

文章目录
Elastic search 8.0 在今年2月份更新,涉及两个大的功能点,分别为:
- 向量检索提高搜索相关性
- NLP组件支持NLP任务
这里先讨论向量检索模块。
向量检索
向量检索的索引结构为HNSW图模型,结构如下:
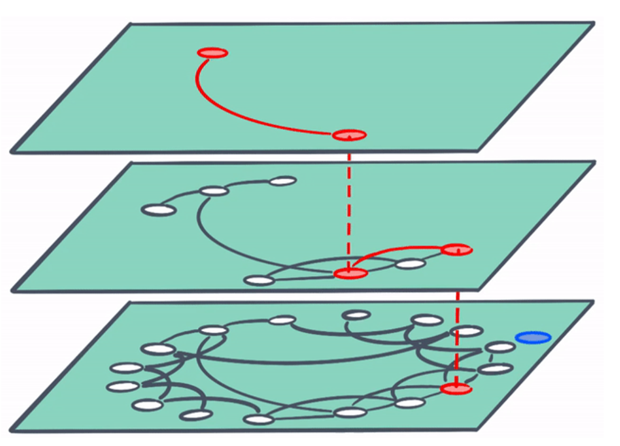

该类型的索引在ANN索引模型当中表现最优,其他索引类型如树模型、矢量模型相关介绍可以参考我之前写的博客:
https://blog.csdn.net/loveitlovelife/article/details/122567795
其实从7.0开始就已经对向量这一块做了一些处理和计算,7.0添加了dense vector 字段类型,实现稠密向量的存储,7.3和7.4添加了几种向量相关性计算方式,到了8.0实现了向量检索,7+的几种更新为8.0KNN向量检索的问世做了很好的铺垫。

