


【 关键问题】随着自然语言处理技术的快速发展,研究其中的鲁棒性问题变得日益重要。如果模型是不鲁棒的,在实际使用中就会存在很大的问题。对NLP鲁棒性的研究有利于学术界更加顺利地理解深度学习模型的运行原理,有助于其在工业界的实际应用。
近年来,针对NLP领域的鲁棒性研究不断涌现,研究者从数据集、表示、模型和评估等不同的角度,对NLP算法的鲁棒性问题开展了一些研究。在近日举行的EMNLP 2021论文预讲会中, 复旦大学计算机学院张奇教授 做特邀报告,详细介绍了NLP中的鲁棒性研究进展,智源社区对内容进行了整理。

预讲会回看链接:https://event.baai.ac.cn/activities/177

讲者简介:张奇,复旦大学计算科学技术学院教授、博士生导师。主要研究方向是自然语言处理和信息检索。以第一作者或通讯作者发表论文共100 余篇,被引用次数3000余次。获得WSDM最佳论文提名奖、COLING最佳论文提名奖。作为第二译者翻译专著《现代信息检索》。获得上海市科技进步二等奖、教育部科技进步二等奖、ACM 上海新星提名奖、IBM Faculty Award、中国中文信息学会钱伟长中文信息处理科学技术奖–汉王青年创新一等奖。
演讲者:张 奇
撰 稿:梁 子
审 校:戴一鸣
01
鲁棒性问题的缘起
什么是鲁棒性问题?为什么会有鲁棒性问题?以情感分析[1]为例,对于”Tasty burgers, and crispy fries.”这样一句话,使用BERT等模型可以提取整个句子的表示进行分类,甚至对某一个类别的情感评价也能得到不错的效果,但这种效果是否鲁棒呢?比如说,在模型评价用户对”Burgers”的情感时,究竟是”Tasty”在起作用,还是”Crispy”词在起作用?如果模型通过对Burgers描述之外的词汇判定用户对该词的评价情感,那么在实际使用中就会存在很大的问题。

因此,我们可以通过人工制造特殊样本的方式,来探究当下的模型是否存在这类问题。如上图所示,对于用户的一句评价,如果将一个句子中不同的目标实体给予不同的评价属性(如将Burgers的评价改为Terrible,将Fries的评价改为Soggy),或在原句的基础上添加一些额外的评价,那么模型的准确率将会出现巨大的下滑。
从实验数据可知,即使是BERT这种类型的模型,在这样的环境中准确率也仅有50%左右。由此可以看出对鲁棒性的研究可以更全面地判断模型的能力,对研究和应用都十分关键。
为清晰地讲解鲁棒性的问题,张奇教授从数据集、表示与模型、评估等NLP构建环节中存在的鲁棒性进行了介绍。下面依次介绍上述几个部分中可能存在的问题,之后基于这些问题张教授介绍了近期的一些工作。
02
NLP研究中出现的鲁棒性问题
1.数据集中的问题
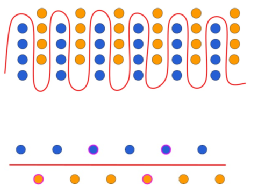
