

《Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning》论文解读


论文地址:https://arxiv.org/pdf/2104.03135.pdf
收录会议:ICVR 2021 Oral
(ICVR全称为IEEE Conference on Computer Vision and Pattern Recognition)
; 00.前言
为何使用visial-language预训练模型(VLPT)?
为什么要训练对图像和文本进行联合表示(joint representation)的VLPT,而不能分别使用文本预训练和图像预训练模型得到图像和文本的表示(representation)呢?
要回答这个问题,我们需要先看一看visual-language领域都有哪些任务
- 生成式任务,例如Image Caption(给定图片,根据图片内容生成文本描述)
- 理解式任务,例如Visual Question Answering(针对某图片内容进行提问,模型作出回答)
显然,这些任务的实现,需要图像与文本能够理解彼此,也就是需要在representation中能够体现二者语义上的对齐,这明显是分别获得二者的表示难以达到的
因此,在visual-language领域中,我们需要VLPT模型,通过学习大规模易于访问的图像-文本对,得到更好的跨模态(cross-modal)表示。
Visual Representation
视觉表示在VLPT模型中起着重要作用。
文本可以看作离散的数据,由一个个单词组成,单词作为语义单元,可以自然地被作为token输入到预训练模型。语言中的单词虽然多,但也是有限的,因此在预训练任务mask language model(MLM)中, 每个单词可以直接作为一个label,遮住某个单词使模型去预测该单词。
而图像则是连续的数据,无法自然地划分成可以作为语义单元的token。并且图像的组成是无限的,每块图像都独一无二,自然不能像文字一样将每块图像作为一个label,因此遮住一块图片时无法直接去重构这块图片。所以, 必须先人为将图像分割成小块,或利用目标检测识别出图中每个物体,来作为图像的token。同时需要利用分类器 获得每个token的类别作为label。在预训练任务中,遮住一个图像块,使模型去预测该块图像的类别。
VLPT中的视觉表示的发展经过了以下几个阶段:
1、早期的研究使用在ImageNet上预先训练的CNN分类模型来提取视觉特征以及类别标签;
2、后来,Anderson等人提出了一个自下而上和自上而下的注意(Bottom-Up and Top-Down Attention , BUTD) 检测模型(detection model)。VLPT模型最近的成功也得益于这种基于区域(region-based)的图像特征的使用,这些特征由训练好的检测模型提取。通常会使用Fast-RCNN模型,该模型可以在检测出图像中的region同时获得region的标签;
目前流行的VLPT模型通过1或2方式将图像分成小块,每一块作为一个token输入,如图所示:
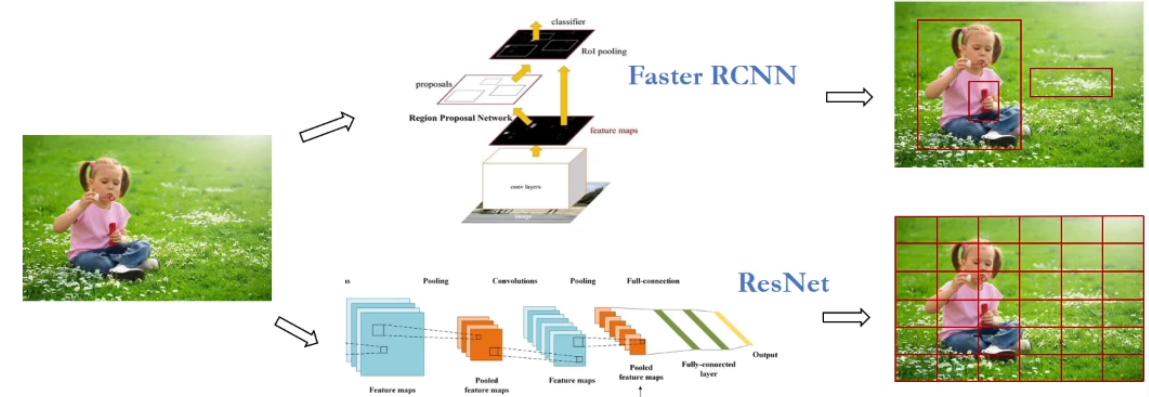
3、最近,一些研究表明,若能进行适当的处理,卷积网络的网格(grid)特征形式的视觉表示是有效的
; 01. Introduction
论文研究了VLPT的CNN和Transformer的联合学习,旨在从数百万图像-文本对中学习跨模式对齐。
论文指出,目前用的最多的基于区域(region-based)的视觉特征提取方式,有着忽略图像整体上下文信息等缺陷
region-based图像特征的三个挑战
1、区域聚焦于边界内的对象Boxes忽略了文本之外的上下文信息框,这对关系理解和推理很重要
2、对图像的视觉理解局限于区域的预定义类别
3、大多数基于区域的图像特征是通过检测模型提取的,该检测模型会受到低质量、噪声和过采样的影响,并且依赖于大规模数据

; 如何利用整张图片的上下文信息呢?
