

目录
- 1. 概述
- 2. 相关工作
* - 2.1 表示学习技术
- 2.2 3D形状补全
- 3. DeepSDF
- 4. Auto-decoder
* - 4.1 训练阶段
- 4.2 推理阶段
- 5. 实验与应用
* - 5.1 表示已知的三维形状
- 5.2 表示未知的三维形状
- 5.3 形状补全
-
概述
在广义的三维重建领域,我们需要根据输入的物体的残缺部分来还原整个三维物体,这也牵扯到了我们该如何表示这个物体(点云、网格、体素),以及如何渲染。本文提出了一种名为DeepSDF的方法,在SDF函数能够表示物体的基础上,用神经网络来拟合这个SDF函数,从而实现用神经网络隐式的表示这个物体,并且由于神经网络的万能拟合性质,原则上来说能够表示任意连续的、任意复杂形状的物体。但是仅仅用一个DeepSDF表示单一的物体还是不够的,因为我们的目标肯定是得让DeepSDF能够表示一类三维物体以便于更方便的应用,因此本文在DeepSDF表示单个物体的基础上引入了latent code,提出了一种名为Auto-decoder的架构,能够实现重建某一类物体的任务。
- 相关工作
2.1 表示学习技术
计算机需要处理的数据具体形式五花八门,如果我们能够将数据给编码成latent code就能够方便地进行数据表示了,并且如果我们的方法处理得当,可以通过找到latent code满足的分布,去生成一个新的同类的数据(比如GAN和VAE),或者说改变latent code某个地方来改变其所对应数据的某个属性(比如styleGAN的各种应用),因此该领域的研究相当重要的。
- GAN:假设给我的数据集满足某种分布,那么GAN的作用便是将正态分布去映射到这个数据集的分布,这样我就能通过在正态分布中取样来生成不在数据集中的新的数据了
- Auto-encoders:将数据先经过编码器编码成latent code,然后将其解码得到对应的原始数据,一旦这个编码器和解码器训练好之后,就可以抛掉编码器,随便去找一个满足latent code的分布的数据,经过解码器后,也能实现生成一个新的、数据集中不存在的数据的功能。只不过这个latent code的分布确实不太好确定,因此有了VAE方法,目的是为了让这个分布和正态分布建立联系(关于VAE与GAN的区别网络上有很多资料,这里不再赘述)
