

中文NER1 之 simplify the usage of Lexicon in Chinese NER
ACL-simplify the usage of Lexicon in Chinese NER
近期有个项目跟提取地址实体有关,所以系统性的把ner相关研究重新review了一遍,顺便记录下笔,方便以后查询。
这篇论文下载https://arxiv.org/abs/1908.05969
这篇论文的启发是,利用 Lexicon词汇信息去提升NER准确率, Lattice-LSTM(2018)是一个很好的例子。 该模型在中文NER benchmark表现好,但是计算效率比较低。这篇论文,就是受此启发,需要去加速。实现的方法,综述为:合并词汇信息到向量表示中,从而避免引入复杂的序列结构来表征词汇信息。工作聚焦在改变字符表征层,在四个banchmark中文NER上,试验结果都表现很好。
中文NER难的问题
NER是识别person location product orgnization实体词,在英文中这些特殊实体词都是自然的分割,比如大写或者空格。NER的任务是对文本中每个字符进行标注,所以它是一个序列标注问题。
在中文书写的规范中,是没有英文那种先天特殊词分割书写的优势,导致中文NER任务的难度增加。处理这个问题,一种通用的实践方法是先分词,再把词信息引入到序列标注任务。但是分词引入的错误,会影响下游序列标注任务的正确率。
比如:
南京市/长江大桥。
分词成:南京/市长/江大桥
这种分词会导致NER,很难把 南京市识别为location实体与 长江大桥识别为location实体。相反,很可能把 南京识别成location, 江大桥识别为person。
由于分词准确性不太理想问题,导致很多中文ner在实际使用场景都偏向于使用 字而非 词。但是词信息非常重要,2015和2018都有尝试去引入词信息到模型。为方式分词错的问题,最早的做法是把所有的分词情况都加入到模型,让模型去判断选那种分词。这种模型是2015年的基于LSTM-CRF的模型。结果证明Lattice-LSTM表现很好。缺点有:1.慢,2.这种结构很难转移到其他模型比如CNN或者Transformer上去。
这篇文章提出了
- 一种加速方法
- 一种编码lexicon词汇的方法
通用的NER结构
第一层,输入层(如 char+bichar 2018)
第二层,序列模型层,去获取字符之前的关系(如 CNN / LSTM / Trnasformer)
第三层,推理层 (如 CRF 2001)
中文NER的Lattice-LSTM
目标:合并字符与词汇作为输入
首先,利用lexicon matching在输入文本上,换句话说就是分词才用匹配的方式。获得了词后,会增加一个从字符ci 到 字符cj的有向边(i < j) 。ci为输入字符串中的字符,允许一个字符连接了多个字符(包含同一个字符的词有多个时)。采用这种方式过后,模型的输入由句子序列就变成了图。去实现这种结构,需要修改LSTM的内部结构,对应为:修改输入、 h state、c memorryCell。在更新阶段,输入包含: 当前的字、 上一层的h state、 上一层的c 和 对应的词。h和c都是数组。
这种设计中的不足:
- 在memory更新阶段需要额外的去增加s、 h、 c
- 设计的函数很难并行计算
本论文的方法
重新定义论文的要解决的问题(目标):