最简单的就是回归到网格形式的视觉特征(上一章节visual representation的第一阶段方法)
但是又不能直接回到这一阶段,因为这样同样会造成语义割裂:1)语义相近的图像块可能被分到不同的类别,2)同样将图像块局限在事先设定的类别,3)而且如果分类出错的话,预训练模型从输入就错了,会对训练产生干扰
因此作者提出,不把分类和预训练作为两个分开的模型,而是 将分类模块也放进整体的预训练模型中一起训练,使分类模块也能在预训练模型中得到训练。
SOHO的提出
SOHO便是这样的模型。这一个端到端(end-to-end)的视觉语言预训练框架,可直接从图像-文本对中学习图像嵌入、语言嵌入及其语义对齐。
SOHO不去事先将图片分成小块作为token输入,而是将整张图片作为输入,用整体模型中的CNN模块提取图片特征,直接优化视觉表示来学习更加丰富的视觉语义特征
为了更好地对齐视觉特征和语言标记,SOHO中图像块的类别也是可以动态调整的,这能够更好地避免分类错误造成的影响。
作者提出了 视觉词典(visual dictionary, VD) 来实现这一思路,VD可以在训练中动态更新,它代表了更全面、更紧凑的视觉语义。 VD将具有相似视觉语义的视觉像素分组,它表示了图像中相似语义的视觉抽象。

对于输入图像(d),使用可训练的基于CNN的编码器(e)来提取视觉表示。为了进一步将图像特征转换为一致的语义,将基于视觉词典(visual dictionary,VD)的图像嵌入(f)应用于图像编码器的输出。
- visual encoder将图像作为输入并生成视觉特征(visual feature)
- VD embedding模块通过一个视觉词典(VD)将不同的视觉语义信息聚合成视觉标记(visual token)
- Transformer融合视觉和语言模式的feature,并产生特定任务的输出
下文将介绍不同模块的具体实现
2.1 Trainable Visual Encoder
给定图片 I \mathcal{I}I ,输出图片特征 V = E ( I , θ ) ∈ R l × c \mathcal{V}=E(\mathcal{I},θ)∈R^{l×c}V =E (I ,θ)∈R l ×c , 其中 E E E 为encoder,θ θθ为参数,l l l表示embedded feature vectors的数量,c c c表示vector的维度。v i v_i v i 代表V V V的第i i i个feature vector。
采用在ImageNet上预训练的ResNet,接一个1×1卷积层和2×2最大池层作为编码器E的结构
2.2 Visual Dictionary
Visual Dictionary Embedding
定义Visual Dictionary(VD)为一个矩阵D ∈ R k × c \mathcal{D }∈R^{k×c}D ∈R k ×c,包含k个维度为c的向量,计第j个向量为d j d_j d j .
