

序言
Bert 是一种基于微调的多层双向 Transformer 编码,Bert中的Transformer 编码器 和 Transformer 本身的编码器结构相似,但有以下两点的不同:
(1)与Transformer本身的Encoder端相比,BERT的Transformer Encoder端输入的向量表示,多了Segment Embeddings。
(2)模型输入中的 Position Embeddings(位置编码)在bert中学习出来的,在Transformer中是预先设定好的值。
Bert 实现了两个版本的模型,在两个版本中 前馈型神经网络(全连接层)大小都设置为4层。

; Bert结构
Bert模型的输入是
三个embeddings想加而成:
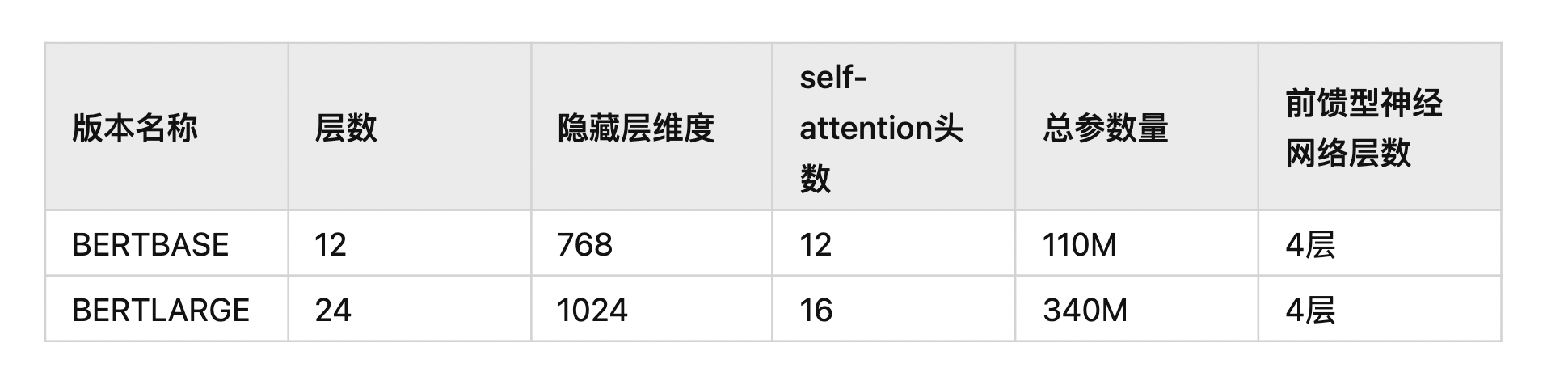
(1)Token Embeddings是每个token在vocab对应的索引,其中第一个单词是CLS标志,可以用于之后的分类任务,对于非分类任务,可以忽略CLS标志;
(2)Segment Embeddings用来区别两种句子,因为预训练不只做语言模型还要做以两个句子为输入的分类任务
(3)Position Embeddings(位置编码) 学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值
BERT模型使用两个新的无监督预测任务进行训练,分别是 Masked LM 和 Next Sentence Prediction。
(1) Masked LM(MLM):随机掩盖部分输入词,然后对那些被掩盖的词进行预测,此方法被称为 Masked LM。
随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。这么做的主要原因是:
- 在后续微调任务中语句中并不会出现 [MASK] 标记,防止被预测的单词泄露给网络,迫使模型更多地依赖于上下文信息去预测词汇 ????
- 并且赋予了模型一定的纠错能力,适应更多样的下游任务,因为有些NLP任务需要用到所有的输入数据,例如词性标注等 ????
