

本文是场景文本识别领域应用自然语言处理方法的前沿技术综述。改自作者2021年末交的工程前沿技术讲座课程大作业(另一门课程计算机视觉的大作业也是在此文基础上改进的)。
(看作者的博文目录应该就能看出作者是做自然语言处理和图神经网络的)
文章目录
一、背景介绍
本节将介绍场景文本识别任务,尤其是其中自然语言处理方法应用的必要性。
场景文本识别(Scene Text Recognition)是在真实场景图像中识别文本的任务,属于计算机视觉方向的子研究主题。
场景文本识别领域早期的研究,如1 2等,都直接将文本字符视为无意义符号,使用分类模型识别相应的符号。但当遇到文本字符不易被识别的情况,如被污染、模糊时,仅用视觉信息来进行判别是很难的,但可以同时采用语言学信息来辅助推理文本信息。如下图所示,图中文字HOUSE中的字母S被模糊,仅用视觉信息很容易分类错误,但通过语言学知识我们可以通过上下文信息将其推理出来。因此,后续方法如3 4 5等也开始使用语言学模型来解决这一问题,并取得了显著的成效。


图 1:需用语言学信息辅助文本识别的案例。图源6
由于人类的语言学和视觉体系分开运行,但是在阅读等识别文字的场景下又可以同时工作,因此在哲学思想上,将自然语言处理方法应用于场景文本识别任务是合理的。但如何应用语言学领域的知识来改进场景文本识别任务模型的效果仍然是亟待解决的开放式问题。
本文将通过主要对ABINet 7、SRN 6、conv-ensemble-str 8、ASTER 9、R²AM 10等5个较为前沿的场景文字识别领域应用语言学信息来辅助建模的方法进行综述,来介绍这一领域的最新进展。
; 二、国内外研究进展:各方法实现方式及对比
本文所涉及的参考论文主要出自中国学者,但也有部分作者或部分论文的全部作者是国外学者。但是所有论文都以英文撰写,这是由于因为英文是国际交流用语、现阶段主流人工智能领域会议与杂志及交流平台仍然以英语平台为主两方面原因造成的。我认为我们应该有更多中文强势论文和平台,但是现阶段我们仍然需要阅读英文的论文。
