

论文目的
对比学习是自监督学习在NLP中的应用,本文使用对抗方法生成对比学习需要的训练样本对,对比学习提升了对抗训练的泛华能力,对抗训练也增强了对比学习的鲁棒性,提出了两种结构:supervised contrastive adversarial learning (SCAL) 和 unsupervised SCAL (USCAL),即有监督的对比对抗训练和无监督的对比对抗训练(USCAL是不是改为UCAL更合适?)。使用监督任务的loss生成对抗训练的实例,无监督任务带来对比损失。在多个数据集上进行测试,效果良好
相关工作
contrastive learning
对比学习被广泛使用于自监督学习,它学习一个encoder表征训练集合里的图片,好的表征能识别相同的物体并区分不同的物体。cv中使用旋转、颜色变化和裁剪等图像变换方式数据增强生成正对,它们在表征空间中彼此接近。对比学习也可以用在有监督学习中充分利用标签数据。SimCLR(对比不同的数据增强方法、大batch、大epoch)、MoCo(动态队列存储更多的负样本、动量缓慢更新保持一致性)、BYOL(只区分minibatch内的)。
这种学习范式在NLP中也有应用,对比学习的关键是生成正对,而在NLP中生成正对是困难的,通常使用回传、删除词语和片段、还有切割句子。SimCSE仅适用dropout提高句子的表达能力,我们的工作也使用dropout增加句子的不同视角,但对抗性实例也作为正对添加到对比损失中,这样不仅增加的模型训练的难度,也使得模型更鲁棒和富有表现力。
Adversarial Training and Adversarial Attack
对抗训练是指用干净的对抗样本训练网络,使得网络可以抵御攻击并提高鲁棒性,在object detection, segmentation and image classification上都有应用。为了完成训练,必须使用干净的样本和网络产生对抗训练样本,使得网络预测错误的类标签。Word-level substitution and sentence-level rephrasing 是典型的文本对抗性攻击。Fast Gradient Sign Method (FGSM) and Fast Gradient Method (FGM) 是本文中使用的对抗训练的方法。
基于对抗和对比训练的在CV和NLP中都有许多工作,本文侧重于对模型encoder向量级别的对抗攻击,并将对抗性实例用于对比损失。在有监督和无监督的两个任务上都提出了框架,并在数据集上获得了好效果。
本文方法
Adversarial Training And Adversarial Attack Methods
数据集D = ( X , Y ) D=(X,Y)D =(X ,Y )
映射f θ : X → Y f_{\theta}:X \to Y f θ:X →Y
满足δ ∗ = arg max δ L c e ( x + δ , y ; θ ) . s . t . ∣ δ ∣ p < ε \delta^=\arg\max_{\delta}L_{ce}(x+\delta,y;\theta).s.t.|\delta|_p
FGSM:
x a d v = x + δ = x + ε ∗ s i g n ( Δ x L c e ( x , y ; θ ) ) . s . t . ∣ δ ∣ p < ε x^{adv}=x+\delta=x+\varepsilonsign(\Delta xL_{ce}(x,y;\theta)).s.t.|\delta|p
FGM:
x a d v = x + δ = x + ε ∗ ( Δ x L c e ( x , y ; θ ) ∣ Δ x L c e ( x , y ; θ ) ∣ 2 ) . s . t . ∣ δ ∣ p < ε x^{adv}=x+\delta=x+\varepsilon*(\frac{\Delta xL{ce}(x,y;\theta)}{|\Delta xL_{ce}(x,y;\theta)|_2}).s.t.|\delta|_p
Self-supervised Contrastive Learning
自监督训练中,样本是无标签的,同一个样本经过两种数据增强方式得到两个样本,一个优秀的模型应该使得正样本更相近,离其它样本更远。
对比学习的loss是infoNCE
L c t = − log exp ( s i m ( x i p , x i q / τ ) ) ∑ k = 1 K s i m ( x i p , x k q / τ ) ) L_{ct}=-\log\frac{\exp(sim(x^p_i,x^q_i/\tau))}{\sum_{k=1}^Ksim(x^p_i,x^q_k/\tau))}L c t =−lo g ∑k =1 K s i m (x i p ,x k q /τ))exp (s i m (x i p ,x i q /τ))
x i p , x i q x^p_i,x^q_i x i p ,x i q 是一对正样本;x k q x^q_k x k q 是负样本;
本文在有监督和无监督的框架中使用不同的转换方法。在有监督的训练中,使用对抗样本作为原始样本的正样本;而无监督的训练中,利用第一个dropout来生成正对,对抗样本也会被用来作为正对。在infoNCE中,主要的问题是两个数据增强的不同,所以我们使用对抗攻击产生不同的正对,在模型中对抗式的训练。
Supervised Contrastive Adversarial Learning
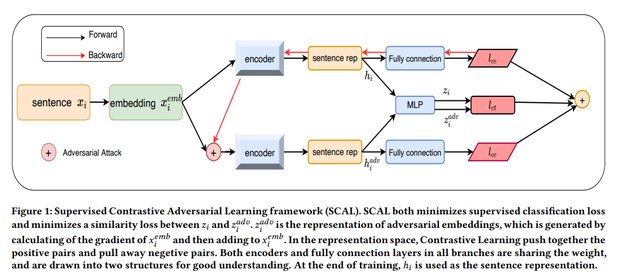