对于每个v i v_i v i ,计算与其最相似的d j d_j d j ,将该index j j j记为h i h_i h i ,对应上图的”Query”步骤h i = a r g m i n j ∣ ∣ v i − d j ∣ ∣ 2 h_i=argmin_j ||v_i-d_j||2 h i =a r g m i n j ∣∣v i −d j ∣∣2 将VD embedding定义为一个映射函数(mapping function f f f), 它将vi映射到D \mathcal{D}D ,对应上图的”Mapping”步骤f ( v i ) = d h i f(v_i)=d{h_i}f (v i )=d h i 也就是说v i v_i v i 的VD embedding f ( v i ) f(v_i)f (v i )等于 D \mathcal{D}D 中与v i v_i v i 最接近的向量的值。
Momentum Learning for Visual Dictionary Update
VD的初始化是随机的,之后通过一个小批量的移动平均操作进行更新,用d j ^ \hat{d_j}d j ^表示更新得到的d j {d_j}d j ,d j ^ = γ ∗ d j + ( 1 − γ ) ∗ ∑ h i = j v i ∣ f − 1 ( j ) ∣ \hat{d_j}=\gammad_j+(1-\gamma)\frac{\sum_{h_i=j}{v_i}}{|f^{-1}(j)|}d j ^=γ∗d j +(1 −γ)∗∣f −1 (j )∣∑h i =j v i 其中反函数f − 1 ( j ) f^{-1}(j)f −1 (j )表示将index j映射回一组visual feature,∣ f − 1 ( j ) ∣ |f^{-1}(j)|∣f −1 (j )∣代表这组向量包含的向量个数。γ \gamma γ是一个动量系数( momentum coefficient ),取值范围是[0,1]
Gradient Back Propagation
由于argmin操作不可微,梯度反向传播会在VD处停止( the gradient back propagation will be stopped by the visual dictionary)
为了使视觉特征编码器visual encoder可训练,按照下式更新f ( v i ) f(v_i)f (v i ):f ( v i ) = s g [ d h i − v i ] + v i f(v_i)=sg[d_{h_i}-v_i]+v_i f (v i )=s g [d h i −v i ]+v i s g ( ⋅ ) sg(\cdot)s g (⋅)表示stop gradient operater