本节以下部分将详细介绍ABINet 7、SRN 6、conv-ensemble-str 8、ASTER 9、R²AM 10这5个较为前沿的场景文本识别领域应用自然语言处理方法的模型,来介绍这一任务的最新进展。
ABINet 7的特点即是autonomous(自治的)、bidirectional(双向的)、iterative(迭代的)。其方法整体架构如图 2所示,由2个自治的模型vision model(视觉模型)和language model(语言学模型)组成,视觉模型直接以图像数据作为输入,语言学模型则以视觉模型的输出概率向量作为输入概率向量。
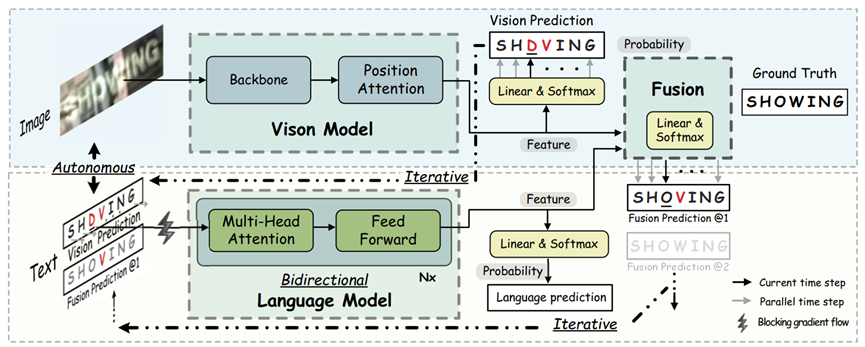
图 2:ABINet方法整体架构图。图源7
自治指两个模型之间没有梯度传递,是分开学习的:这意味着该方法将两个模型分开,其优点一在可以减少误差传播,二在可以分别预训练两个模型,三在可以强制两种模型分别学到视觉和语言学的知识,以防止耦合计算的过程中出现作弊路径。同时,这种做法也更像人类阅读的过程,即对语言的分析是可以独立于视觉的。
ABINet的视觉模型架构如图 3所示,使用ResNet(总共使用5个residual block,在第1和第3个block后使用了down-sampling策略)和Transformer单元来进行特征提取和序列建模,后接基于查询范式的位置注意力模块。
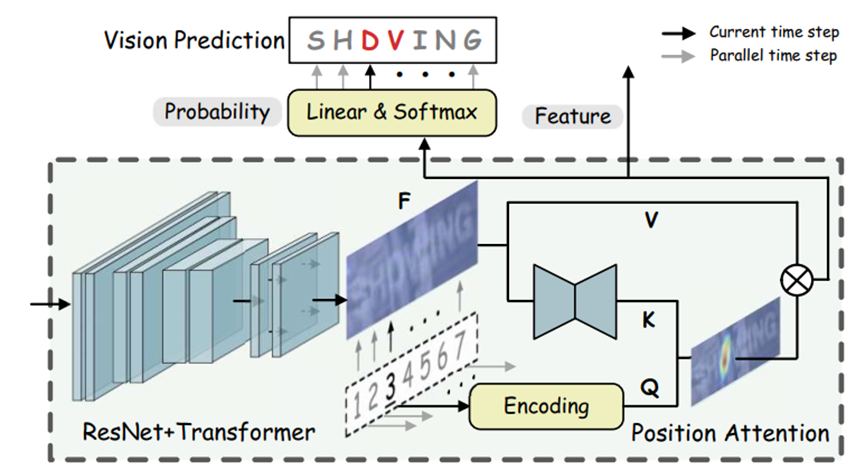
图 3:ABINet的视觉模型架构图,图源7
ABINet的语言学模型架构如图 4所示,以位置编码作为输入,以视觉模型的字符概率向量来应用注意力机制,避免了self-attention机制可能出现的信息泄露问题,并使用对角注意力掩码实现双向性,使得每个字符可以综合双向的信息进行预测。
