

Incorporating Explicit Knowledge in Pre-trained Language Models for Passage Re-ranking
SIGIR2022
论文链接:https://arxiv.org/abs/2204.11673


ABSTRACT
现有的基于 PLM 的重排序器可能很容易受到词汇不匹配和缺乏特定领域知识的影响。
本文引入了知识图谱中的显性知识,并且剪去嘈杂和不可靠的关系;将显性知识与隐性知识交互。
(外部知识库ConceptNet)
INTRODUCTION
隐性知识限制了PLM模型的重排效果。
为了克服这些限制,必须将知识图谱作为显式知识合并到基于 PLM 的重新排序器中。
本文提出了知识增强重新排序模型 Knowledge Enhanced Re-ranking Model(KERM),它利用外部知识显式增强基于 PLM 的重新排序器中的语义匹配过程。
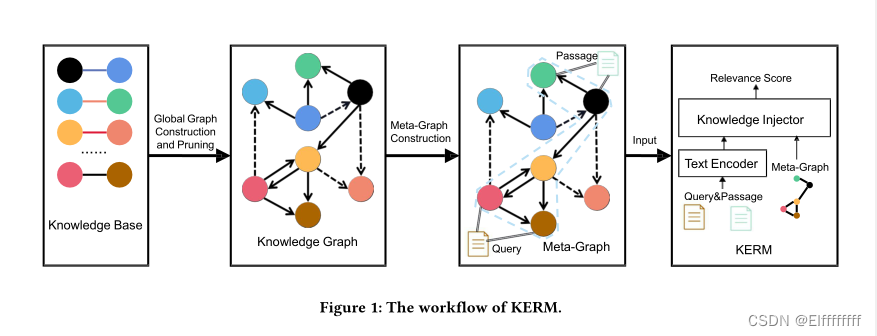
KERM 的整体工作流程如图 1 所示。
显性知识对段落重排的两个挑战:
挑战 1. 现有的知识图谱不是为重新排序任务而构建的。它们通常包含琐碎的事实三元组,很难带来信息增益。不适当的外部知识选择甚至可能危害重新级别的性能。如何利用现有的知识图谱对任务进行重新排序仍然是一个挑战。
挑战 2. 显性知识和隐性知识由于来源不同而高度异构,这使得两者的聚合变得困难。如何相互提炼,有效地将显性知识聚合为隐性知识,以缓解查询和段落之间的语义鸿沟,仍然是一个挑战。
KERM的工作流程可以分为 知识图谱蒸馏和知识聚合来应对上述挑战。
对于知识图谱蒸馏,本文提出了一种新的管道来建立 知识元图,它只保留用于段落重新排序的信息知识。具体来说,首先通过基于 TransE 嵌入修剪一些不可靠或嘈杂的关系,从现有知识图谱中提取一个全局图用于段落重新排序场景。然后对于特定的查询-段落对,从查询和段落中提取实体,并基于查询和段落实体及其k-hop邻居构建查询-文档二分实体图,即知识元图。
对于知识聚合,本文在文本和知识图谱之间设计了一个新颖的交互模块, 以结合隐式和显式知识。 为了从文本中获取隐含知识,使用 PLM 作为文本编码器。 为了与隐式知识对齐,知识元图用多层图神经网络(即k-hop)编码,即图元网络(GMN)。每个转换器层输出单词表示。每个图元网络层输出实体表示。单词和实体表示都被聚合为以下转换器和 GMN 层的输入,分别在一个新颖设计的模块中,即 知识注入器。因此, 通过知识聚合,来自文本语料库的隐性知识和来自现有知识图谱的显性知识可以相互促进,以实现更好的重新排序性能。
PROBLEM FORMULATION
KERM
合并显性知识的主要挑战是
1)提取对重新排序任务有用的知识图
2)以可以提高整体性能的适当方式将显性知识与当前隐性知识聚合
Knowledge Graph Distillation知识图谱蒸馏
因为现有的知识图谱通常是不完整且嘈杂的。不适合将它们 直接引入当前模型。
从 全局和 局部角度提出知识图谱蒸馏过程至关重要。
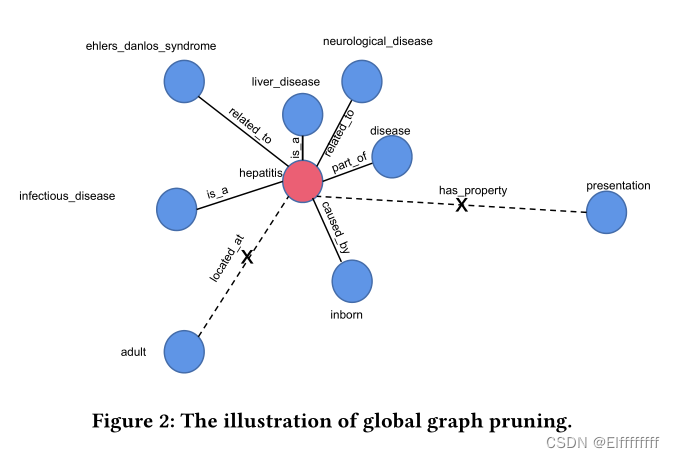
Step 1: Global Graph Pruning.
