

分类和序列标注
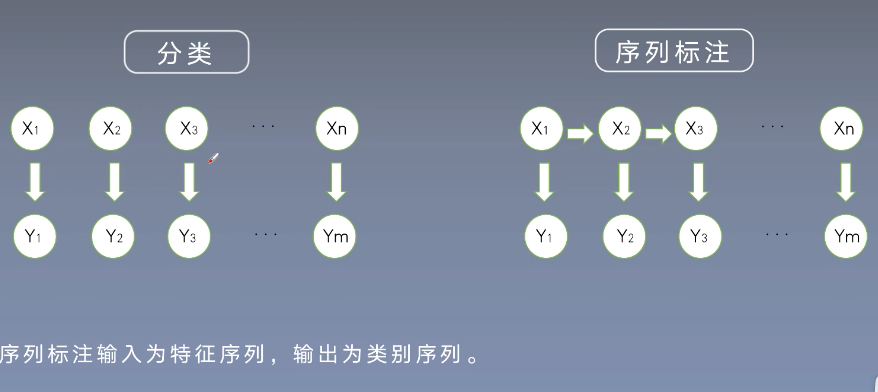

区别在于,序列标注针对的问题是一个序列,每个样本会有前后的关系。
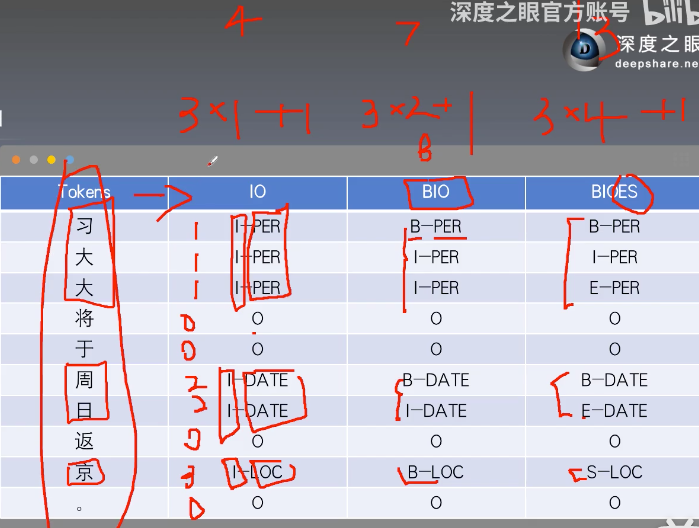
三种标注方式:IO BIO BIOES
序列标记:词性标记(POS)、分块和命名实体识别(NER)
BiLSTM可以综合利用过去和未来的特征
CRF可以利用句子的特征
BiLSTM-CRF模型效果好,鲁棒性强,对词向量依赖不强
CRF可以带来更高的标签准确率,因为CRF可以带来标签的依赖关系,如果没有CRF,则标签之间是相互独立的。
CRF损失函数与维特比解码
CRF的标签可以互相依赖,所有标签跟整个输入都是相关的。
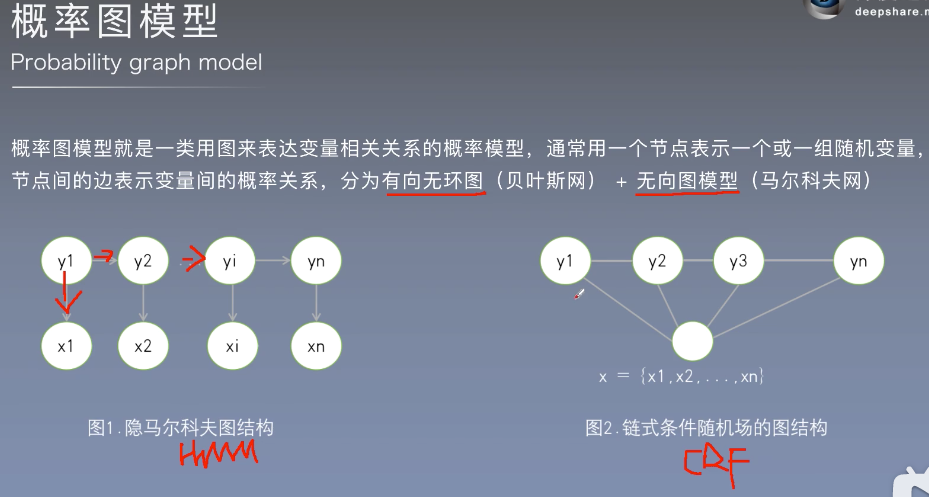
隐马尔可夫模型是一个生成模型(有方向的)
马尔可夫模型可以通过过去的状态推断未来的状态,如一阶马尔可夫模型,通过今天的天气预测明天的天气。
隐马尔可夫模型含有一些无法观测的状态,需要借助观测来推断这些状态。(比如我看不到天气预报,但我能通过雪糕的销量来推测温度的变化) y 温度状态 x 雪糕销量。此外,隐状态之间也是有关系的,比如在梅雨季节,某一天下雨,第二天下雨的可能性也很高。
BIO的是一个不可观测的隐状态,而HMM模型描述的是由这些隐状态序列生成可观测状态的过程。
HMM:齐次马尔可夫假设(转移概率只依赖于之前的状态)、状态独立假设(发射概率只依赖于当前的状态值)。
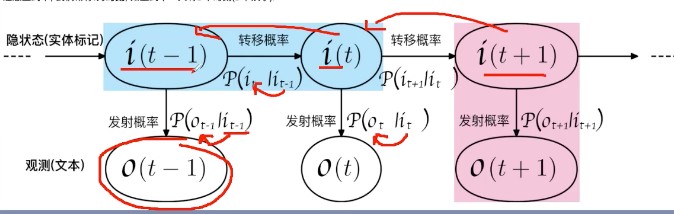
初始隐状态概率、转移概率、发射概率(由隐状态推测观测状态)
HMM的三个基本问题:
(1)概率计算问题,已知模型和观测序列,计算该模型下观测序列出现的概率
(2)学习问题,已知观测序列,估计模型的参数。包括监督学习:极大似然估计(已知状态序列),非监督学习:EM算法(不知状态序列)
(3)预测问题,解码问题,已知模型参数和观测序列,求最有可能对应的状态序列。
MEMMs与HMM的区别,HEMMs中Y是由X决定的,CRF中Y和X是无方向的,是由输入序列预测输出序列的判别模型。
Yi跟所有X有关,Yi跟Yi-1,Yi+1有关
特征函数:取值为1或0.符合这一特征时取值为1,不符合时取值为0.
转移特征 tk 定义在边上的特征函数,依赖于当前位置i和前一位置i-1,权重lambda_k
状态特征sl定义在节点上的特征函数,依赖于当前位置i,权重为miu_l