(2)Next Sentence Prediction(NSP)
很多句子级别的任务如自动问答(QA)和自然语言推理(NLI)都需要理解两个句子之间的关系。
在这一任务中我们需要随机将数据划分为等大小的两部分(依靠 segment embedding 标记两个句子) ,一部分数据中的两个语句对是上下文连续的,另一部分数据中的两个语句对是上下文不连续的。然后让Transformer模型来识别这些语句对中,哪些语句对是连续的,哪些对子不连续
MLM,NSP分别学习词与词之间和句与句之间的关系
Fine-Tune
【BERT的新语言表示模型,它代表Transformer的双向编码器表示。与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以 通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改】
这里 Fine-Tune 之前对模型的修改非常简单。
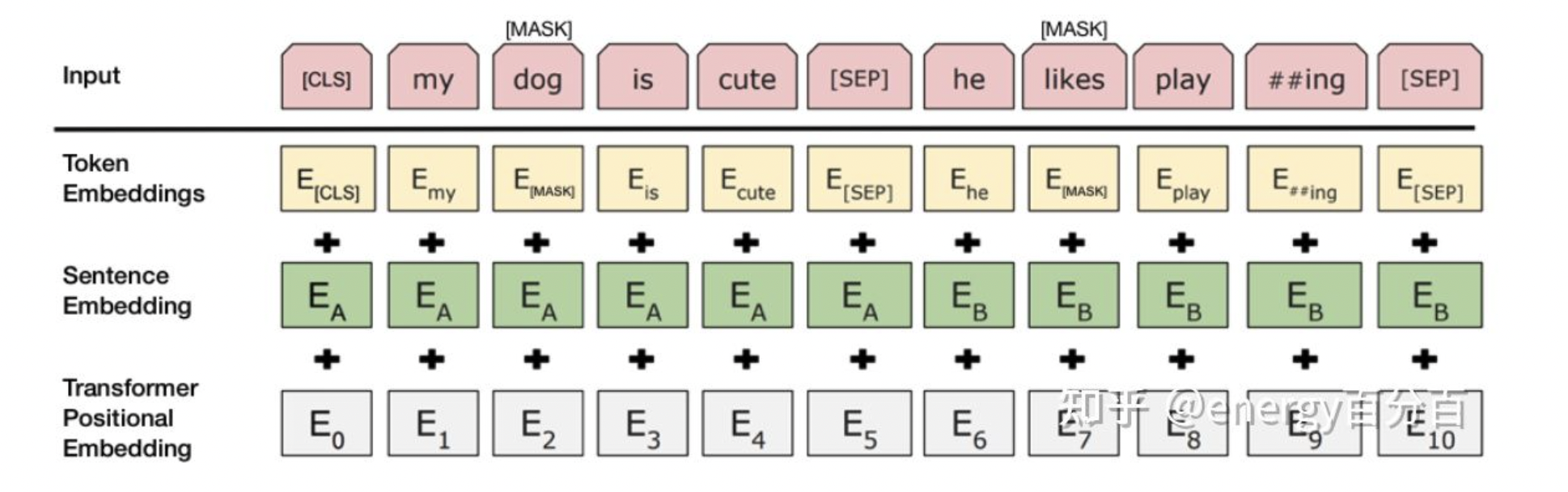
对于sequence-level classification problem(例如情感分析),取第一个token的输出表示,喂给一个softmax层得到分类结果输出;
对于token-level classification(例如NER),取所有token的最后层transformer输出,喂给softmax层做分类。
微调阶段需要对Bet模型进行一定的调整。
(1)句子级别的分类任务
- 对输入的序列添加 [CLS] 和 [SEP] 两个符号,使 Bert 能够接受语句级别的输入; [SEP] 用来分隔序列中的两个句子, [CLS] 对用位置的输出用来进行得到分类结果