数据是有监督机器学习算法的基础。近年来的研究也表明数据构建的方式将直接影响到算法的鲁棒性。以上图[2]为例,对于一个二分类问题,如果真实数据是该图上方具有复杂边界的分布情况,而在数据采样中因为某些原因构建出该图下方所示的数据集,那么训练得到的分类器(红线)在真实环境应用时,就不可避免地会出错。此外数据集在构造过程中还存在”数据集偏差”(Dataset-Specific Bias)问题,包括单词关联(Word Association)以及基于语言的偏差(Language-based Bias)等。由于深度神经网络模型有较强的学习能力,模型在训练时会依照这种偏差而走”捷径”,从而出现在数据集上表现良好,但无法适用于实际数据分布的问题。
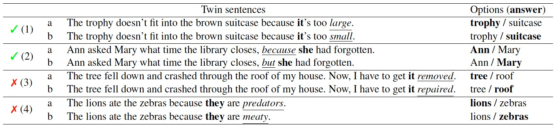
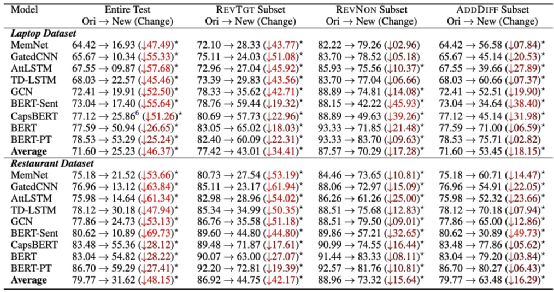
以AAAI 2020 Best Paper[3]中在常识推理(Commonsense Reasoning)任务中的研究(上图)为例,对于(3)(4)两个案例,预训练模型并不需要学会推理就可以表现得非常好。论文对该数据进行可视化,如下图所示。
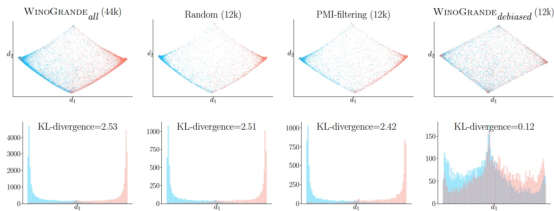
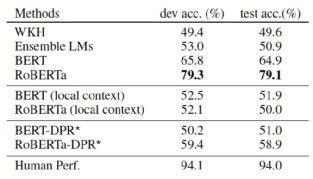
可以看出,原始的数据集(最左侧)在降维之后,其数据本身便具有很强的归纳性,在这样的数据集之下,RoBERTa的准确率可以达到91.3%。但如果将数据集进行Debias(最右侧),那么模型的效果将会大幅下降,RoBERTa的准确率下降到79.1%,如果采用DPR训练语料进行训练,在新构建的语料上进行测试,精度进一步下降到58.9%(下图DPR所示),对于二分类问题,百分之五十多的准确率又近似于随机猜测了。
2.文本表示中的问题
文本表示层面出现的鲁棒性问题,主要是让某一特定的模型学习其对抗样本,该类样本在输入模型之后推理结果较差的情况。按照攻击者对模型的了解程度,可以分为白盒方法、黑盒方法和盲盒方法。按照对输入样本进行改动的粒度,在NLP领域可以包括字符级别、单词级别和句子级别。
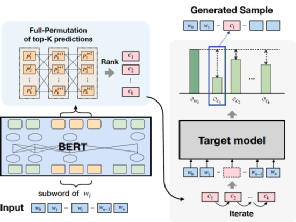
张教授分享了一篇使用BERT攻击BERT的工作[4],是单词级别的黑盒攻击。其核心思路(下图)如下:对于需要进行攻击的Target Model,对输入语句中的某个词进行替换,使得替换前后输出的变化最大。在选择该词的替换词时,使用一个BERT模型获得其Top-K个近似词。
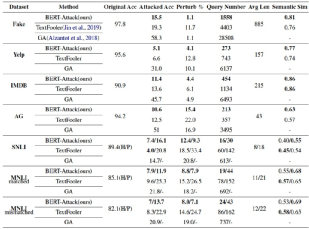
通过这种方法,论文以较小的数据扰动率达到了较高的准确率下降。
3.模型层面的问题
模型层面上的鲁棒性问题包括两部分:如何去解释神经网络的行为,以及如何进行鲁棒的机器学习。
(1)如何解释神经网络的行为
对于神经网络模型的解释工作,近年来较为受到关注的主要有:设计一些显性的分数,以及对Attention进行解释两类。对于设计显性分数,以Integrated Gradients(IG)[5]方法为例。该方法通过对神经网络f的输入x中的某个分量x_i进行敏感度分析,来探究模型对输入中的该分量的重视程度。IG的定义如下:

以NLP为例[6],x_i可以理解成是输入序列X中的某个词(或子词),而Baseline x’则可以看作是全零的Embedding向量。

以视觉问答任务为例,对于上图所示的问答任务,可以发现模型似乎并不关注”Symmetrical”等人类认为很重要的词,反而在一些语法词汇如”how”、”are”上倾注了更多的注意力。这样造成的问题是:如果在模型不关注的在词汇上进行的相反词替换,那么模型就不会因为这些词的替换而改变其预测结果,这样就会造成预测失败。
此外,另一个较为热门的可解释性研究来自于对BERT中Attention机制的理解。Attention机制究竟学到了什么?目前来看[7][8],某些Attention学习到了一些有一定意义的关联,如通过[cls][sep]等Token完成两句话的关联、通过给定的Token自觉地联系到下一个词、代词指代、语法关系等。这说明,同于自监督方法,预训练语言模型学习了一些关联关系以及高层语法信息。利用这些信息可以很好的文本进行表示,也同时具备了很强的拟合数据的能力。
(2)鲁棒机器学习研究
鲁棒的机器学习主要是建立在机器学习三个假设的特例上获得的[9]。例如,对于封闭空间假设,那么就会出现一系列开放的数据分布鲁棒性问题;对于独立同分布假设,就会出现非独立同分布的鲁棒性问题;对于干净和大量数据假设,就会出现噪声数据和小样本数据上的鲁棒性问题。
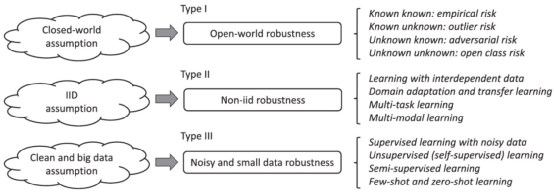
下面分别进行具体介绍。
开放世界的鲁棒性问题
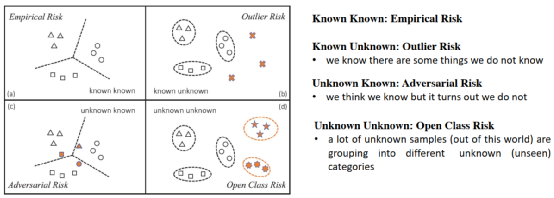
机器学习通常是面对封闭世界,解决其中的Empirical Risk问题,而开放世界的鲁棒性问题主要包含三种情况:
1.Outline Risk:即存在样本数据集空间之外;
2.Adversarial Risk:即样本存在于数据集空间之内,但是其情形是数据未覆盖的。也被称作是未知的已知(Unknown Known);
- Open-Class Risk:即样本存在于数据集囊括的空间之外,同时也是当前所不知道的分类。也被称作是未知的未知(Unknown Unknown)。
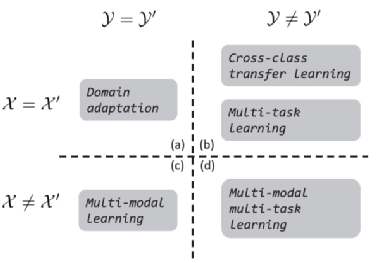
独立同分布假设上的鲁棒性问题
独立同分布假设是指采样所获得的数据集同真实数据分布尽可能一致,数据集中各数据彼此独立,不存在概率上的关联。基于该假设,可导出:在数据集上表现良好的模型,也可以在真实数据上表现良好。下图展示了独立同分布在数据和标签两个维度上展开后所面临的鲁棒性问题。
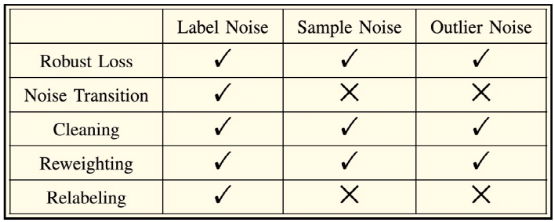
有噪声数据的鲁棒性问题
在机器学习中,噪声数据主要包括三类:标签存在噪声、样本存在噪声以及二者均无效。下图展示了一些典型的解决方案对这三类问题的适用情况。
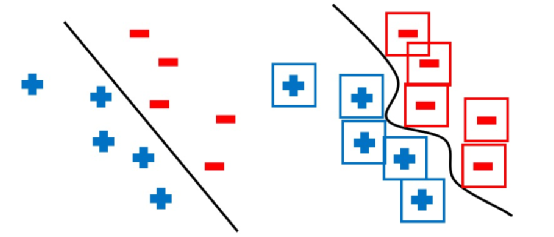
