

背景介绍
提到label smoothing(标签平滑),首先介绍一下什么是hard label和soft label.
简单来说,hard label就是非1即0,不存在既可能是A也可能是B的情况,soft label则不同,它并不要求所有的”精力”全部倾向一个,允许模棱两可的状态,比如这幅画有40%的概率是猫, 60%的概率是狗。
什么时候会用到
标签平滑在机器学习或者深度学习中可以看作是一种正则化的技巧。它能提高分类任务中模型的泛化性能和准确率,缓解数据分布不平衡的问题。
为什么说能提高模型的泛化性能和准确率呢,我们需要从公式角度出发理解:
对于hard label的情况,softmax之后输出的结果为:




可以看出,如果要想损失的loss为0,那么极限条件就是让正样本的输出值为1,负样本的输出值为0,而要想达到负样本的概率为0,则要求模型输出的logits值为负无穷,而正样本的输出值为常数。这种做法的弊端显而易见:
(1)当数据样本中有信息标注错误时,造成的后果就是一错再错,泛化能力特别差。
(2)一般模型中最后的输出值一般都是有界的,并且由于模型中会加入一些正则化的手段等,不可能 ,很难更新到理想的效果,在同等训练epoch条件下。
label smooth是在《Rethinking the inception architecture for computer vision》里面提出来的。可以设定超参数对label进行soft。



这里的负样本的softmax后的值为a,正负样本之间的差距只要达到
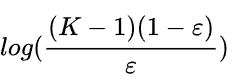
就可以认为达到理想的值,loss为0,相比hard label的无穷大的界限,这种方法的界限是有界的,更容易让模型学习到,同时由于存在其他信息,会使模型的泛化能力更加好。
所以,在损失函数为交叉熵的情况下,如果我们使用label-smooth编码,错误类的logit不会要求是负无穷。且错误类和正确类的logit值有一定大小误差的情况下,loss就会很小很小。
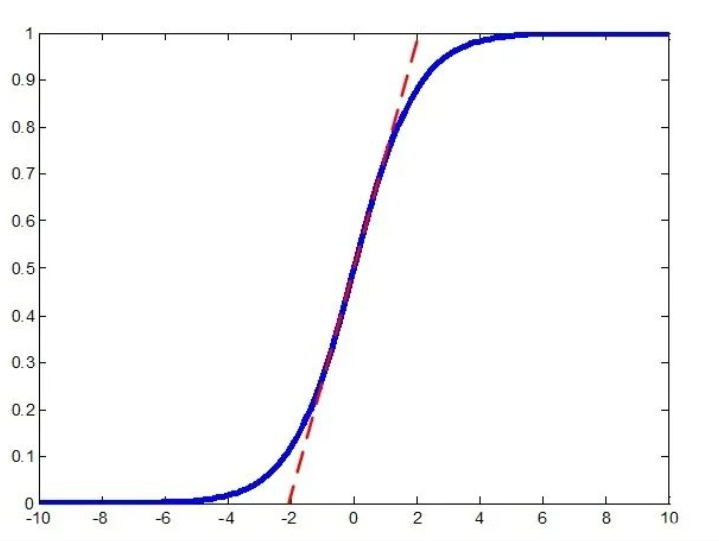
同时,可以看一下这张图,概率值达到一定值后,曲线变的越来越平缓,再优化很难更新。
综上,标签平滑可以产生相对较好的校准网络,从而更好的去泛化网络,最终用于对未知的数据进行预测。
【参考】
https://zhuanlan.zhihu.com/p/343807710
Original: https://blog.csdn.net/amf12345/article/details/123999241
Author: 星辰浩宇
Title: 关于label smoothing的理解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544978/
转载文章受原作者版权保护。转载请注明原作者出处!