- 在 [SEP] 位置对应的输出后增加一个分类层(全连接层+softxax层),用于输出最后的分类概率。
句子对分类任务有:
(1)MNLI
多体自然语言推理(Multi-Genre Natural Language Inference)是一项大规模的分类任务。给定一对句子,目标是预测第二个句子相对于第一个句子是包含,矛盾还是中立的
(2)QQP
Quora Question Pairs是一个二分类任务,目标是判断给定的两个问题的语义信息是否相同(即是否为重复问题)。
(3)QNLI
自然语言推理(Question Natural Language Inference)是推断两个句子之间的关系,比如一个是前提的句子和一个是假设的句子,他们的关系可以是蕴涵、中立和矛盾;
(4)STS-B
语义文本相似性基准(The Semantic Textual Similarity Benchmark)是从新闻头条和其他来源提取的句子对的集合。它们用1到5的分数来标注,表示这两个句子在语义上有多相似。
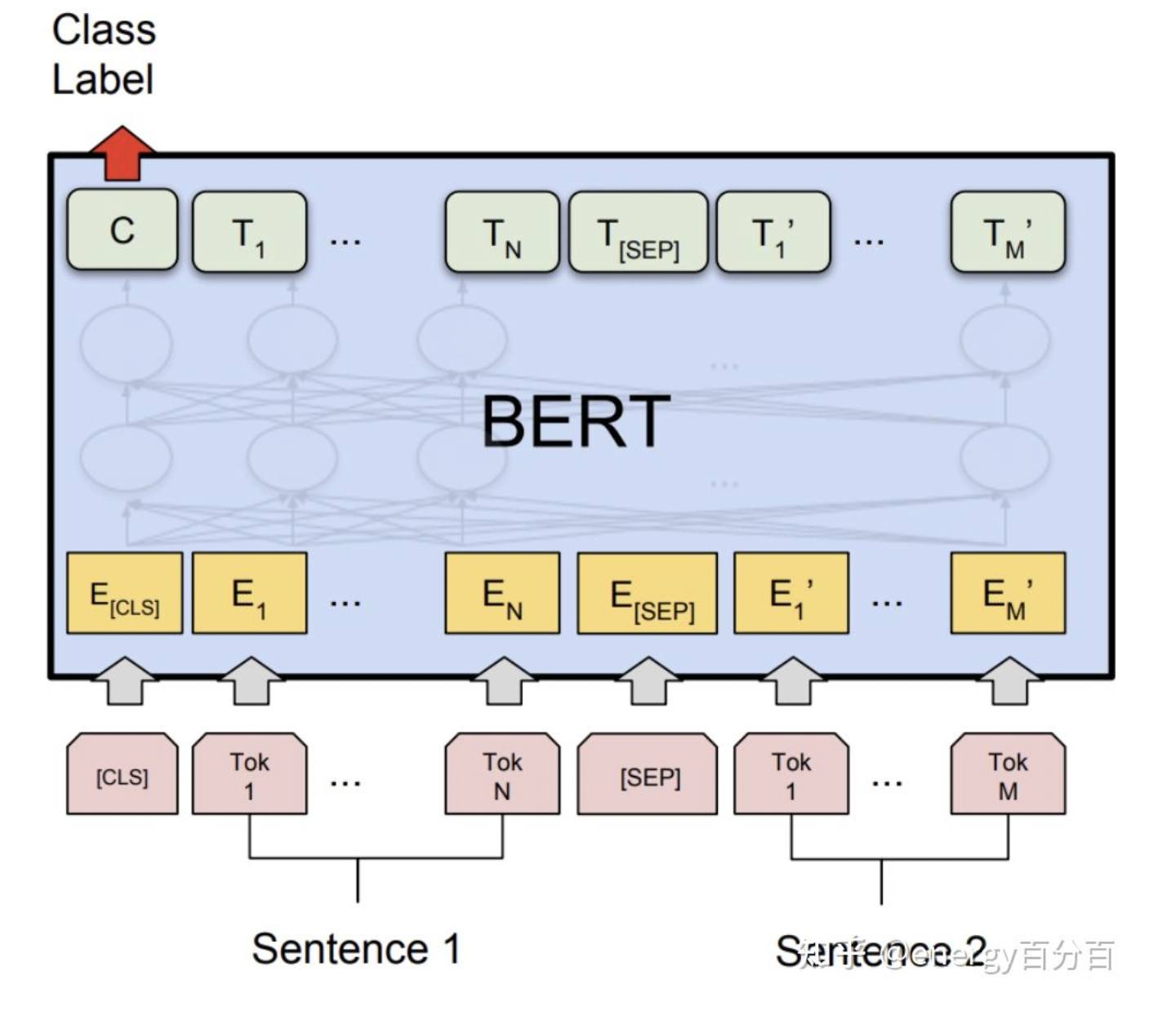
单句子分类任务
单句子分类任务属于序列级任务(对于每个输入序列,只计算 Bert 模型中一个输出的损失),使用 Bert 模型解决单句子分类任务需要对 Bert 模型做如下调整
在 [SEP] 位置对应的输出后增加一个分类层(全连接层+softxax层),用于输出最后的分类概率
修改后的模型如下图所示:
单句子标注任务
单句子标注任务属于token级任务(对于每个输入序列,计算 Bert 模型中所有token输出的损失),使用 Bert 模型解决单句子标注任务需要对 Bert 模型做如下调整:
在 Bert 所有输出后增加一个分类层(全连接层+softxax层),用于输出最后的标注类别的概率
???????
