

文章目录
SQL 语言是一个标准,但是没有任何两个数据库管理系统的实现完全相同。每种 SQL 实现都有自己的特性和扩展功能,SQLite 也是如此。
SQLite
嵌入式数据库引擎
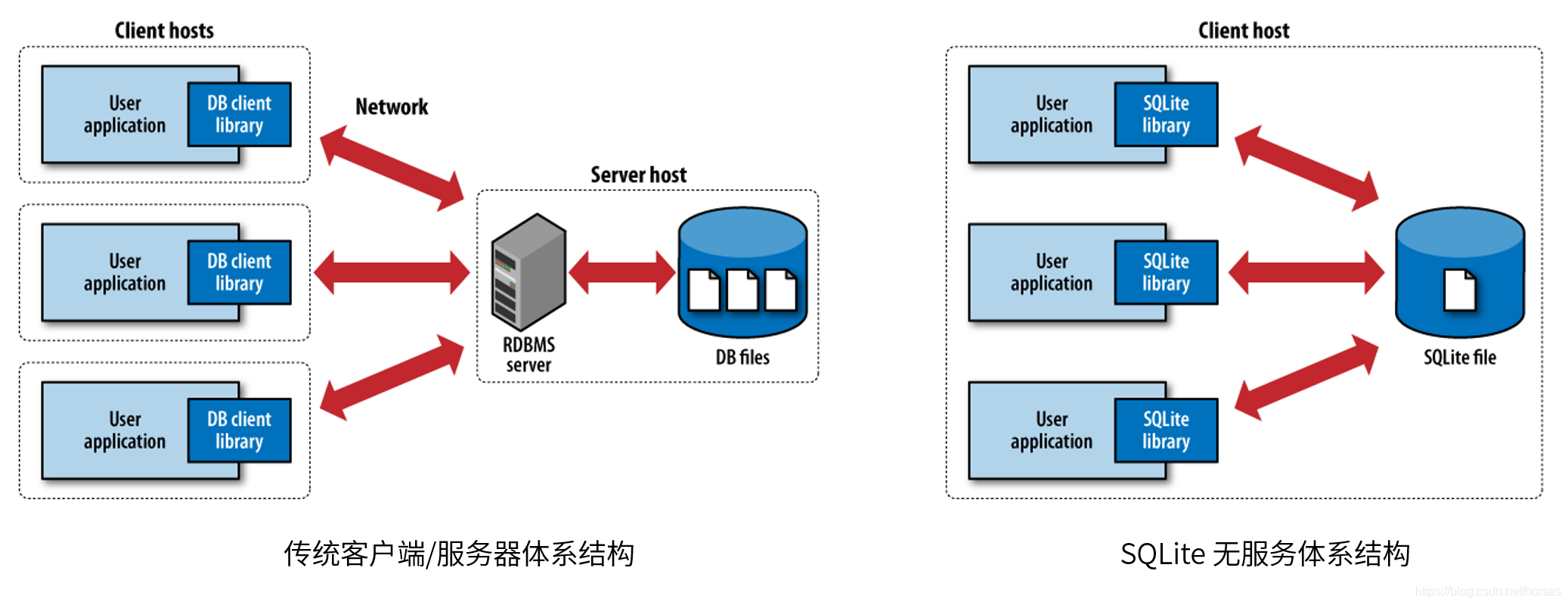
相对于其他数据库引擎而言,例如 SQL Server、PostgreSQL、MySQL 或者 Oracle,SQLite 最重要的区别在于它的设计目标不是这类数据库系统的替代者。SQLite 是一个 嵌入到应用程序中的数据库引擎, 没有服务端,没有单独管理数据库的服务器进程。应用程序通过函数调用和数据库引擎进程交互,而不是将消息发送给单独的进程或线程。
客户端/服务器数据库对于现代应用系统非常重要,它们专注于可伸缩性、并发性、集中管理和控制等,解决了企业数据的共享存储问题。 SQLite 则致力于为单个应用程序和设备提供本地数据存储,强调的是经济、效率、可靠性、独立性和简单性。

; SQLite 支持的使用场景
- 嵌入式设备和物联网应用。例如手机、机顶盒、电视、游戏机、照相机、手表、厨房用具、恒温器、汽车、机床、飞机、远程传感器、无人机、医疗设备和机器人等等。
- 桌面应用程序的磁盘文件格式。例如版本控制系统、财务分析工具、媒体编目和编辑套件、CAD 软件包、记录保存程序等。
- 中小型网站。对于大多数中小型流量的网站(也就是大多数网站),SQLite 可以作为数据库引擎。 一般来说,每天点击量少于 10 万的网站都可以正常运行。这是一个保守的估计,SQLite 已经被证明可以处理 10 倍以上的流量。
- 数据分析。熟悉 SQL 的人员可以使用 sqlite3 命令行工具或者第三方程序来分析大型数据集,包括网站日志分析、体育统计分析、程序编译指标以及实验结果分析。
- 企业数据的缓存。很多应用程序使用 SQLite 作为企业 RDBMS 数据的本地缓存,加快了前端响应速度,同时减少了网络传输和核心数据库服务器上的负载。另外,而且很多情况下,客户端应用程序可以在网络中断期间继续运行。
- 服务器端数据库。客户端发送请求到服务端,服务端将请求转换为 SQL 查询,获取结果并进行处理之后返回客户端。服务端支持并发访问,然后将数据库请求串行化。另外,通过使用多个数据库文件可以进一步提高并发支持。例如,每个用户对应一个数据库,每个数据库只有一个连接。
- 数据传输的文件格式。一个 SQLite 数据库就是一个压缩的文件,具有跨平台支持的格式,因此也可以作为应用传输数据的容器。
- 文件归档和数据存储。SQLite 的归档功能可以作为 ZIP 归档或者 TAR 的替代。
- 替代临时磁盘文件。很多程序需要使用 fopen()、fread() 和 fwrite() 接口创建和管理专用格式的数据文件,SQLite 非常适合替代这种文件,而且比文件系统读取更快。