给定一个全局知识图 G,第一步是消除那些可能有噪声应用的知识。为了实现这一点,本文使用 TransE来衡量给定知识三元组的可靠性。(TransE 是一种无监督学习方法,可以学习知识三元组((
,r,)的潜在表示。)
使用 TransE 预训练的实体嵌入来计算两个链接实体之间的距离度量:
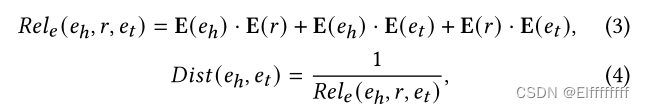
其中 E(e) 和 E(r) 分别是实体和关系的 TransE 嵌入, 内积衡量两个向量之间的相关性。由于 TranE 的目标与最小化等式(4)中所示的距离一致,可以将那些距离值小的知识三元组视为信息性知识。
在衡量了知识的可靠性之后,只保留给定实体
的top-个相邻实体N( )
修剪后的全局图为
(修剪案例如下图)
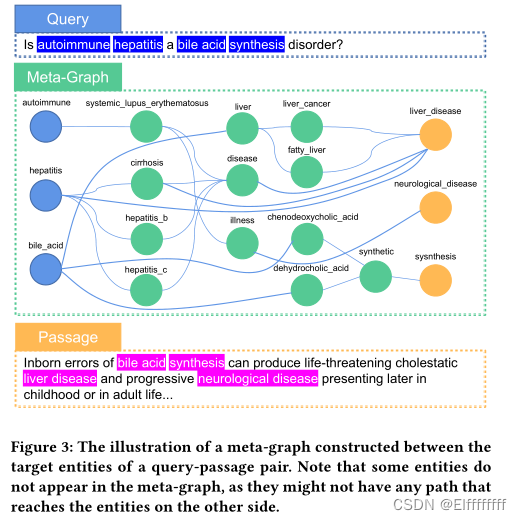
Step2: Meta-Graph Construction
进一步利用全局图 G 中的知识来构建查询和通道之间的”桥梁”,从而缓解语义差距并改进语义建模。
具体地说,对于给定的查询-段落对(即 (q, p)),我们建议构建一个二分元图,将 q 中的那些实体和 p 中的那些实体连接起来。
构建过程有三个步骤:
(1) Key sentence selection.关键句选择
只关注与查询最相关的每个段落的句子。从 Word2Vec 嵌入中初始化 E(w)。最相关的句子为s*
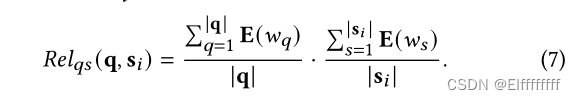
(2) Target entity recognition.目标实体识别
选择 q 和 s* 中的实体来构建元图。只考虑在
中完全匹配的实体( ,∈ )
(3) Path discovery.路径
给定 q 和 s∗ 的目标实体(表示为
和)。在 上执行广度优先搜索 (BFS) 以发现 和之间的 K-hop 内的路径。只保留可能对下游重新排序任务最有用的跳内路径。同时,可以从 K-hop 路径中补充知识。
Knowledge Aggregation
给定一个元图
,提出了一个基于 PLM 的重新排序器。
首先介绍 文本编码器,然后介绍如何将
中的 显式知识注入编码器。
Text Encoder.