下面着重介绍了两种使用鲁棒的损失函数提升鲁棒性的方法[10]。一种是通过约束训练语料样本周边非常近的点也必须与原始样本分类相同,来对抗微小扰动引起的模型分类错误,从而提升模型鲁棒性的方法,如下图所示:通过这种方法可以学习到更加准确的分类曲线。
该方法对应的损失函数可用下式表达:
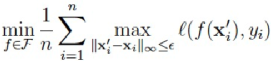
另一种思路是在上式基础上,进一步通过增加对模型参数进行正则化约束,来提升模型的鲁棒性效果。
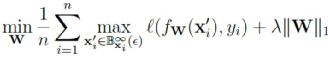
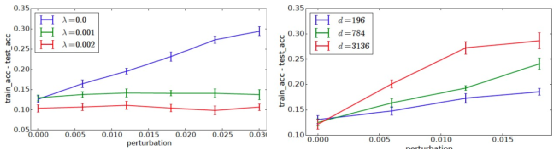
实验表明,神经网络模型通过引入L1正则化可以提升模型的泛化性(衡量指标:模型在训练集与测试集中的准确率差异),而对于特征维度越高的模型,其泛化性能则越差。
4.模型评估中的问题
模型评估旨在回答以下三个问题:是否拥有良好的表现就是一个好模型?这些模型有多强的泛化能力,还是仅仅对数据集学到了某些简单的模式匹配?模型是否真正捕获了数据集所期望测试的能力,还是仅仅学到了一些Bias?针对这些问题,张教授分享了三篇工作。
Rethink cws: Is Chinese Word Segmentation A Solved Task?,EMNLP 2020
这篇是针对中文分词问题而提出的工作[11],该工作通过所选取的七个评价维度,对中文分词进行了细致的评价。
Fu et al., Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study, AAAI 2020
这篇是对命名实体识别问题进行分析[12],以观察深度学习模型的泛化性。论文中提出一种新的指标——实体覆盖率,以分析目前已有的方法在测试集实体与训练集实体差距较大时(即ECR指标较低)目前已有的方法的表现。
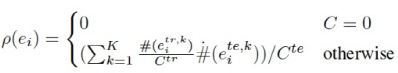
Liu et al., EXPLAINABOARD: An Explainable Leaderboard For NLP, ACL 2021
ACL 2021的Best DEMO EXPLAINABOARD[13]提出引入更加全面的评价体系,在常用的任务指标之外,还添加了更详细的输出结果分析指标,使用多个数据集去分析偏置的出现,给出Case Study或通过统计学的方式去分析更有意义的结果等。
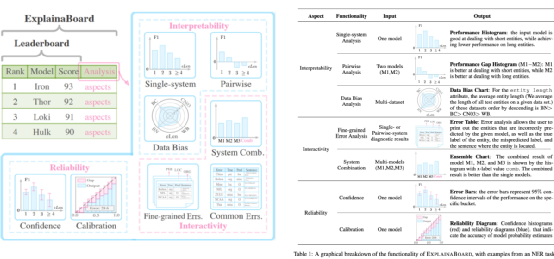
Textflint
Textflint是一种鲁棒性评估工具,可自动为输入数据依照不同模式生成对应的变体,通过评估模型在这些变体上的效果以评估其鲁棒性。该项目的GitHub地址为: Https://Github.Com/Textflint/Textflint
在介绍完鲁棒性在数据集、表示、模型、评估上的问题之后,最后十分关键的问题是:如何去提升模型的鲁棒性?
