
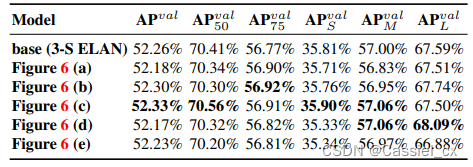
图 6 模型重参数化消融实验
图 6 中的 a、b、c、d、e 代表不同的重参数化位置,位置如图 7 所示。
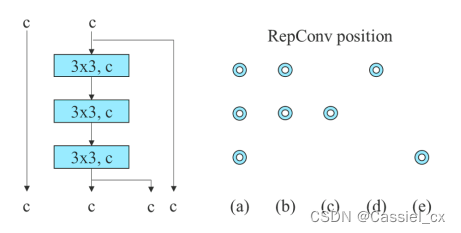
图 7 模型重参数化的位置
补充
FCOS采样策略
(1)首先把GT 内的像素点设为正样本点,并求出正样本点 (x,y) 到GT 四条边的距离,如图 8 所示;

图 8
(2)进一步筛选正样本点,
则把这些点视为负样本点。
FoveaBox 采样策略
(1)由于目标边界框附近的点远离目标的中心,且与背景像素更为接近,如果将其设为正样本点,会对模型的训练造成困难。因此作者使用了一个简单的变换,通过GT 得到目标中心在特征图中对应的位置,然后通过参数来调节目标所在边界框的宽和高,将其缩小一点,把收缩后的边界框内部的点作为正样本点,如图 9 所示;

图 9
(2)给每层特征设置一个相应的目标尺度范围,若某个 GT 不在该尺度范围内,则把在该 GT 以及相应的正样本点删除。
ATSS 采样策略
(1)对于FPN 输出的每层特征图,计算每个anchor 的中心点和GT 中心点的L2 距离,选取前K 个距离最小的anchor 为候选正样本;
(2)计算每个候选正样本和GT 之间的IoU ,并求这组IoU 的均值和方差;
(3)根据均值和方差,设置选取正样本的阈值:
;
(4)从候选正样本中选择 IOU 大于阈值且中心点在GT 内的anchor 作为最终用于训练的正样本。
伪代码如图 10 所示。

图 10
参考
Original: https://blog.csdn.net/qq_38964360/article/details/125962359
Author: Cassiel_cx
Title: 目标检测算法 YOLOv7 学习笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/629566/
转载文章受原作者版权保护。转载请注明原作者出处!