; 实践
由于官方py-elasticsearch 还是基于7.13版本,不支持向量检索模块,因此我结合8.0官方API,利用postman、kibana、py-elasticsearch 三种工具进行实践(-_-!!),其中postman调用api做结果的对比分析,kibana构建索引,py-elasticsearch用来大批量的写入向量,虽然有一些麻烦和折腾,但是总归把这个功能给实现了。
具体实践步骤如下:
流程:
1.建立索引;2.写入数据&向量;3.检索分析
建立索引
索引在kibana里面的建立
PUT knn_test2
{
"mappings": {
"properties": {
"embedding": {
"type": "dense_vector",
"dims": 128,
"index": true,
"similarity": "cosine"
},
"document": {
"type": "text"
}
}
}
}
这里包含document、embedding两个字段,为文本及对应的embedding,类型分别为text、dense_vector两种,embedding的维度为128,计算方式为cosine、index为boolean,true代表该字段支持knn索引,false代表不支持。
写入数据&向量
利用py-elastic search 批量写入:
def bulk_index(questions, bulk_size, config):
logger.info("Bulk index for question")
count = 1
actions = []
for question_index, question in questions.items():
if count==1:
print(question)
action = {
"_index": config.index_name,
"_id": question_index,
"_source": question
}
actions.append(action)
count += 1
if count % 10000 == 0:
print(count)
if len(actions) % bulk_size == 0:
helpers.bulk(config.es, actions)
actions = []
if len(actions) > 0:
helpers.bulk(config.es, actions)
logger.info("Bulk index: %s" % str(count))
这里的questions为字典:{index0:{“document”:document0,
“embedding”:embedding0},index1:{}…},index为一个样本的编号,样本内容为一个字典,包含的字段及其类型与建立的索引字段类型一致。
检索分析
检索分析使用postman,这里分别用字面检索和向量检索方式进行对比:
字面检索的请求方式如下:
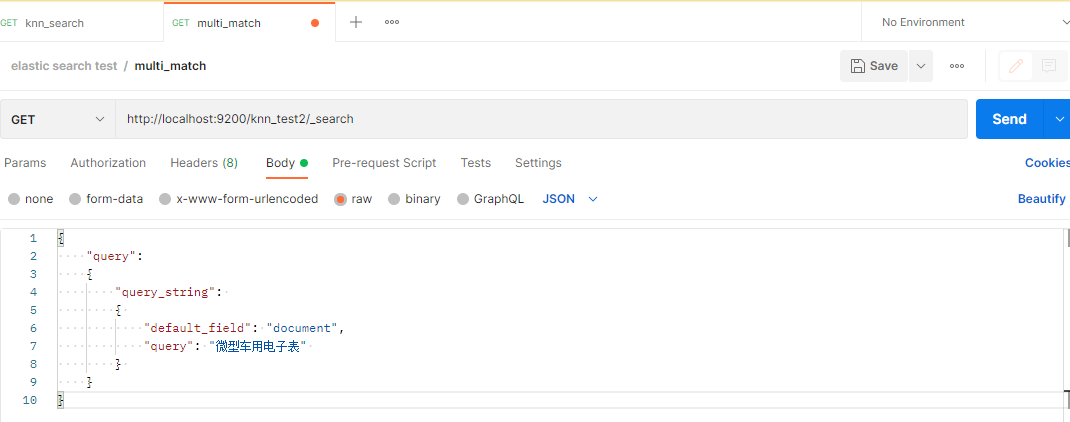
语义检索请求方式如下:
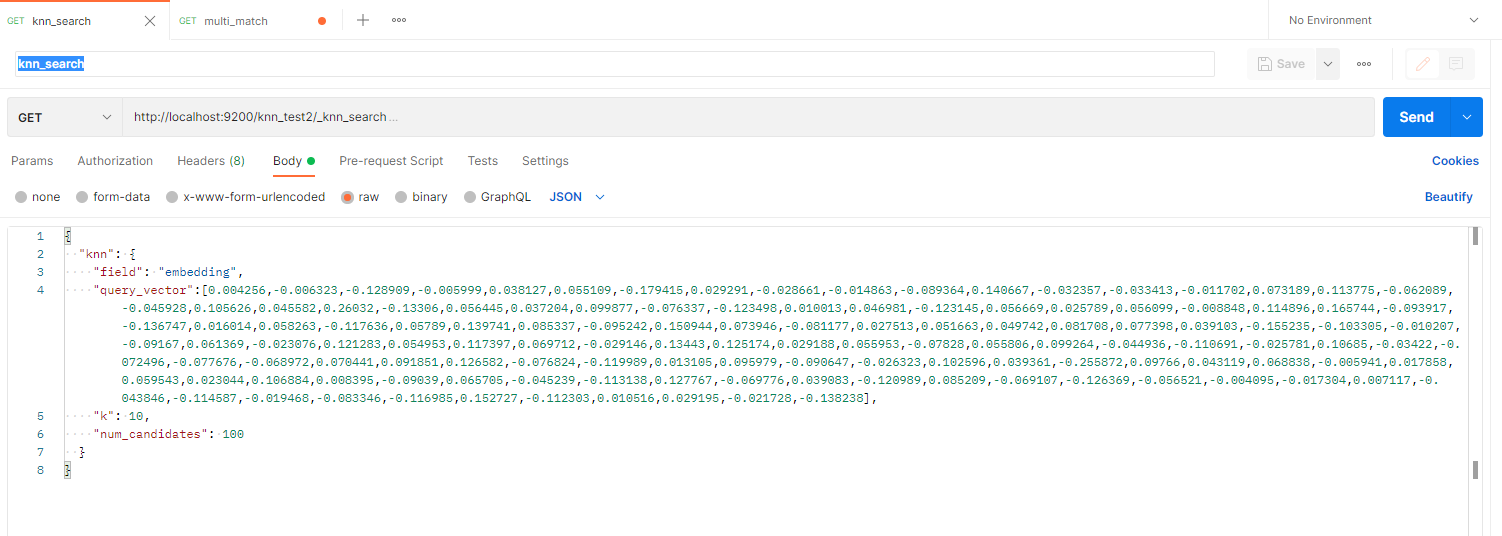
语义检索中的向量为字面检索文本通过语言模型映射得到,语言模型可以是word2vec、emlo、bert系列等,这里采用roberta-large微调以后的模型得到。
; 字面匹配结果

字面匹配top10,可以看出与”微型车用电子表”检索内容一致的document在排在第四位,top10内容一致的document有4个;
语义匹配结果

语义匹配top10,可以看出与”微型车用电子表”检索内容一致的document在排在第一位,top10内容一致的document超过了6个;
; 总结
整体来看向量检索的结果要远好于字面检索,而向量检索也具有相当高的时效性,在百万检索规模下具有毫秒级的响应时长参考链接,因此检索任务的耗时主要在query的预处理及向量编码上。所以在满足检索响应时长的条件下也可以对query做更多和精细的处理策略及编码,以进一步提高检索的准召率。
Original: https://blog.csdn.net/loveitlovelife/article/details/124185433
Author: loveitlovelife
Title: Elatstic search 8.0 在knn检索中的实践
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/532029/
转载文章受原作者版权保护。转载请注明原作者出处!