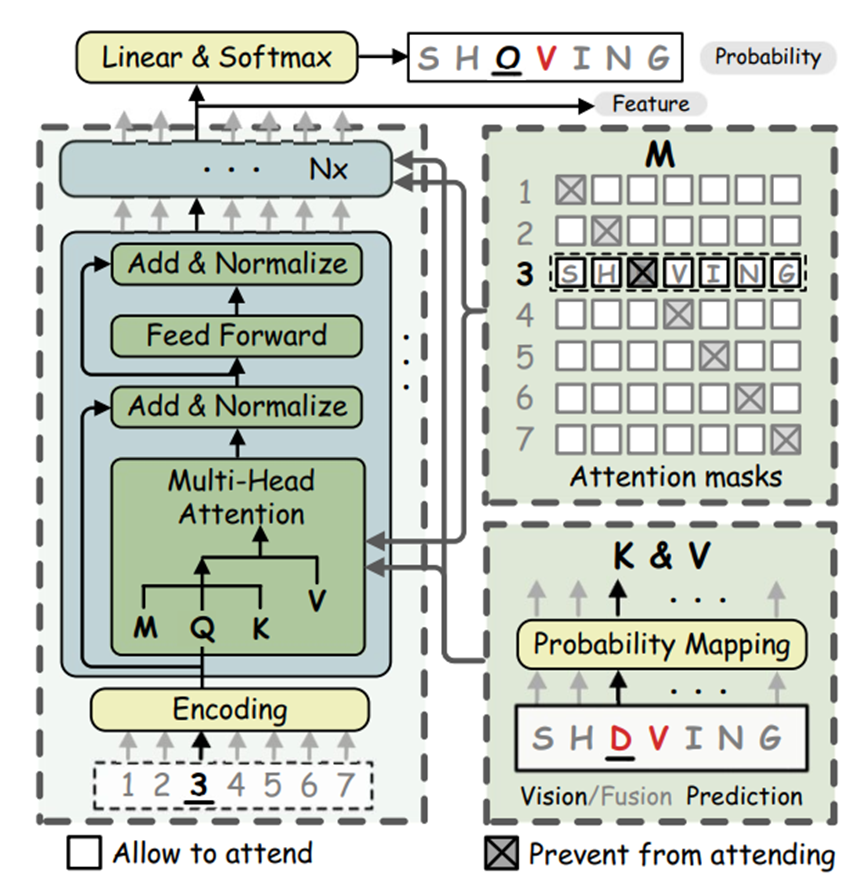
图 4: ABINet的语言学模型架构图,图源7
该方法的迭代性体现在反复多轮执行语言模型,使得识别的效果逐步修正。迭代训练的成功案例如图 5所示,每幅图下的左上、右上、左下、右下分别是真实标签、第1-3轮迭代后的结果,可以看出在经过3轮迭代后,这些案例被成功识别了出来,体现了该方法的有效性。

图 5:ABINet迭代效果示意图,图源7
在ABINet模型的设计哲学层面,其自治性可以反映在人类识别语言和识别视觉的体系虽然可以在阅读时共同工作,但实际上是分别运行的两个系统,模块之间有其独立性,就像盲人也可以使用语言一样。而其双向性可以反应在人看文本时,辨识模糊文字时采用类似完形填空的方法,就是可以同时看其上下文来判断对应缺失位置应该填什么字符。而其迭代性则表现在人看文字时会重复、多次、进化地去识别。
在ABINet方法之前提出的SRN模型6,也是前者重点对比的方法,是基于Transformer的双向并行计算模型。但是仍然是基于自回归的架构,是将两个集成的Transformer模型表示层进行拼接融合,即分别只考虑了单向的信息,算是一种”伪双向”。ABINet方法解决了这一问题:通过只使用一个可以并行运算的模型减少了模型参数规模、提升了计算效率,并使用语言学模型实现了可以同时使用全部上下文信息并保证没有跨时间步信息访问造成的信息泄露问题。
在SRN之前的ASTER 9等方法则采用的是单向的自回归方法,只能串行、单向运行,效率较慢,且此前时间步的错误预测可能出现误差累积问题,SRN使用的并行策略解决了这个问题。而ABINet通过语言学模型的迭代运算更进一步解决了跨时间步的误差累积问题。后文也将对ASTER方法进行简要介绍。