- 内部数据库或者临时数据库。如果程序需要对大量数据进行各种筛选和排序,将数据加载到 SQLite 内存数据库中进程操作通常比手动编写代码进行处理会更简单快速。这种方式还提供了很好的灵活性,因为可以增加新的字段和索引,而不需要重新对查询进行编码。
- 演示或者测试数据库。客户端应用通常使用一个通用的数据库接口(例如 JDBC),可以连接到各种数据库。在测试或者演示时可以连接到 SQLite 数据文件,而不需要安装单独的数据库服务器。
- 教学和培训。SQLite 安装个使用非常简单,只需要将 sqlite3 或者 sqlite3.exe 复制到指定机器然后允许即可。因此,SQLite 非常适合学习 SQL 语句和分享。
- SQL 扩展特性的试验。SQLite 具有简单的模块化设计,因此非常适合用于新的数据库语言特性或者理念的试验。
灵活的数据类型
SQLite 提供了非常灵活的数据类型。
其中的关键在于 SQLite 对数据库中数据的类型要求非常宽松。例如,可以将一个字段的类型定义为 INTEGER 之后,插入数据时存储一个字符串;此时 SQLite 会尝试将字符串转换为整数,因此 ‘1234’ 会被转换为 1234 并存入表中。但是,如果插入一个非数字的字符串(例如 ‘wxyz’)SQLite 也不会报错,而是直接存储一个字符串值。这一点显然和其他数据库不同。
与此类似,SQLite 允许将一个 2000 字符长度的字符串插入一个 VARCHAR(50) 类型的字段中;其他数据库则会报错或者截断输入的字符串。
如果在初始开发过程中使用 SQLite,然后部署上线时替换为其他数据库(PostgreSQL 或者 SQL Server),可能会因此导致问题。因为 SQLite 对于类型的要求更加宽松,其他数据库对于类型的要求更加严格。
这种灵活的数据类型是 SQLite 的一个特性,而不是缺陷。但无论如何,这个特性的确会给熟悉其他数据库的开发人员带来一些困惑和痛苦。也许更好的方式是 SQLite 提供一个 ANY 数据类型,开发人员就可以在需要时使用灵活类型,而不是默认使用这种类型。但是,现在改变这一行为会损坏已经使用该功能的数百万应用程序和数十亿个数据库文件。
数据库操作
连接数据库
import sqlite3
conn = sqlite3.connect('test.db')
print("Opened database successfully")
cursor = conn.cursor()
...
cursor.close()
conn.commit()
conn.close()
创建表
...
cursor = conn.cursor()
sql = 'CREATE TABLE Student(id integer PRIMARY KEY autoincrement, Name varchar(30), Age integer)'
cursor.execute(sql)
conn.commit()
...