- optimizing latent vectors:(关于这种方法我写了一篇针对文章《Optimizing the Latent Space of Generative Networks》ICML 2018 的分析)这种方法应用在本文的基本原理是,我只需要一个解码器,在刚开始训练的时候,我把随机生成的(当然是正态分布)latent code和初始化的解码器都给丢入optimizer(一般我们训练神经网络都是把网络的参数丢入optimizer实现参数更新,根本不会去考虑将数据的输入丢入optimizer,因为没啥意义),然后前向传播得到一个解码后的数据,这个解码后的数据和训练数据肯定不一样,所以二者做loss,反向传播,同时优化latent code和解码器。在训练完之后,我们知道每个训练数据在训练过程中都肯定得到了属于它本身的latent code,但是这个不重要,重要的是我们通过训练得到了一个解码器。但是有了解码器之后,我们如何去应用呢?这种方法其实并不是像GAN一样用在数据自动生成,而是用在数据的补全与推理:给我一个残缺的数据,我还是先正态分布去取一个latent code,这个时候我只把latent code给丢进optimizer了,解码器固定参数不动了,再反向传播,迭代若干次得到属于这个残缺数据的latent code,得到之后,再经过解码器,得到完整的数据(没错, 这种方法在训练完网络,去具体应用的时候也进行了反向传播与迭代,虽然看起来有点反直觉与常理,但是因为只有latent code丢进了optimizer,与训练时相比,迭代的速度会快很多)这种思路是本文所提出的方法——Auto-decoder(注意不是前面说的Auto-encoder)的出发点。
2.2 3D形状补全
类似于2D的计算机视觉里面的图像修复工作,3D形状补全工作的目的是基于一些部分的或离散的输入,推理出这个3D物体全部的形状。比如说给我几个离散的SDF函数的值,我把整个连续的SDF函数给搞出来,给我任意的输入我都能得到应有的数值。之前传统的方式是使用径向基函数(RBF),或者将其看做是一个泊松问题,但是这些方式是以数学理论为依托的,虽然合理性得到了保证,但是缺点就是一次仅仅只能建模一个单一的3D物体。最近随着深度学习的发展,这种3D补全工作开始以数据为驱动,常用的模型便是编码-解码架构,这个结构训练好之后,存储了所训练数据集的先验知识,不管输入的离散数据有多少,具体的值是多少,它们肯定是代表着某一个具体的待恢复的三维形状的,那么网络就能先把这个给编码成特征向量,然后再解码,得到这个恢复的三维形状。
无疑这种方法的编码-解码网络训练好之后,可以实现多个形状物体的建模任务,而非仅仅局限于某一个单一的物体。
-
DeepSDF
-
首先,我们可以用SDF(Signed Distance Function)这样一个函数来隐式地表示一个三维物体,输入是空间中点的三维坐标,输出是这个点离我们想表示的物体表面的最近距离,如果在外部就是正,内部就是负。显然只要SDF找的好,从理论上来说,我们就能够简单粗暴地表示 任意复杂且连续的物体,这也是物体的隐式表示方式与用点云、体素、网格等表示方式相比最大的好处。公式如下:
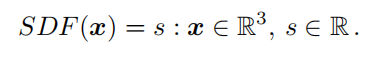

其中x为三维的采样点,s为一维的带正负的数值,假定真的有这样一个完美的SDF函数,那么我们就能用图形学中现成的Marching Cubes方法将其转换成网格数据,或者直接用raycasting方法直接渲染,在这里不作详细讨论。 - 现在假定我们有几个离散的SDF函数的输入与输出,我们想要通过某种方式得到这个完整的SDF函数,最终就能实现根据这几个离散的采样点来重建整个三维物体了,这也是本文的根本目的。本文提出的DeepSDF思想便是,用神经网络当做SDF函数的拟合器,训练完(或者说拟合完)之后,输入大量自定义的三维空间采样点,再提取出所有值为0的点组成面,就能够重建整个三维物体了。因为神经网络是万能函数拟合器,所以说这种方法可以表示任意精度的,连续的三维物体,只不过是得取决于你的采样点数量与神经网络的层数罢了
- 很显然,基于上面的思想我们很自然地想到这种结构:
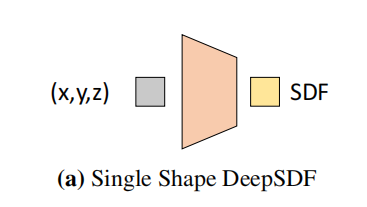
在这里,神经网络的作用 不是去实现某种功能,而是去 表示物体或场景本身,因此也会导致后续的各种训练上和我们正常认知的神经网络训练方式有些许的区别(关于这两者区别建议看一下我仔细梳理总结的《用神经网络表示物体或场景与用神经网络完成任务的区别与联系》) - 这样就万事大吉了吗?并没有,因为如果用这种方法,并不是数据驱动的,而更像是一种数学的方法,我们每次进行重建的时候都得重新训练一个神经网络得到表示这个物体的专属SDF,比如给我一个轿车的若干采样点,我给训练出来了,你要是再给我一个卡车的采样点,我还得重新训练,虽说这样我们根本不需要数据集,但是缺点显而易见:我是希望在神经网络中引入对三维数据集的一些先验来辅助拟合,以便于更好地进行三维重建的,比如你就给我8个采样点,分别代表正方体的8个顶点,如果不引入数据集(如汽车数据集)的先验的话,最终拟合出来的东西肯定就是一个正方体(或者是个球体)之类的东西,而不是像个汽车的样子。
- 因此,本文提出了下面的架构:
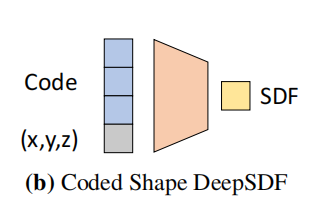
假定数据集中的某个数据被编码成latent code进行表示,这样我将这个latent code和三维坐标同时丢入神经网络查询得到sdf值,其实就能够得到某个具体的三维物体的SDF函数表示了