将特征转化为概率

HMM和CRF的区别,CRF的表达能力和泛化能力更强
CRF可以依赖于全局的X,HMM由于观测独立假设,只能依赖于局部的X
CRF可以有任意权重值(可构造任意特征函数),HMM的概率值必须满足某种特定的约束(比如累加和为1)

在NER中,CRF的表现能力强于BiLSTM,可以考虑到全局的X,和标签间的依赖。

embedding后加入drop out 的作用:
因为embedding的嵌入深度,每一个深度都相当于是一个特征,比如书写特征之类的,使用dropout放弃使用一些特征,使得一些本来对本模型无用的特征可以舍掉。
另一方面,dropout最基本的作用,防止过拟合。
用BiLSTM提取文本特征后,得到了一个P矩阵
将完整的隐状态序列(特征)接入线性层,映射到k维(标签数),从而得到自动提取的句子特征,记作P矩阵
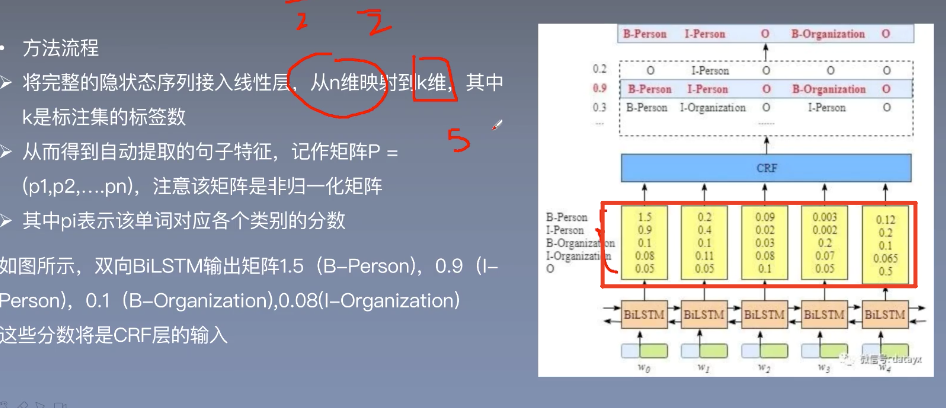
为什么要加CRF? 划重点
可以加强标签的依赖,考虑全局的X信息
CRF的引入:
CRF天然就可以带来这些约束,即学习到句子的前后依赖,加入一些约束来保证最终预测结果有效。