视觉词典相当于基于特征相似性对视觉feature map进行在线聚类,并使用聚类中心表示每个特征向量。
VD面临一个冷启动问题,直接将梯度从随机初始化的嵌入向量复制到可视化特征映射(visual feature map)将导致错误的模型优化方向(即模式崩溃)。因此,在前10个训练周期中冻结视觉特征编码器中ResNet的参数。
2.3 Pre-training Pipeline
对于预训练任务,除了两种常用的任务:Masked Language Modeling (MLM)和Image-Text Matching(ITM)外,论文还提出了一种基于学习的视觉词典的新型Masked
Vision Modeling (MVM)任务
Masked Language Modeling
MLM的目标是通过最小化负对数似然,基于其他单词标记W − i \mathcal{W}{-i}W −i 和所有图像特征f ( V ) f(\mathcal{V})f (V )预测屏蔽单词标记。
L M L M = − E ( W , f ( V ) ) ∈ D log p ( w i ∣ W − i , f ( V ) ) L{MLM}=-\mathbb{E}{(\mathcal{W},f(\mathcal{V}))\in D} \log{p(w_i|\mathcal{W}{-i},f(\mathcal{V}))}L M L M =−E (W ,f (V ))∈D lo g p (w i ∣W −i ,f (V ))
Masked Visual Modeling
最小化负对数似然,基于其他图像特征f ( V ) − i ) f(\mathcal{V}){-i})f (V )−i )和所有单词标记W \mathcal{W}W预测屏蔽的图像特征
L M V M = − E ( W , f ( V ) ) ∈ D log p ( f ( v i ) ∣ W , f ( V ) − i ) L{MVM}=-\mathbb{E}{(\mathcal{W},f(\mathcal{V}))\in D} \log{p(f(v_i)|\mathcal{W},f(\mathcal{V}){-i})}L M V M =−E (W ,f (V ))∈D lo g p (f (v i )∣W ,f (V )−i )
当图像特征vi被mask时,其在VD中的映射索引(mapping index)j = h i j=h_i j =h i 被视为其标签相邻的feature可能具有相似的值,从而共享相同的映射索引。这将导致模型”偷懒”直接从周围feature复制标签,达不到学习的目的。因此在做mask时,我们首先随机选择一个现有的标签索引j,然后将f − 1 ( j ) f^{-1}(j)f −1 (j )中的所有embedding替换成[MASK]标记。