单句子标注任务也叫命名实体识别任务(Named Entity Recognition),简称NER,常见的NER数据集有CoNLL-2003 NER等。该任务是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。举个例子:”明朝建立于1368年,开国皇帝是朱元璋。介绍完毕!”那么我们可以从这句话中提取出的实体为:
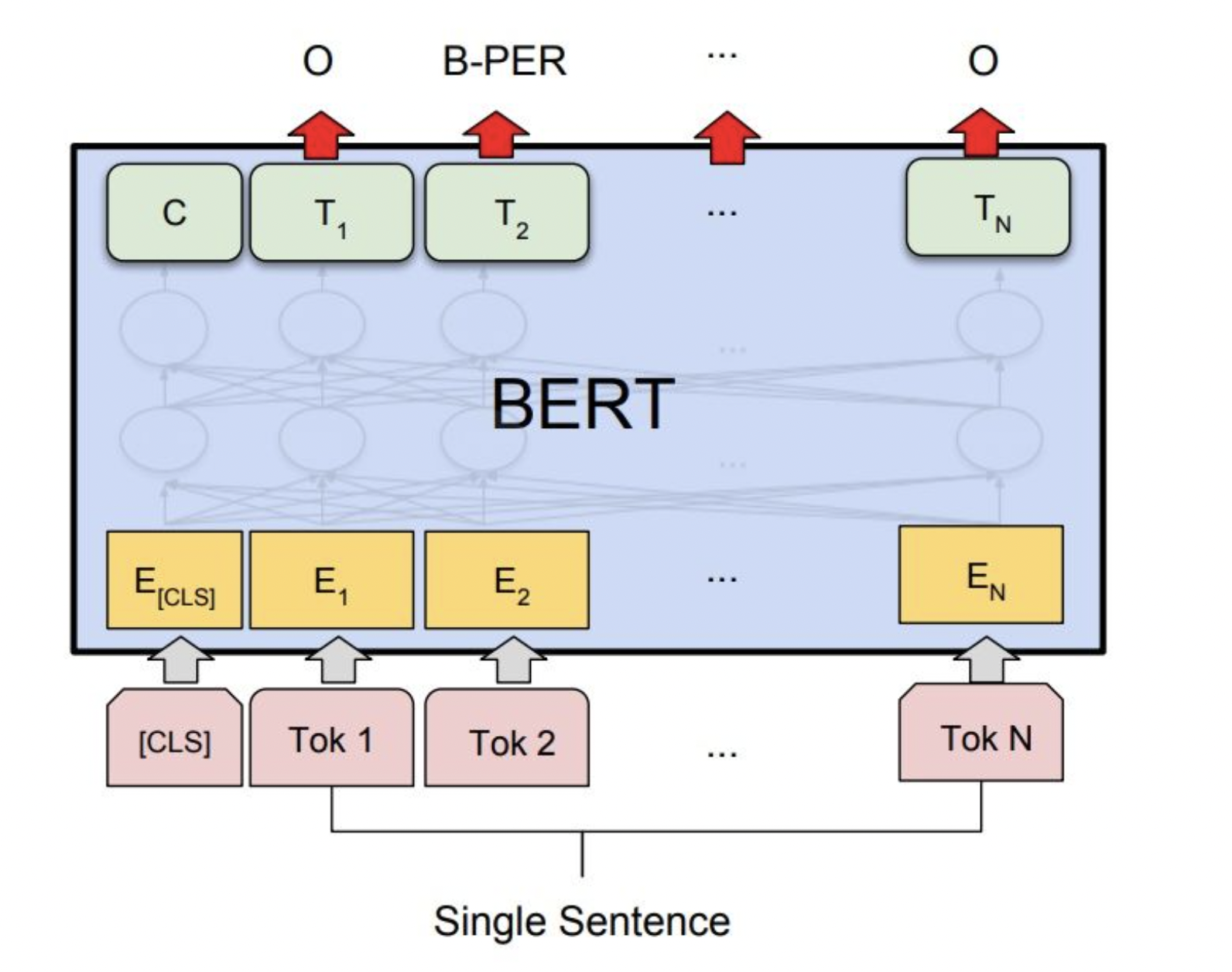
机构:明朝
时间:1368年
人名:朱元璋
BERT在NER任务上也不能通过添加简单的分类层进行微调,因此我们需要添加特定的体系结构来完成NER任务。
Original: https://blog.csdn.net/Jiana_Feng/article/details/120928318
Author: jianafeng
Title: NLP下游任务理解以及模型结构改变(上)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531598/
转载文章受原作者版权保护。转载请注明原作者出处!