采用常用的交叉编码器作为文本编码器。
输入被公式化为查询-段落对的连接,输入层将token索引转换为一组token embedding(记为
)。
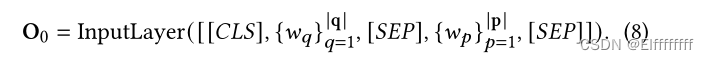
在第 l 变换层中,文本上下文特征通过多头自注意力和前馈网络(FFN)提取为
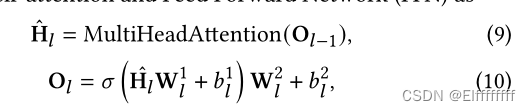

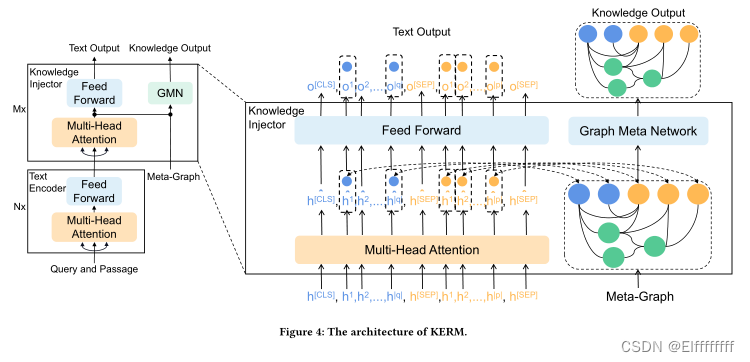
Knowledge Injector.
本文开发了一个可以无缝集成显式知识的知识注入器。此外,受 CokeBERT 的启发,本文的知识注入器配备了一个 GMN 模块,可以根据文本编码器学习到的文本上下文特征动态提炼知识上下文,进一步提高了知识增强的灵活性和可用性。此外,本方法允许文本上下文和知识上下文相互作用并相互促进。
Knowledge injection.
如图 4 所示,知识注入器由多个 Transformer 层组成,与文本编码器相同。给定一个查询-段落对 (q, p),首先在
中找到可以通过外部知识增强的实体。对于这些实体,将 E 定义为要应用于知识注入层的知识嵌入,其中 E 由从修剪后的全局图 G 中提取的 TransE 嵌入初始化。接下来,将 每个实体与相应短语的第一个标记对齐选择关键句,并将知识注入过程定义为:
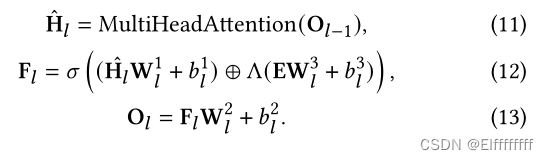
⊕ 表示元素相加,Λ(·) 表示对齐函数将实体映射到标记的相应位置
通过这样做,外部知识 E 被集成到知识注入层的输出
中。该查询-段落对的最终相关性得分定义为:
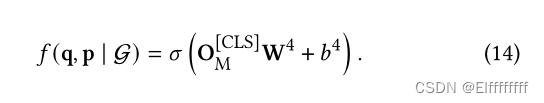
通过元图进行知识传播。值得注意的是,上述定义的知识注入程仅利用了 TransE 在全局图
上学习的知识嵌入。特别是,它缺乏考虑连接查询和通道之间语义的知识。为此,引入了一个图元网络 (GMN) 模块,该模块使用构建的元图 Gq,p 来细化知识,Gq,p 的多跳路径允许知识在查询和通道之间传播,这可以增强模型捕获的相关信号,从而缓解语义差距。
每个知识注入层都有一个多层 GMN(如图 4 所示)以在 Gq,p 上传播知识。首先,GMN 的输入用融合特征
表示为: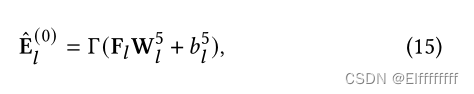

在 GMN 的第 k 层中,嵌入
的实体通过其邻居 N ( ) 的注意聚合更新为
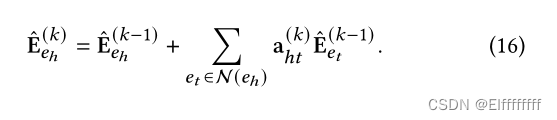 是注意力值,定义为:
是注意力值,定义为:
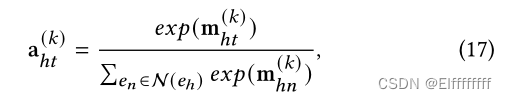
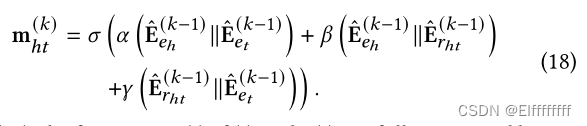