Image-Text Matching
使用二分类器ϕ ( ⋅ ) \phi{(\cdot)}ϕ(⋅)对[CLS] token这一 joint embedding feature 做预测,预测图文是否匹配
L I T M = − E ( W , f ( V ) ) ∈ D log p ( y ∣ ϕ ( W , f ( V ) ) ) L_{ITM}=-\mathbb{E}_{(\mathcal{W},f(\mathcal{V}))\in D} \log{p(y|\phi{(\mathcal{W},f(\mathcal{V}))} )}L I T M =−E (W ,f (V ))∈D lo g p (y ∣ϕ(W ,f (V )))y取1代表匹配,0表示不匹配
以上三个预训练任务的loss相加,即为SOHO模型的loss。
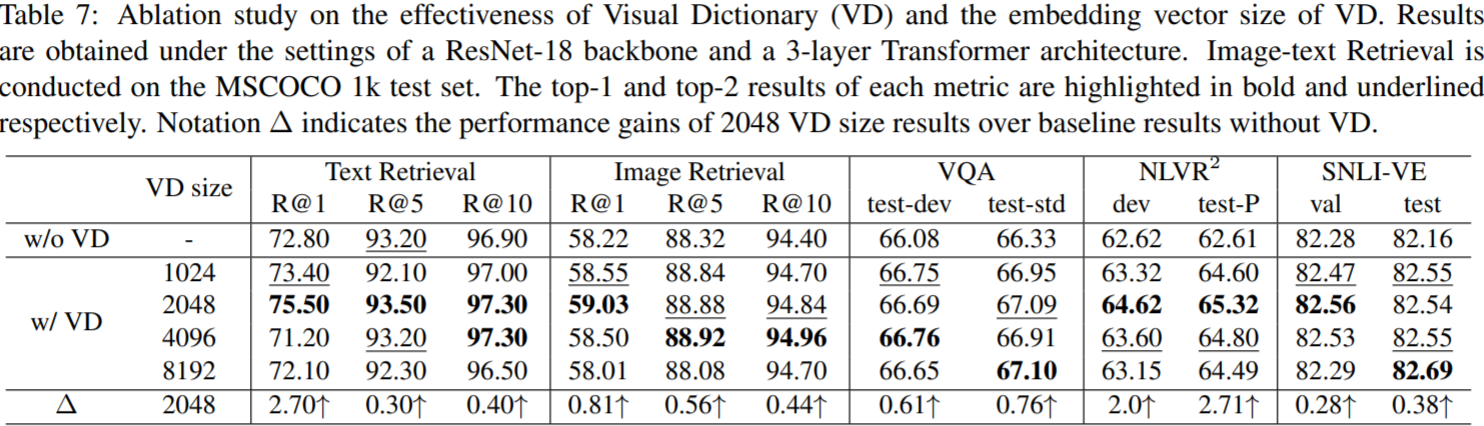
03 Experiment
在下游任务中测试SOHO性能,包括 image-text retrieval(分为image-to-text retrieval (TR) and text-to-image retrieval (IR) ),visual question answering (VQA), natural language for visual reasoning(NLVR), 以及 fine-grained visual reasoning (Visual Entailment, or VE).
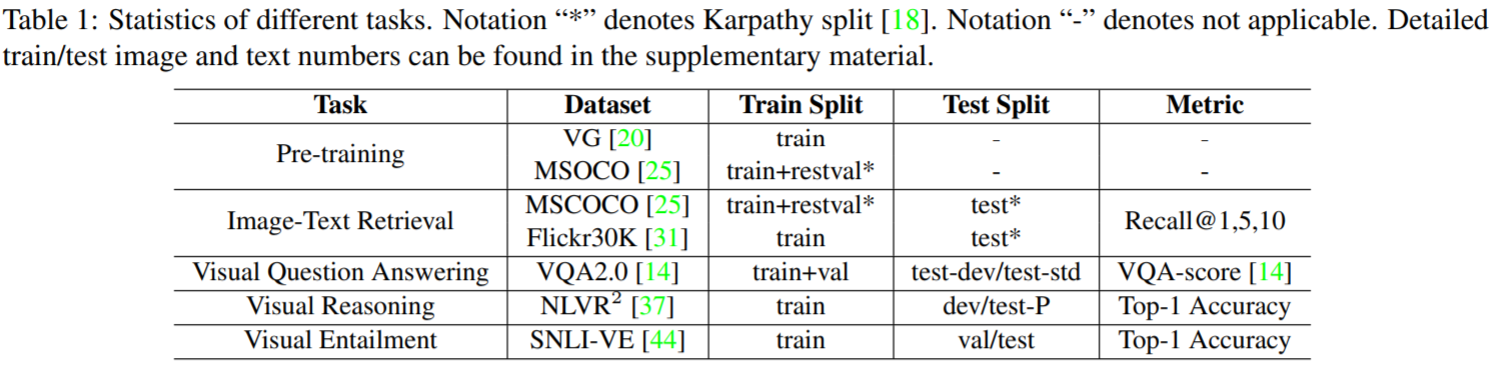
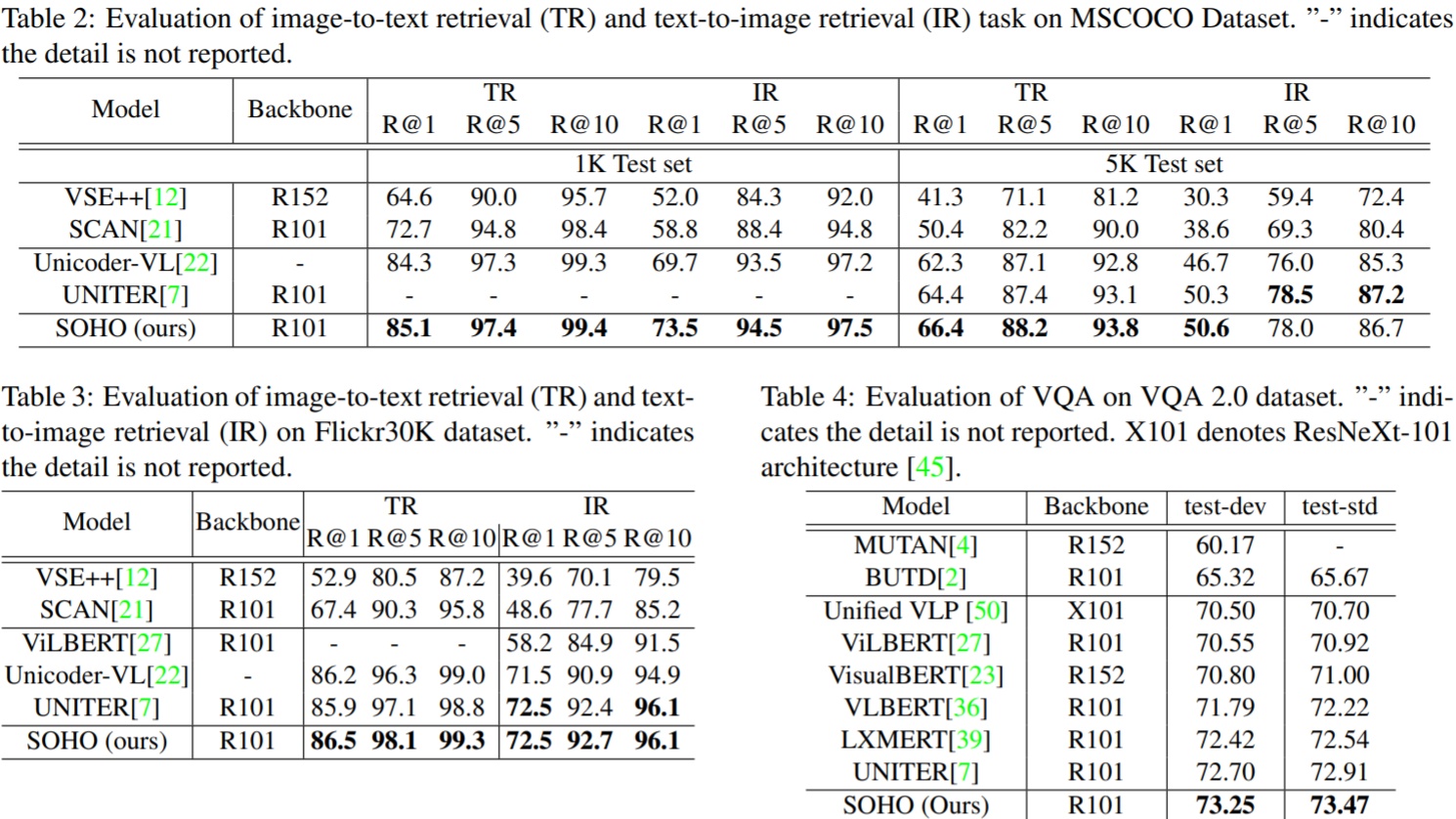
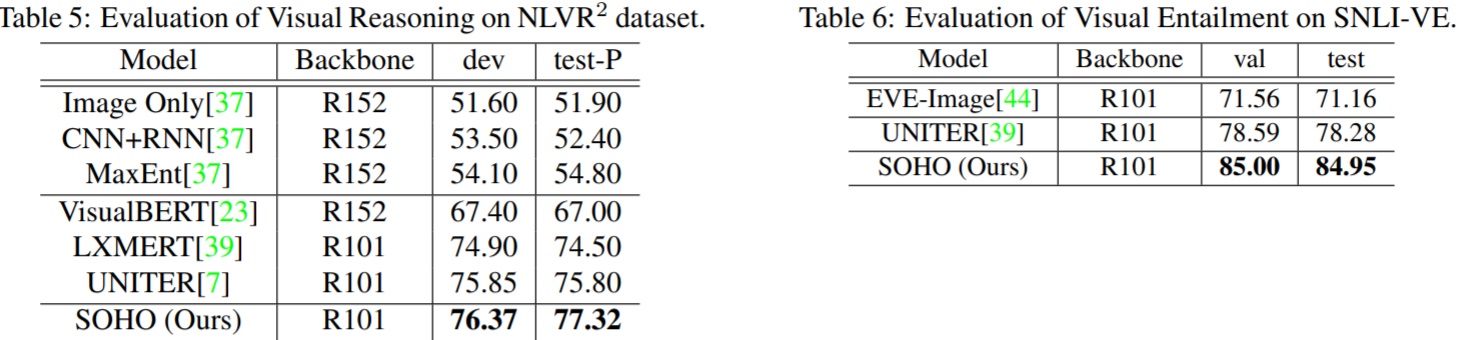
各个任务的测试结果如下:
Visualization of VD

选取VD中的两个index,展示该index对应的部分visual feature,根据图示结果,可以认为VD能够较好地将具有相同语义的图像块归为一组。
; Time Inference
基于BUTD的方法主要包括三个推理阶段:CNN forwarding, region feature generation, 以及Transformer forwarding,SOHO只需要两个:CNN 和 Transformer forwarding.