引入方式:
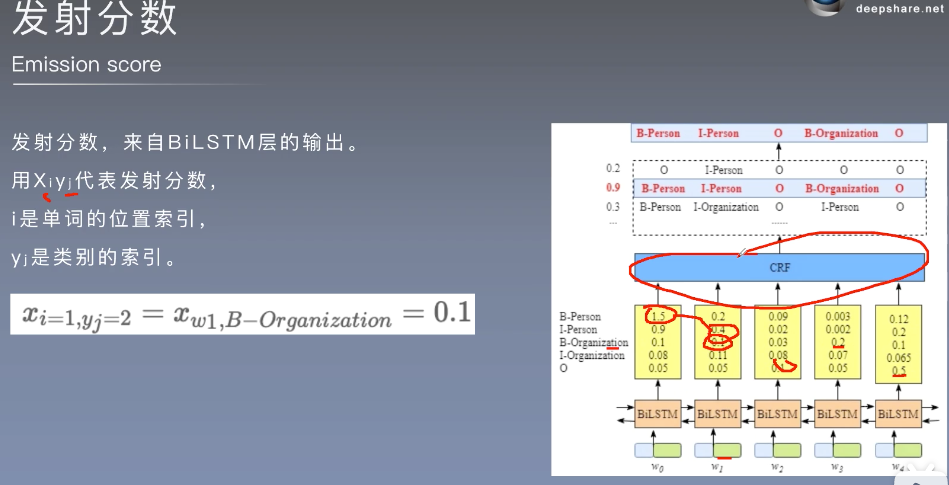
转移分数,来自CRF层可学习到的转移矩阵。转移矩阵是BiLSTM-CRF的一个参数。可随机初始化转移矩阵的分数,然后在训练中更新。
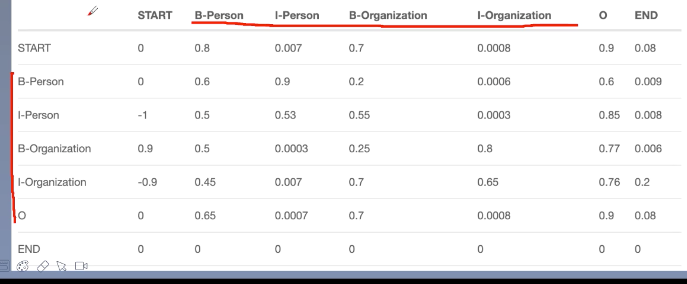
注:还有START和END
最终结果的计算:

路径分数=发射分数+转移分数
发射分数来自于BiLSTM的输出

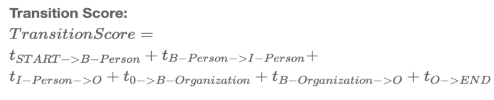
从所有可能的路径中选择最有可能的路径作为最优路径,如何寻找最优路径,以及loss?
总结:发射分数由BiLSTM提取特征得到,转移分数由CRF提取标签的信息得到
CRF损失函数与维特比解码
深度学习需要定义损失函数,用它来进行反向传播
维特比算法,学习到模型的参数之后,定义一个新的样本,根据发射分数和转移分数,得到最优路径。
一种用来选择最优路径的动态规划算法,从开始状态后每走一步,记录达到该状态所有路径的最大概率值,最后以最大值为基准继续向后推进。最后再从结尾回溯最大概率,也就是最有可能的最优路径。

真实路径 = 转移分数+发射分数 的最大值,难点在于所有路径分数
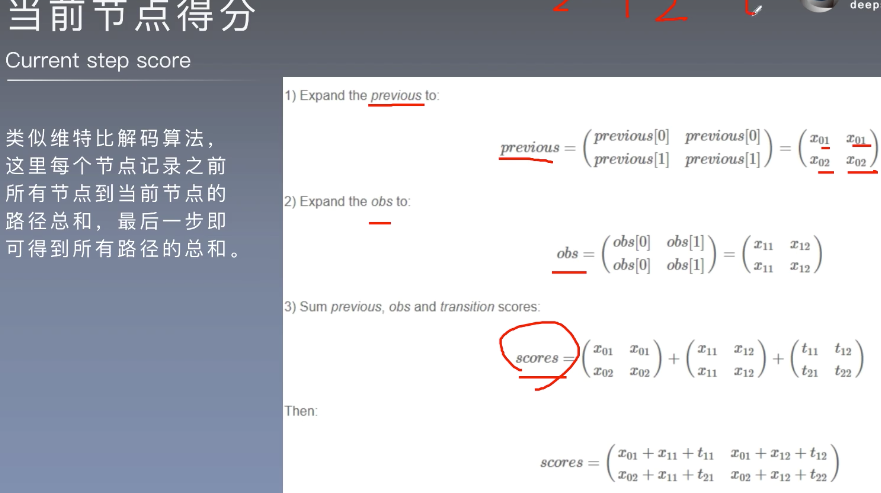
维特比解码算法:
1)previous 发射
2)obs 发射
3)scores 发射+转移
每个节点记录之前所有节点到当前节点的路径总和,最后一步即可得到所有路径的总和。
总结:
NER任务的损失函数: 真实路径/所有路径
真实路径由转移概率+发射概率决定,转移概率由CRF计算,发射概率由BiLSTM计算
所有路径由维特比算法确定。
Original: https://blog.csdn.net/qq_42920313/article/details/120508308
Author: The Crooked Man
Title: BiLSTM-CRF(B站上的学习笔记)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/544503/
转载文章受原作者版权保护。转载请注明原作者出处!