这里的思想其实比较微妙,在二维的representation learning领域,直接用一个latent code就能表示某个具体的数据了(比如图像),在三维的representation learning领域,其实也是可以将latent code通过一个解码器直接得到一个物体的体素,网格,点云表示的,但是如果这个物体是用神经网络来进行表示的呢?总不能使用解码器得到一个神经网络吧,因此就采用了如上图所示的这种方式,结合写的《用神经网络表示物体或场景与用神经网络完成任务的区别与联系》这篇文章,其实可以作一个小小的升华:latent code是数据集中个体的表示,(x,y,z)是个体的部分的表示,二者结合,丢入神经网络,实现了从集体到个体,再从个体到局部的预测,在这里,这个解码器实现的不再是简单的场景表示功能,而是一种更加”智能化”的场景表示功能
- 有了这个架构,自然而然地,我们可以用VAE或GAN的思想来进行训练,可是这里没有,而是采用了前面提到的optimizing latent vectors的思想,整个训练架构也称之为”Auto-decoder”
; 4. Auto-decoder
传统的编码-解码架构有什么问题呢,作者认为虽然在训练的时候我使用的编码-解码网络,但是在具体应用推理的时候,我是抛弃掉编码器的,因为给我一个三维物体的局部,我可以固定解码器的参数,根据反向传播,去优化中间的latent code,得到合适的latent code之后,再前向传播得到整个三维物体整体的样子。采用这样一种方式的话我们得花时间精力去设计一个合适的编码器,并且也有点浪费计算资源(好吧,作者说的理由很牵强,结合分析的《Optimizing the Latent Space of Generative Networks》ICML 2018 这篇文章里做的GLO与VAE的对比实验,我个人的一个想法是:使用编码-解码架构会限制住latent code的范围,而如果采用下面说的思想的话,latent code在优化的过程中本身就没有了范围约束,因此能够更好地去表示训练集的特征),本文的这种auto-decoder的架构,也是首次将相关方法应用在3D的学习相关领域
4.1 训练阶段

如上面公式所示,假定有N个训练集的物体,每一个物体共有K个采样点,我们对每一个物体都先给高斯初始化一个z,然后根据采样点的loss去同时优化z和解码器网络结构,这样训练完之后,肯定对于训练集中的每一个物体,我们都找到了一个适合描述它的latent code,并且在这个过程中也得到了一个合适的能够将latent code变为具体物体的解码器
; 4.2 推理阶段
在具体应用时,是还得需要训练的!如下公式所示:
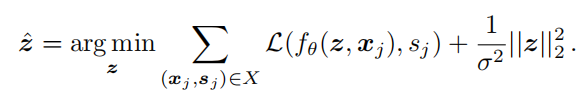
因为在具体应用的时候,我们能拿到手的只有某个不知名物体的若干个采样点,所以我们要做的任务得分两步:
- 根据手上的若干采样点,得到这个要推理物体的latent code