除此以外,ABINet中视觉模型和语言学模型之间的自治性是通过主动的梯度阻塞实现的。而SRN模型中未主动考虑这一点,但其在从视觉信息中提取语言学信息的过程中(GSRM模块中)使用了argmax方法,相当于间接实现了自治性,因为argmax方法是不可导的,从而阻断了反向传播。
语义推理网络semantic reasoning network (SRN),使用了一个全局语义推理模块global semantic reasoning module (GSRM),通过多路并行传输获取全局语义上下文。SRN模型架构如图 6所示,其中GSRM模块架构如图 7所示。输入图像后,首先通过backbone network提取二维特征,在通过PVAM得到对齐的一维特征,这样每个特征就对应一个字符,捕获到了对齐的视觉信息。然后通过GSRM捕获到语义信息,最后将视觉信息与语义信息混合得到输出结果。
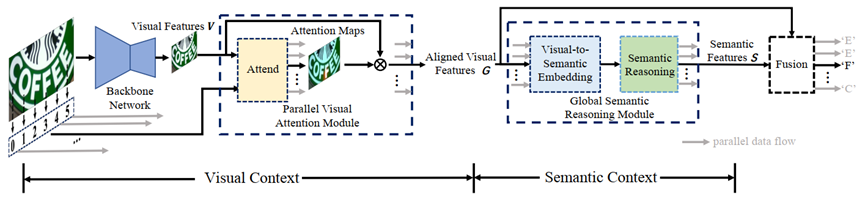
图 6:SRN模型架构,图源6
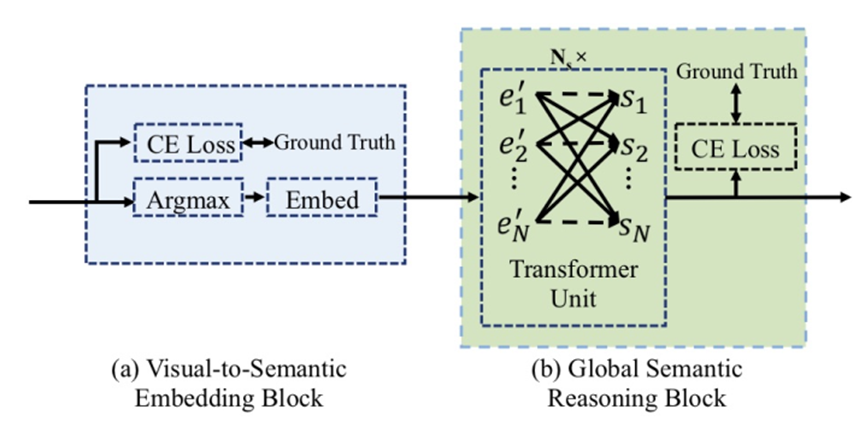
图 7:SRN模型中GSRM模块的架构,图源6
Conv-ensemble-str 8是ABINet团队早期工作,着眼于集成注意力(视觉)和语言学信息。
其训练阶段模型框架如图 8所示:整体基于CNN模型,遵循encoder-decoder架构,输出字符序列。其中encoder是一个二维residual CNN,decoder是一个一维CNN。在decoder中,用注意力模块捕获encoder中得到的视觉信息,用基于门控卷积层的语言学模块捕获语言学信息。使用两个模块输出分别计算交叉熵损失函数,加总作为多任务训练损失函数来进行训练。
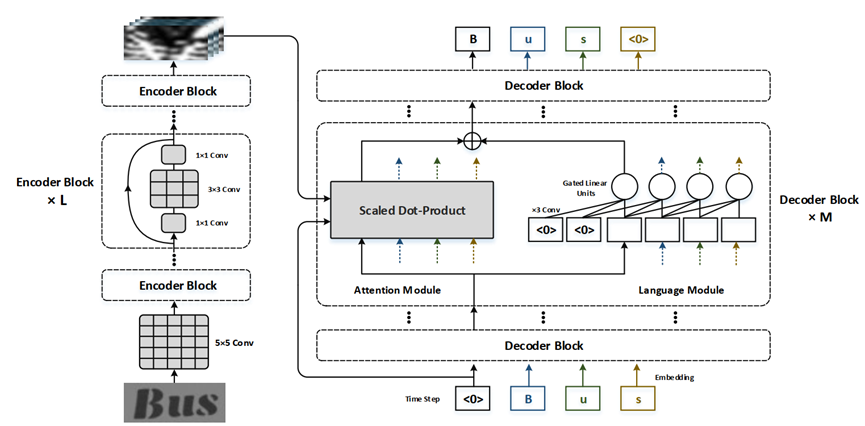