基于BUTD方法的模型主要时间成本来自于region feature generation阶段,在图像的目标检测过程中,模型会采用非极大值抑制(Non-Maximum Suppression)算法,这一过程会消耗大量时间。
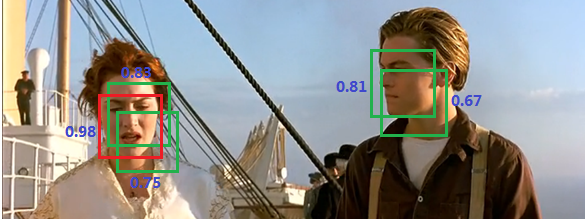
简单来讲,在进行目标检测时一般会采取窗口滑动的方式,在图像上生成很多的候选框,然后把这些候选框进行特征提取后送入分类器,一般会得出一个置信度得分(confidence score),即同一目标的位置上会产生大量的相互有重叠的候选框。下图是一个人脸识别的例子:
NMS算法根据置信度从高到低,依次将当前最高置信度边界框从边界框列表中取出挪入输出列表,计算其与剩余每个边界框的重合程度IoU(intersection-over-union,即两个边界框的交集部分除以它们的并集),设置阈值删除IoU大于阈值的边界框,迭代上述过程直至边界框列表为空。这相当于对每一个物体选取一个得分最高的框,删除周边重合较大的框。
实验证明,SOHO比BUTD-based methods快约10倍。
04 Conclusion
论文展示了visual-language模型设计的一种新视角,提出了SOHO,这是第一个端到端视觉语言预训练模型之一,它学习全面而紧凑的视觉表示以实现跨模态理解。为了生成能够与语言标记(language token)融合的视觉特征,论文提出了一种新的视觉词典(VD)来将图像转换为具体的语义。在四个下游任务上的性能显示了SOHO相对于基于区域的图像特征的预训练模型的优越性。此外,此端到端框架减轻了对边界框注释的要求,并减少了沉重的人工标注成本。实验展示了SOHO将视觉语言任务中的推理时间缩短约10倍的优点,从而支持更多在线视觉语言应用。
Reference
BUTD: https://arxiv.org/pdf/1707.07998.pdf
Fast-RCNN: https://arxiv.org/pdf/1504.08083.pdf
In defense of grid features for visual question answering. https://arxiv.org/abs/2001.03615
Original: https://blog.csdn.net/qq_38299788/article/details/121054103
Author: Katerina
Title: 跳出检测模型边界框的局限:一种基于网格特征的visual-language预训练模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532059/
转载文章受原作者版权保护。转载请注明原作者出处!