插入数据
...
cursor = conn.cursor()
sql = "INSERT INTO Student(Name, Age) VALUES(\'love\', 22)"
cursor.execute(sql)
data = ('love2', 2221)
sql = "INSERT INTO Student(Name, Age) VALUES(?, ?)"
cursor.execute(sql, data)
conn.commit()
...
删除数据
cur = conn.cursor()
sql = 'delete from score where id=?'
id = (3,)
cur.execute(sql, id)
conn.commit()
cur.close()
conn.close
查询数据
...
cursor = conn.cursor()
sql = "select * from Student"
values = cursor.execute(sql)
for i in values:
print(i)
sql = "select * from Student where id=?"
values = cursor.execute(sql, (1,))
for i in values:
print('id:', i[0])
print('name:', i[1])
print('age:', i[2])
conn.commit()
...
数据库函数
排序
import sqlite3
conn = sqlite3.connect('scores.db')
sql = 'select * from score order by math_score desc,id'
cur = conn.cursor()
cur.execute(sql)
print(cur.fetchall())
conn.close
筛选
import sqlite3
conn = sqlite3.connect('stu.db')
sql = 'select name,wulinm from cj '
cur = conn.cursor()
cur.execute(sql)
print(cur.fetchall())
conn.close
统计
import sqlite3
conn = sqlite3.connect('scores.db')
sql = 'select chinese_score + 1 from score'
cur = conn.cursor()
cur.execute(sql)
print(cur.fetchall())
conn.close
其他操作
行对象
from sqlite3 import connect, Row
con = connect('scores.db')
con.row_factory = Row
cur = con.cursor()
cur.execute('select * from score')
row = cur.fetchone()
print(type(row))
print('以列名访问:', row['stu_name'])
print('以索访问:', row[1])
print('以迭代的访问')
for item in row:
print(item)
print('len():', len(row))
con.close
批量操作
from sqlite3 import connect, Row
con = connect('scores.db')
con.row_factory = Row
cur = con.cursor()
rows = [(10, 'z10', 80, 80), (11, 'z11', 80, 80)]
cur.executemany('insert into score (id,stu_name,math_score,chinese_score) values (?,?,?,?)', rows)
cur.execute('select * from score')
for row in cur:
for r in row:
print(r)
con.commit()
con.close
from sqlite3 import connect
con = connect('scoresb.db')
cur = con.cursor()
sql_str = """
create table test(id integer,name text);
insert into test (id,name) values (1,'lishi');
insert into test (id,name) values (2,'lishi2');
"""
cur.executescript(sql_str)
cur.execute('select * from test')
for item in cur:
print(item)
con.commit()
con.close
二进制文件操作
from sqlite3 import connect
con = connect('score33.db')
cur = con.cursor()
sql_str = """drop table if exists testa;create table if not exists testa(id integer,data blob);"""
cur.executescript(sql_str)
f = open('test.png', 'rb')
cur.execute('insert into testa (id,data) values (3,?)', (f.read(),))
cur.execute('select * from testa where id=3')
record = cur.fetchone()
f = open('tt.jpg', 'wb+')
f.write(record[1])
con.commit()
con.close
自增字段起始位置
update sqlite_sequence SET seq = 0 where name = '表名';
delete from sqlite_sequence where name='TableName'; --注意表名区分大小写
Original: https://blog.csdn.net/weixin_52316711/article/details/122709635
Author: chl1123
Title: SQLite+python
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/815850/
转载文章受原作者版权保护。转载请注明原作者出处!