图 8:conv-ensemble-str架构,图源8
ASTER 9也着眼于图片中扭曲、不规则文字的识别,其模型架构如图 9所示:由矫正网络rectification network和识别网络recognition network两部分组成,前者使用flexible thin-plate spline (TPS) 自动将图片矫正为正常的、不扭曲的形式,后者使用含注意力机制的sequence-to-sequence模型直接从矫正后的图片中预测文本。使用多任务损失函数来进行梯度传播。
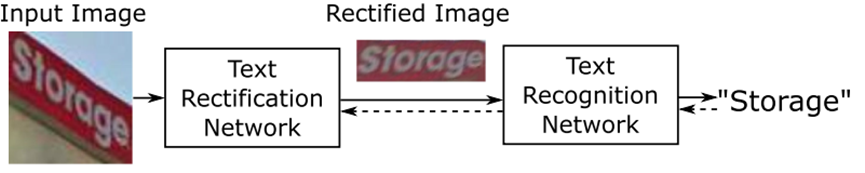
图 9:ASTER模型架构,图源9
相比于在其提出之前的方法,ASTER不需要显示标注字符检测,可以直接通过输入图片和对应标签端到端地训练识别模型。
TPS转换可以矫正各种不规则文本图像,效果如图 10所示:

图 10:TPS转换效果,图源9
整体矫正网络的架构如图 11所示:
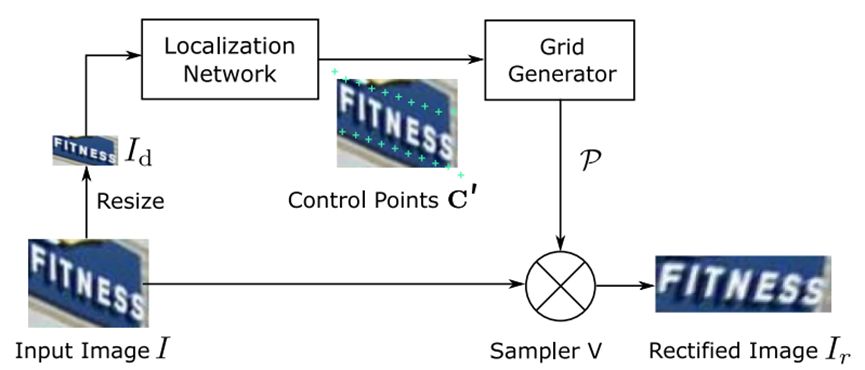
图 11:ASTER矫正网络架构,图源9
整体识别网络的架构如图 12所示:
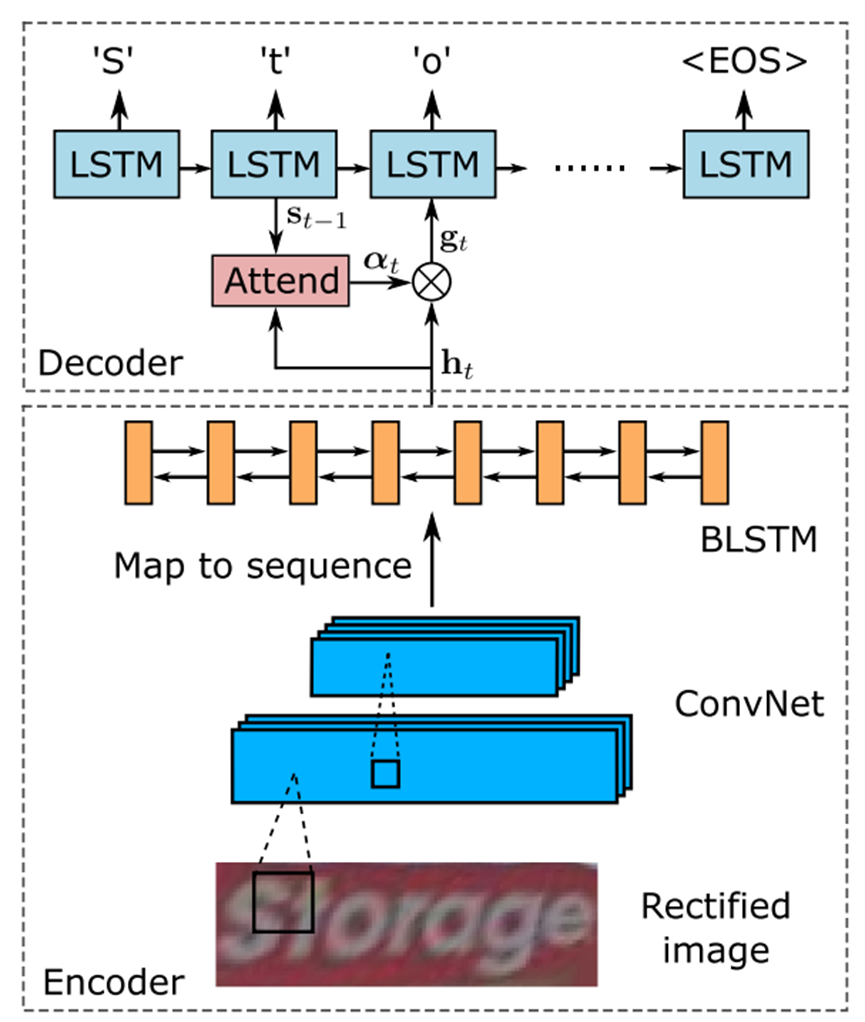
图 12:ASTER矫正网络架构,图源9
此外,该模型中使用的双向decoder就是两个方向相反的单向decoder结果合并,简单取最大值。其结构如图 13所示。
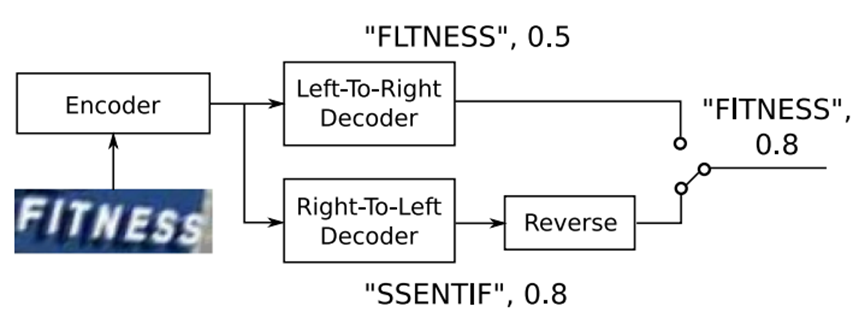
图 13:双向decoder,图源9
R²AM 10是较早的使用注意力机制下的RNN算法来实现场景文本识别的典型方法。在前叙方法中突破了该方法由于RNN的串行机制和复杂实现而无法堆叠多层来建模的问题。