03
提升模型鲁棒性的方法
下面基于EMNLP2021来看一看该领域的相关工作。
Yan et al., A Partition Filter Network For Joint Entity And Relation Extraction, EMNLP 2021
这一篇是在NER任务上提升鲁棒性的[14],该论文认为,目前主要的NER任务是将实体的信息记忆在了神经网络里,并没有学会基于语境信息对实体的身份进行识别。因此,该论文提出了一种联合学习的框架,通过对实体特征、关系特征以及二者共享部分的特征三部分解耦,以多任务学习的方式更好地增强NER和关系分类两个任务。
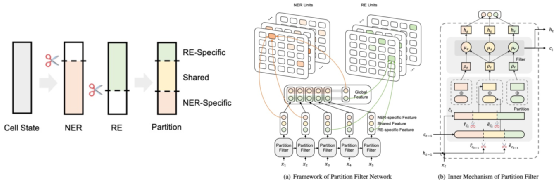
这种方式除了对两个任务都有促进之外,在鲁棒性问题的测试上取得了相对于其他方法好很多的效果。

Li et al., Learning Implicit Sentiment In Aspect-Based Sentiment Analysis With Supervised Contrastive Pre-Training, EMNLP 2021
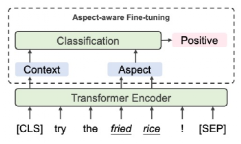
这一篇工作是关于情感分析问题[15],目前情感分析通常将语句与待评估的Aspect通过[SEP]拼接起来,希望通过BERT等模型去学到对该Aspect的情感分析能力。然而,这对于目前的预训练模型而言有些困难。对此,论文引入一些新的方法来增加Aspect同Sentence的关联。主要包括:
1.在模型预训练阶段,对于隐式的情感表达,进行Aspect的对齐。下表是两个例子。

2.在模型微调阶段,在过去使用整个序列的表达进行情感分类的基础上,增加融合Aspect的表示来增强Aspect的影响。
Li et al., Searching for An Effective Defender: Benchmarking Defense Against Adversarial Word Substitution, EMNLP 2021
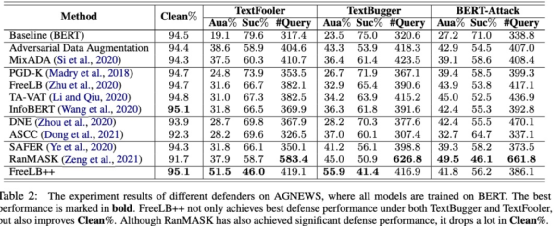
这篇工作[16]旨在对目前对抗攻击的相关工作提供一个整体的Benchmark,并基于该Benchmark对目前的方法进行评估。论文在对抗性输入与原始输入的差距、可提供的候选攻击词的个数、修改部分的比例、为攻击所需的对模型推理次数以及模型大小等各个方面进行了统一,最终完成了对目前已有方法的统一总结。
04
参考文献
[1]Xing et al., Tasty Burgers, Soggy Fries: Probing Aspect Robustness in Aspect-Based Sentiment Analysis, EMNLP 2020
[2]Gardner et al., Evaluating Models’ Local Decision Boundaries Via Contrast Sets, EMNLP 2020
[3]Sakaguchi et al., WINOGRANDE: An Adversarial Winograd Schema Challenge at Scale, AAAI 2020.
[4]Li et al., BERT-ATTACK: Adversarial Attack Against BERT Using BERT, EMNLP 2020.
[5]Sundararajan et al., Axiomatic Attribution for Deep Networks. 2017
[6]Mudrakarta et al., Did the Model Understand the Question? ACL 2018
[7]Sofia Serrano & Noah A. Smith, Is Attention Interpretable?, ACL 2019
[8]Clark et al., What Does BERT Look At? An Analysis Of BERT’s Attention, ACL 2019
[9]Zhang et al., Towards Robust Pattern Recognition: A Review,PROCEEDINGS OF THE IEEE 2020
[10]Towards More Scalable and Robust Machine Learning, Dong Yin, 2019
[11]Fu et al., Rethinkcws: Is Chinese Word Segmentation A Solved Task?,EMNLP 2020
[12]Fu et al., Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study, AAAI 2020
[13]Liu et al., EXPLAINABOARD: An Explainable Leaderboard For NLP, ACL 2021
[14]Yan et al., A Partition Filter Network for Joint Entity and Relation Extraction, EMNLP 2021
[15]Li et al., Learning Implicit Sentiment in Aspect-Based Sentiment Analysis with Supervised Contrastive Pre-Training, EMNLP 2021
[16]Li et al., Searching for An Effective Defender: Benchmarking Defense Against Adversarial Word Substitution, EMNLP 2021
Original: https://blog.csdn.net/BAAIBeijing/article/details/121369256
Author: 智源社区
Title: 复旦张奇:如何解决NLP中的鲁棒性问题?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531762/
转载文章受原作者版权保护。转载请注明原作者出处!