- 有了latent code之后,就相当于有了这个物体的抽象表示,然后就能把latent code和自己想要的(x,y,z)一起丢入解码器进行查询了
注意上面的公式,第一步仅仅是优化z,这个时候解码器的参数是固定不动的,因此收敛速度相比训练时会快一些,这种方式与编码-解码架构相比,并不要求训练数据和推理数据有着一定的相似性,这也是auto-decoder架构的一个好处
- 实验与应用
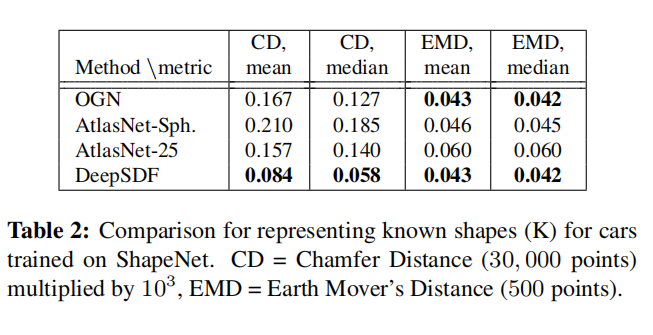
5.1 表示已知的三维形状
在训练阶段完成训练之后,我能够得到某个训练集物体的latent code了,那么我直接根据它就能获得这个物体的点云了,为了衡量我得到的点云和真实物体的点云的差异,使用Chamfer Distance距离(CD距离)与Earth Mover’s Distance距离(EMD距离)
- CD距离:
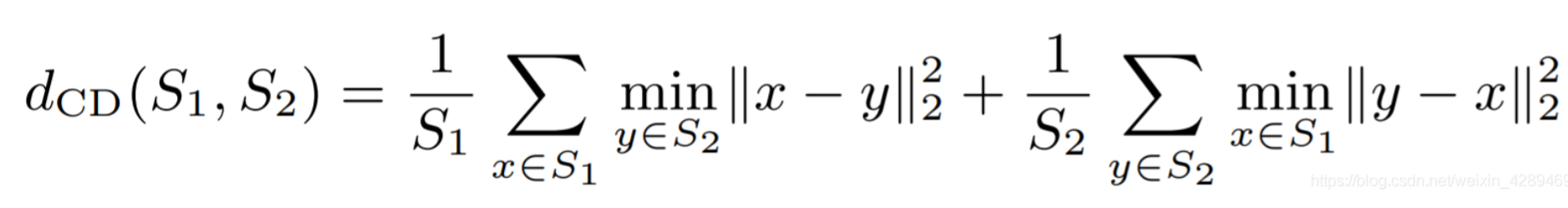
显然CD距离越小,两个点云的分布就越接近 - EMD距离:
将两个点云分布中的一片点云当做土堆,另一片当做洞,那么EMD距离便是衡量将土堆填满这些洞的最小工作量,这是一个线性规划问题,计算出的最终结果越小,意味着这两片点云越相近
与其它方案的比较如图所示:
; 5.2 表示未知的三维形状
当然对于未知的三维形状,我们因为在训练时已经得到了一些先验知识,所以肯能也是能够圆满完成任务的,如图所示:

左边的物体是ground truth,右边的物体是重建结果,可以看出效果是非常平滑的,但是最右边依然有失效的结果,推测是缺乏相关的训练数据导致先验缺失,或是推理阶段收敛z的时候出了点问题
5.3 形状补全
因为输入的是离散的未知物体局部的采样点,因此我们可以做到从局部推断整体:
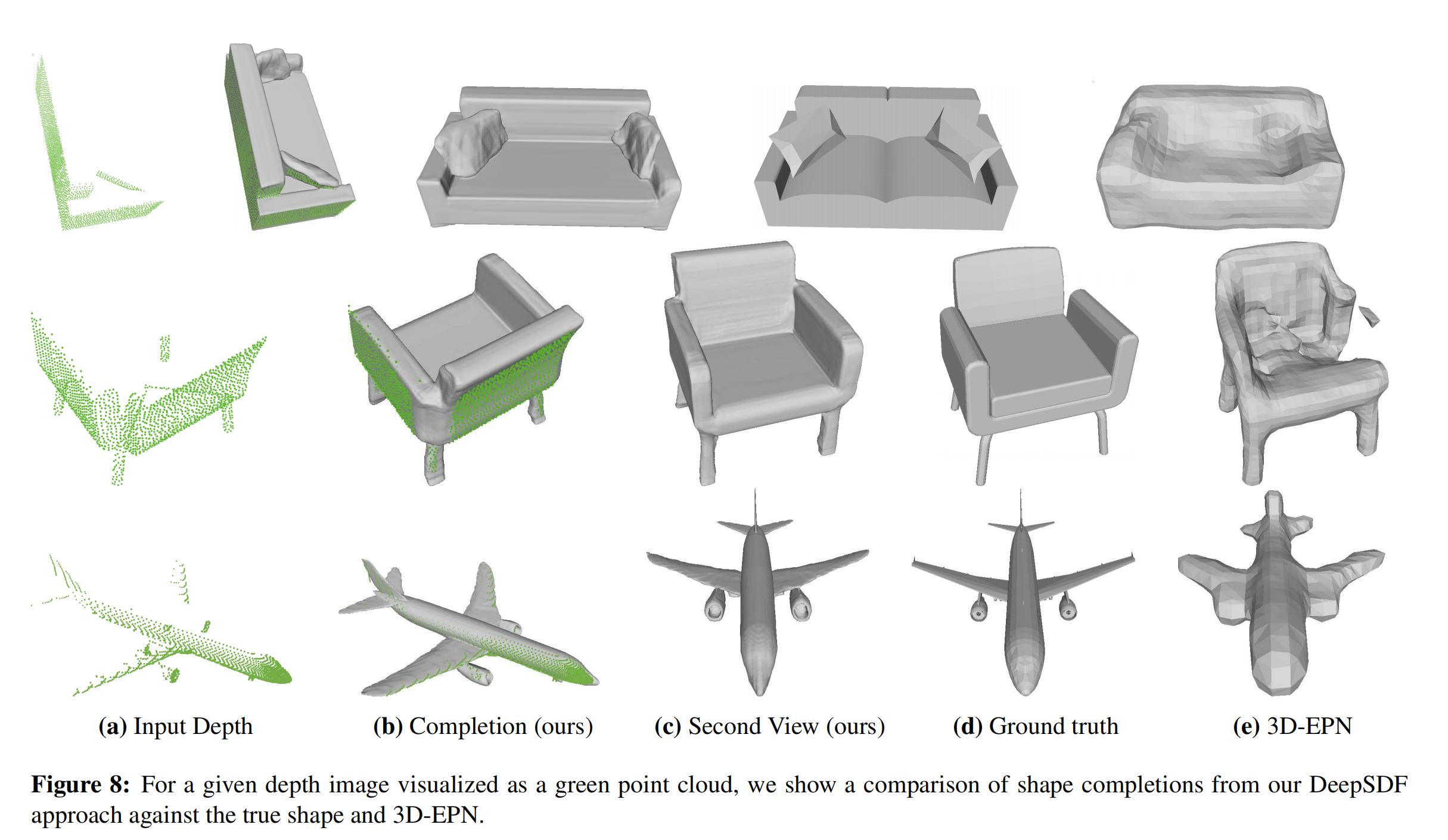
我们根据三维物体的部分的深度图采样,首先转换成SDF采样点,然后再进行三维重建,得到了上图所示结果,可以看出效果是不错的
; 5.4 隐空间插值
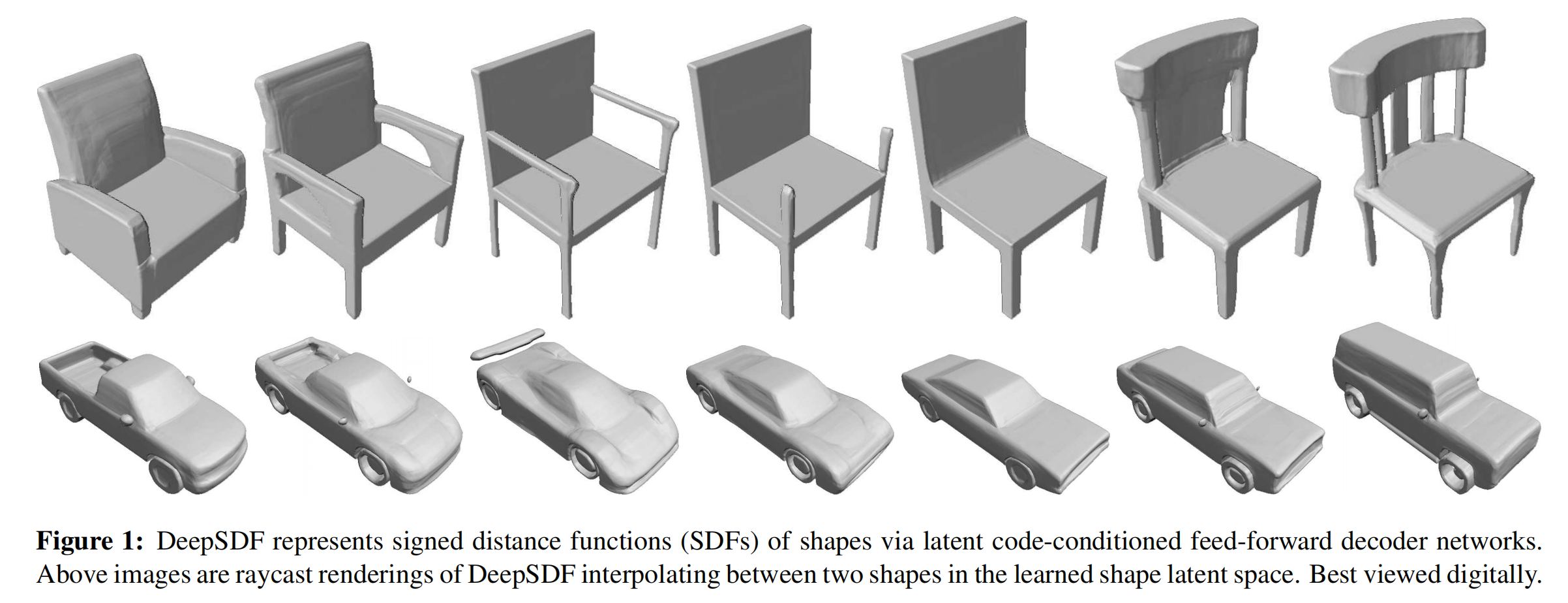
对于两个不同形状物体的latent code,我们可以通过latent code的线性插值来实现形状上的语义插值,上图最左边和最右边是两个不同的物体,中间是一系列语义插值的结果
Original: https://blog.csdn.net/qq_43420530/article/details/122404223
Author: 理想很丰满,现实很骨感
Title: DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532713/
转载文章受原作者版权保护。转载请注明原作者出处!