R²AM模型结构如图 14所示,首先通过循环卷积网络(CNNs)提取图像特征,然后通过RNNs解码,隐式学习得到字符级别的语言学统计特征。Soft attention功能相当于特征选择机制。
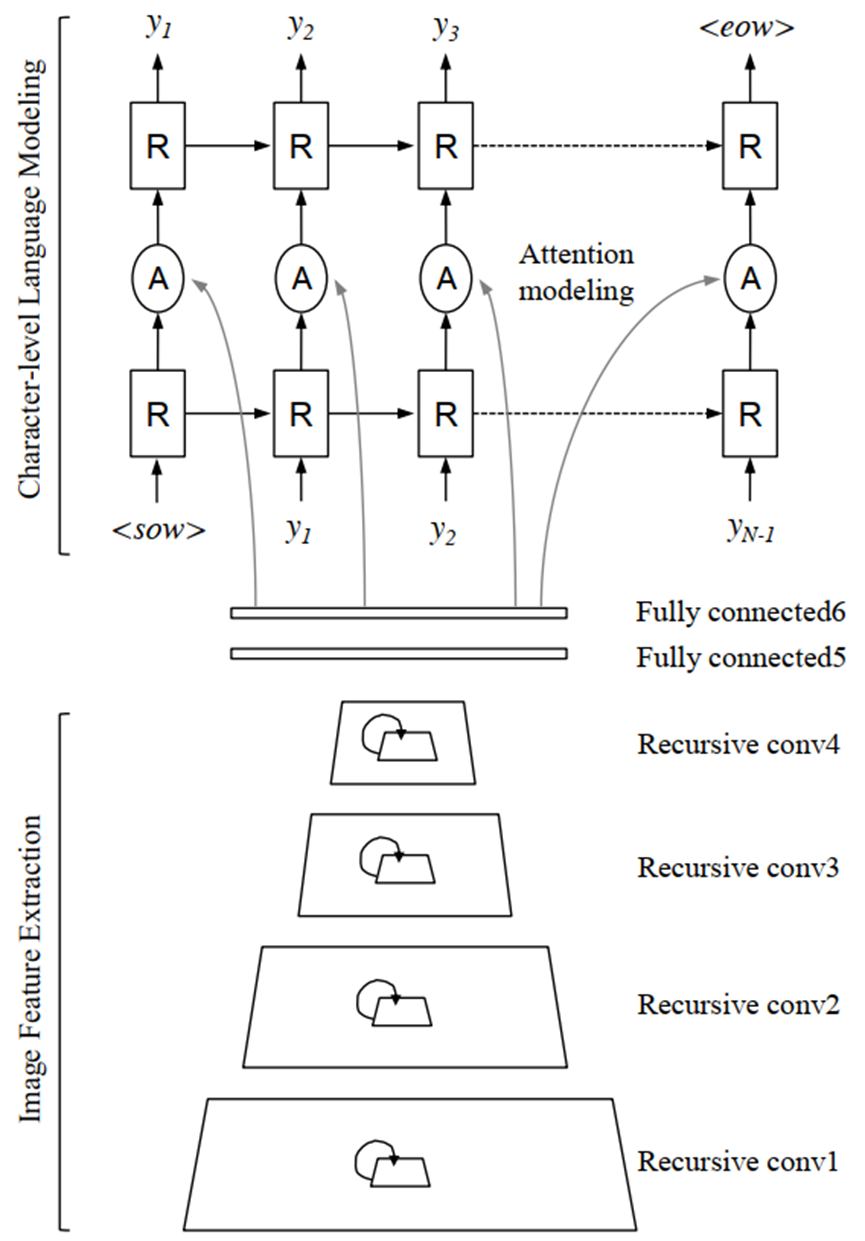
图 14:R²AM模型结构,图源10
本模型仅使用语言方面的损失函数来进行反向传播(相比之下,前叙conv-ensemble-str 8使用了多任务损失函数)。
; 三、当前研究的不足及优化方向
当前研究内容在公开数据集上已经达到了较高的准确率,如图 15所示,即使在不规则文本上,ABINet也达到了超过85%的准确率。但是仍然有提升的空间。在其他现实场景数据集中的效果也有待验证。
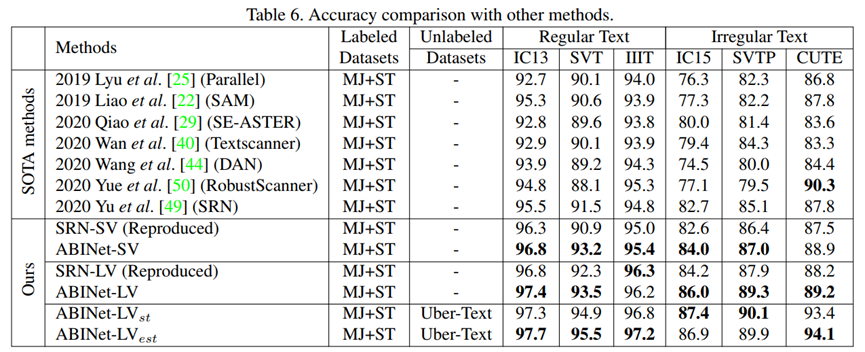
图 15:ABINet准确率结果,图源7
此外,在时间和算力代价上也可以继续提升。
本文所介绍的五个方法都是基于英文(拉丁语系)建立的识别模型,在其他非拉丁语系文字上、尤其是长文本上的实验效果还较少验证。
此外,各模型常用的attention方法可以提供一定的可解释性和文本检测功能,如SRN 6的PVAM模块可以计算出如图 16所示的注意力地图,在一定程度上可以对应到各个字符,但是对文本检测任务仍然欠佳。接下来的研究方向可以是提出文本检测、识别等多任务整体化、端到端的pipeline方法。

图 16:SRN的PVAM模块计算出的注意力地图,图源6
; 其他本文撰写过程中使用到的参考资料
- (CVPR 2021, Oral)聊一聊使用NLP语言模型解决场景文本识别中问题的思路以及一些思考 – 知乎
- 【论文阅读】Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for STR_Weijin_的博客-CSDN博客
- 【OCR文本识别系列】Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Tex_Patrick Star1的博客-CSDN博客:这一篇讲了代码,就我的程度来说已经太深入了!
- ReadLikeHumans: Autonomous,Bidirectional and Iterative Language Modeling for Scene Text Recognition_CharlesWu123的博客-CSDN博客
- 论文笔记之Read Like Humans: ABINet for Scene Text Recognition_To_1_oT的博客-CSDN博客
- ASTER: An Attentional Scene Text Recognizer with Flexible Rectification_alibabazhouyu的博客-CSDN博客
- 文献阅读——(第十三篇)ASTER:An Attentional Scene Text Recognizer with Flexible Rectification_我学数学我骄傲的博客-CSDN博客
- 【论文笔记】Recursive Recurrent Nets with Attention Modeling for OCR in the Wild_糖梦梦是女侠的博客-CSDN博客
其他与本主题相关的学习资料(持续更新)
Original: https://blog.csdn.net/PolarisRisingWar/article/details/125676265
Author: 诸神缄默不语
Title: 场景文本识别应用自然语言处理的方法综述(2021年)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531983/
转载文章受原作者版权保护。转载请注明原作者出处!