函数α(·)、β(·)和γ(·)是全连接层,·∥·表示连接操作。
通过在知识注入器的每一层中应用 k 层 GMN,输出实体表示
可以集成来自所有 k-hop邻居的知识。如第 4.1.2 节所述,q 和 p 之间的 Gq,p 的所有路径都在 K hops 内,GMN 模块可以沿着从 p 中的实体到 q 中的实体的路径专注地传播知识,反之亦然,这可以丰富有利于相关性建模的实体的语义。随后,更新的实体嵌入可以用作要注入下一层的知识,即 E := 。换句话说,我们可以重新定义方程式(12) 为:
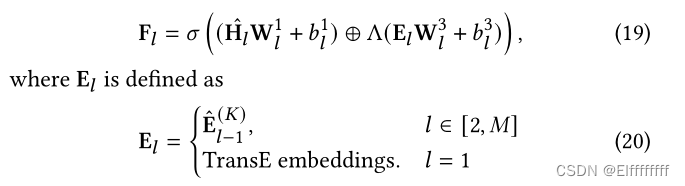
Model Optimization
Knowledge-enhanced pre-training
对 MSMARCO 语料库进行持续的预训练,以预热 GMN 模块的参数。将掩蔽语言模型 (MLM) 和句子关系预测 (SRP) 作为 KERM 中的预训练任务。与传统的下一句预测 (NSP) 相比,SRP 的任务是预测给定句子是下一句、前一句关系还是与另一个句子没有关系。为了在预训练阶段整合知识, 为每个句子对构建一个元图,并应用上面介绍的知识聚合过程。预训练损失定义为 :
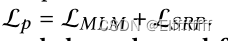
Knowledge-enhanced fine-tuning
采用交叉熵损失来微调 KERM:
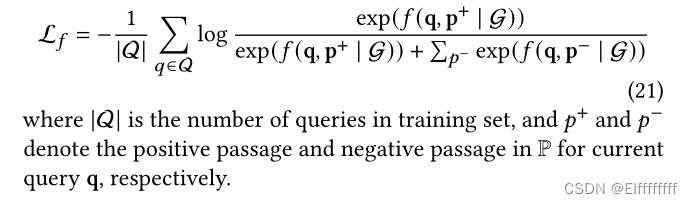
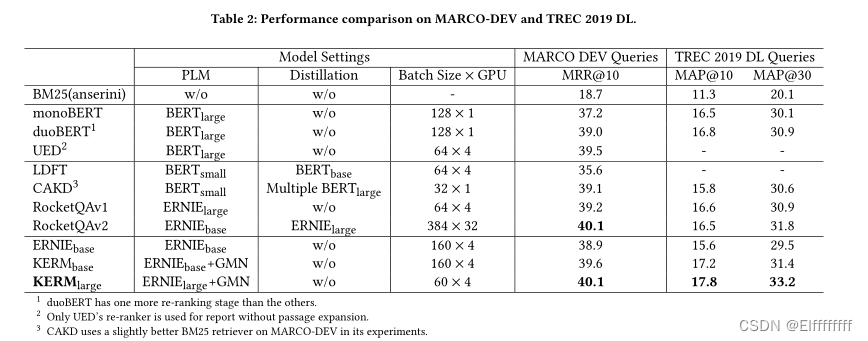
本文的主要目标是合理地将外部知识图谱引入 PLM 以进行段落重新排序。首先设计了一种新颖的知识元图构建方法,以从一般和嘈杂的知识图中提取可靠和查询相关的知识。知识元图弥合了每个查询和段落之间的语义鸿沟。然后提出了一个知识注入层,用于相互更新文本和知识表示,它将单词转换为图元网络的实体表示。
FUTURE WORKS
尽管本文方法中的知识图蒸馏被经验证明对最终性能有效,但图修剪和元图构建的实现仍然基于简单的启发式。制定有用的元图的一种更有希望的方法是以端到端的方式联合学习图生成器和重新排序器,这样可以提供更大的灵活性。此外,目前在检索阶段利用外部知识是不可行的,这需要为大量候选者详尽地构建海量元图。进一步的研究可以集中在如何在基于 PLM 的检索器中使用外部知识。
Original: https://blog.csdn.net/elf1110/article/details/124495633
Author: Elffffffff
Title: 【论文】外部知识的段落重排
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532089/
转载文章受原作者版权保护。转载请注明原作者出处!