

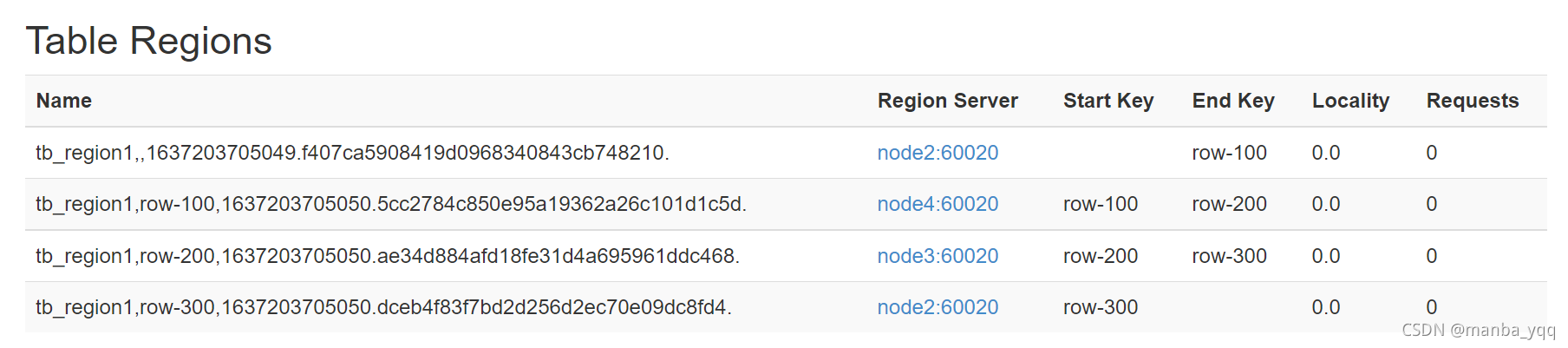
1.Pre-Creating Regions
默认情况下,在创建 HBase 表的时候会自动创建一个 region 分区,当导入数据的时候, 所有的 HBase客户端都向这一个region写数据,直到这个region足够大了才进行切分(也 可以通过命令手动分区:create ‘testtable’,’cf1′,{SPLITS => [‘row-100′,’row-200′,’row-300’]})。一种可以加快批量写入速度的方法是 通过预先创建一些空的 regions,这样当数据写入 HBase 时,会按照 region 分区情况,在 集群内做数据的负载均衡
命令行方式:
hbase(main):017:0> create 'testtable','cf1',{SPLITS => ['row-100','row-200','row-300']}
代码方式:
package yqq.study.app5;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HColumnDescriptor;import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.client.HBaseAdmin;import org.junit.After;import org.junit.Before;import org.junit.Test;import java.io.IOException; public class TablePreRegion { private HBaseAdmin admin; private String tableName = "tb_region1"; public void init() throws Exception { Configuration conf = new Configuration(true); conf.set("hbase.zookeeper.quorum","node2,node3,node4"); admin = new HBaseAdmin(conf); } public void close() throws IOException { if(admin!=null) admin.close(); } public void createTable() throws IOException { if(admin.tableExists(tableName)){ admin.disableTable(tableName); admin.deleteTable(tableName); } HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName)); HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("cf".getBytes()); tableDescriptor.addFamily(hColumnDescriptor); byte[][] splitKeys = new byte[3][]; splitKeys[0] = "row-100".getBytes(); splitKeys[1] = "row-200".getBytes(); splitKeys[2] = "row-300".getBytes(); admin.createTable(tableDescriptor,splitKeys); }}

2.Row Key
HBase 中 row key 用来检索表中的记录,支持以下三种方式:
• 通过单个 row key 访问:即按照某个 row key 键值进行 get 操作;
• 通过 row key 的 range 进行 scan:即通过设置 startRowKey 和 stopRowKey,在这 个范围内进行扫描;
• 全表扫描:即直接扫描整张表中所有行记录。 在 HBase 中, row key 可以 是任 意字 符串 ,最大 长度 64KB,实 际应 用中 一般为 10~100bytes,存为 byte[]字节数组,一般设计成定长的。 row key 是按照字典序存储,因此,设计 row key 时,要充分利用这个排序特点,将经常 一起读取的数据存储到一块,将最近可能会被访问的数据放在一块。
举个例子:如果最近写入 HBase 表中的数据是最可能被访问的,可以考虑将时间戳作为 rowkey 的一部分,由于是字典序排序,所以可以使用 Long.MAX_VALUE – timestamp 作为 row key,这样能保证新写入的数据在读取时可以被快速命中
Rowkey 规则:
1、 越小越好
2、 Rowkey 的设计是要根据实际业务来
3、 散列性
a) 取反 001 002 100 200
b) Hash
3.Column Family
不要在一张表里定义太多的 column family。目前 Hbase 并不能很好的处理超过 2~3 个 column family 的表。因为某个 column family 在 flush 的时候,它邻近的 column family 也会因关联效应被触发 flush,最终导致系统产生更多的 I/O。感兴趣的同学可以对自己的 HBase 集群进行实际测试,从得到的测试结果数据验证一下。
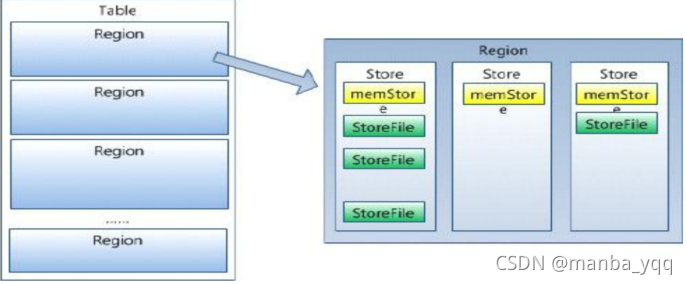
一个 region 由多个 store 组成,一个 store 对应一个 CF(列族)
4.In Memory
创 建 表 的 时 候 , 可 以 通 过 HColumnDescriptor.setInMemory(true) 将 表 放 到RegionServer 的缓存中,保证在读取的时候被 cache 命中。用在读取比较频繁的列族上。
5.Max Version
创建表的时候,可以通过 HColumnDescriptor.setMaxVersions(int maxVersions)设 置 表 中 数 据 的 最 大 版 本 , 如 果 只 需 要 保 存 最 新 版 本 的 数 据 , 那 么 可 以 设 置 setMaxVersions(1)。
6.Time To Live
创建表的时候,可以通过 HColumnDescriptor.setTimeToLive(int timeToLive)设置表 中数据的存储生命期,过期数据将自动被删除,例如如果只需要存储最近两天的数据,那么 可以设置 setTimeToLive(2 * 24 * 60 * 60),单位秒。