- 模型能够保留所有字可能的词
- 模型能够使用预训练词embedding
用 Softword technique来构建分词,并且给每个字符有多个标签。
比如
句子s={c1,c2,c3,c4,c5}, 其中{c1,c2,c3,c4}和{c3,c4}是词。
句子转换成 segs(s) = {{B},{M},{B,M},{E},{O}} BMESO标签。
这里segs(s)1={B}表示至少一个有一个以c1开头的词
segs(s)3={B,M}表示至少有一个 以字符c3开头的词 或者 以字符c3出现在词中间的词
ExSoftword,每个字符有一个5维度的类别表示{B,M,E,S,O}。
通过分析,ExSoftword有两个缺点。
- 它不能支持预训练的word embeddings。
- 尽管它能够包催所有可能的词,但是仍然丢失了一些信息。
句子 s = {c1,c2,c3,c4} 中 {c1,c2,c3} 与 {c2,c3,c4}是词
sges(s)={ {B}, {B,M}, {M,E}, {E} }
这种形式不能,反推或者还原,或者恢复 S就包含 {c1,c2,c3} 与 {c2,c3,c4}词。因为它同样也可以解释成,包含词{c1,c2,c3,c4} 与词{c2,c3}。这种方式,存在无法恢复原始的分词的问题。
改进版本
论文中提出,要保留每个字符可能的词的类别和字的分词。
改进的方法:每个字符分配四种类别 BMES。如果一个词是空的,则以NONE字符表示。
例子如下:
s={c1,c2,c3,c4,c5}中词为{c1,c2},{c1,c2,c3},{c2,c3,c4},{c2,c3,c4,c5}
对与c2, 表示成
B(c2)={{c2,c3,c4},{c2,c3,c4,c5}},
M(c2)={{c1,c2,c3}},
E(c2)={{c1,c2}},
S(c2)={NONE}
从网上找到,一个具体具体示例
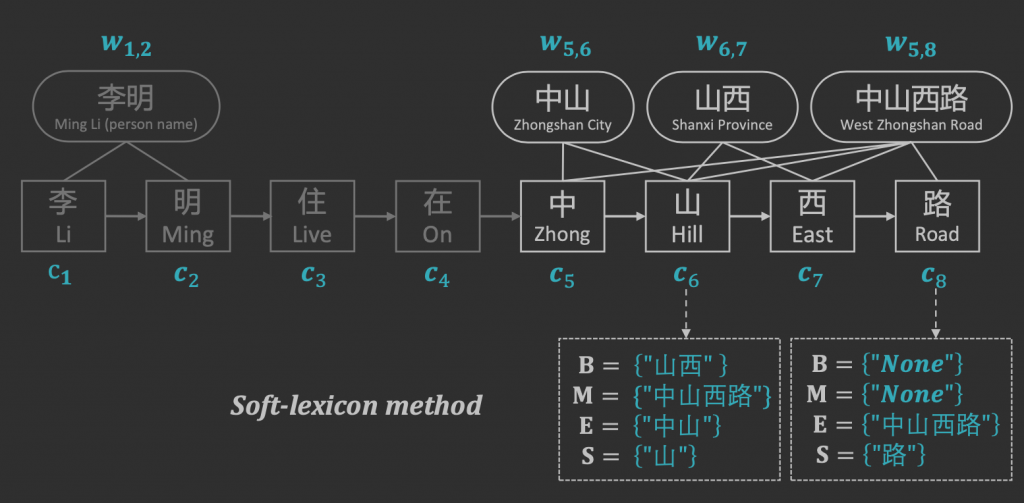

这种方式后,就满足论文的两点目标:能使用pre-trained word embedding 和 能覆盖字符的所有词。
具体input输入生成过程:
把每个字符的四种词集合,压缩进一个固定维度的向量。为了尽可能保留原始信息,这里采用concate拼接四套词的表征,然后把它加到字符表征中去。
其中,单字符的四个词集合中的每个集合,也需要映射到一个固定维度向量。使用的方法:mean-pooling与加权求和。前者效果差,后者效果好。
加权的权值是根据词的频率计算,其中一点要求:当两个词中字符有重叠时,频率不增加,比如 南京 与 南京市 。 当计算 南京市长江大桥 的词频率时,南京的词频就不增加,因为 南京 与 南京市 重叠。这样做的好处是,可以避免 _南京_比 _南京市_频率高。
Original: https://blog.csdn.net/weixin_49379140/article/details/119295504
Author: weixin_49379140
Title: 中文NER1 之 simplify the usage of Lexicon in Chinese NER
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544988/
转载文章受原作者版权保护。转载请注明原作者出处!