7.Compact & Split
在 HBase 中,数据在更新时首先写入 WAL 日志(HLog)和内存(MemStore)中, MemStore 中的数据是排序的,当 MemStore 累计到一定阈值时,就会创建一个新的 MemStore,并且将老的 MemStore 添加到 flush 队列,由单独的线程 flush 到磁盘上,成 为一个 StoreFile。于此同时, 系统会在 zookeeper 中记录一个 redo point,表示这个时 刻之前的变更已经持久化了(minor compact)。
StoreFile 是只读的,一旦创建后就不可以再修改。因此 Hbase 的更新其实是不断追加 的操作。当一个 Store 中的 StoreFile 数量达到一定的阈值后,就会进行一次合并(major compact),将对同一个 key 的修改合并到一起,形成一个大的 StoreFile,当 StoreFile 的 大小达到一定阈值后,又会对 StoreFile 进行分割(split),”等分”为两个 StoreFile。
由于对表的更新是不断追加的,处理读请求时,需要访问 Store 中全部的 StoreFile 和 MemStore,将它们按照 row key 进行合并,由于 StoreFile 和 MemStore 都是经过排序的,并且 StoreFile 带有内存中索引,通常合并过程还是比较快的。
实际应用中,可以考虑必要时手动进行 major compact,将同一个 row key 的修改进 行合并形成一个大的 StoreFile。同时,可以将 StoreFile 设置大些,减少 split 的发生。 hbase 为了防止小文件(被刷到磁盘的 menstore)过多,以保证保证查询效率,hbase 需要在必要的时候将这些小的 store file 合并成相对较大的 store file,这个过程就称之为 compaction。在 hbase 中,主要存在两种类型的 compaction:minor compaction 和 major compaction。 minor compaction:的是较小、很少文件的合并。 major compaction 的 功 能 是 将 所 有 的 store file 合 并 成 一 个 , 触 发 major compaction 的可能条件有:major_compact 命令、majorCompact() API、region server 自 动 运 行 ( 相 关 参 数 : hbase.hregion.majoucompaction 默 认 为 24 小 时 、 hbase.hregion.majorcompaction.jetter 默认值为 0.2 防止 region server 在同一时间 进行 major compaction)。 hbase.hregion.majorcompaction.jetter 参 数 的 作 用 是 : 对 参 数 hbase.hregion.majoucompaction 规定的值起到浮动的作用,假如两个参数都为默认值 24 和 0.2,那么 major compact 最终使用的数值为:19.2~28.8 这个范围。
1、 关闭自动 major compaction 2、 手动编程 major compaction
[root@node1 ~]desc 'bjsxt:phone_log' major_compact 'bjsxt:phone_log' exit [root@node1 ~]

Timer 类,crontab minor compaction 的运行机制要复杂一些,它由一下几个参数共同决定: hbase.hstore.compaction.min :默认值为 3,表示至少需要三个满足条件的 store file 时, minor compaction 才会启动 hbase.hstore.compaction.max 默认值为 10,表示一次 minor compaction 中最多选取 10 个 store file hbase.hstore.compaction.min.size 表示文件大小小于该值的 store file 一定会加入到 minor compaction 的 store file 中 hbase.hstore.compaction.max.size 表示文件大小大于该值的 store file 一定会被 minor compaction 排除 hbase.hstore.compaction.ratio 将 store file 按照文件年龄排序(older to younger), minor compaction 总是从 older store file 开始选择
Original: https://blog.51cto.com/u_15704423/5434876
Author: wx62be9d88ce294
Title: HBase 性能优化方法总结(一):表的设计
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/516924/
转载文章受原作者版权保护。转载请注明原作者出处!