样本x i x_i x i 先经过encoder生成h i h_i h i ,利用有监督的训练计算损失L c e = − 1 N ∑ i = 1 N ∑ c = 0 C y i , c log ( p ( y i , c ∣ h i ) ) L_{ce}=-\frac{1}{N}\sum_{i=1}^N\sum_{c=0}^Cy_{i,c}\log(p(y_{i,c}|h_i))L c e =−N 1 ∑i =1 N ∑c =0 C y i ,c lo g (p (y i ,c ∣h i ))
然后生成对抗性扰动并按照FGM批量添加到每个样本中的词向量中(FGSM是类似的)
x i a d v = x i e m b + δ i = x i e m b + ε ∗ ( Δ x L c e ( x , y ; θ ) ∣ Δ x L c e ( x , y ; θ ) ∣ 2 ) x^{adv}i=x^{emb}_i+\delta_i=x^{emb}_i+\varepsilon*(\frac{\Delta xL{ce}(x,y;\theta)}{|\Delta xL_{ce}(x,y;\theta)|2})x i a d v =x i e m b +δi =x i e m b +ε∗(∣Δx L c e (x ,y ;θ)∣2 Δx L c e (x ,y ;θ))
生成的新x i a d v x^{adv}_i x i a d v 重新经过encoder生成h i a d v h^{adv}_i h i a d v ,两个h i a d v h^{adv}_i h i a d v 和h i h_i h i 经过pooling层生成z i a d v z^{adv}_i z i a d v 和z i z_i z i 计算对比损失
L c t = − log exp ( s i m ( z i , z i a d v / τ ) ) ∑ k = 1 K s i m ( z i , z k / τ ) ) L{ct}=-\log\frac{\exp(sim(z_i,z^{adv}i/\tau))}{\sum{k=1}^Ksim(z_i,z_k/\tau))}L c t =−lo g ∑k =1 K s i m (z i ,z k /τ))exp (s i m (z i ,z i a d v /τ))
SCAL的总损失是
L t o t a l = 1 2 ( L c e ( x , y ) + L c e ( x a d v , y ) ) + α L c t ( x , x a d v ) L_{total}=\frac{1}{2}(L_{ce}(x,y)+L_{ce}(x^{adv},y))+\alpha L_{ct}(x,x^{adv})L t o t a l =2 1 (L c e (x ,y )+L c e (x a d v ,y ))+αL c t (x ,x a d v )
; Unsupervised Contrastive Adversarial Learning

首先使用simCSE中的dropout生成第一步的正负样本(x e m b 1 x e m b 2 x^{emb1}\ x^{emb2}x e m b 1 x e m b 2)
利用第一步的对比损失生成对抗扰动并按照FGM批量添加到每个样本中的词向量中(FGSM是类似的)
x i a d v = x i e m b 1 + δ i = x i e m b 1 + ε ∗ ( Δ x L c l ( x e m b 1 , x e m b 2 ; θ ) ∣ Δ x L c l ( x e m b 1 , x e m b 2 ; θ ) ∣ 2 ) x^{adv}i=x^{emb1}_i+\delta_i=x^{emb1}_i+\varepsilon*(\frac{\Delta xL{cl}(x^{emb1},x^{emb2};\theta)}{|\Delta xL_{cl}(x^{emb1},x^{emb2};\theta)|2})x i a d v =x i e m b 1 +δi =x i e m b 1 +ε∗(∣Δx L c l (x e m b 1 ,x e m b 2 ;θ)∣2 Δx L c l (x e m b 1 ,x e m b 2 ;θ))
USCAL的总损失是
L t o t a l = L c t ( x e m b 1 , x e m b 2 ) + α L c t ( x e m b 1 , x a d v ) L{total}=L_{ct}(x^{emb1},x^{emb2})+\alpha L_{ct}(x^{emb1},x^{adv})L t o t a l =L c t (x e m b 1 ,x e m b 2 )+αL c t (x e m b 1 ,x a d v )
EXPERIMENTS
SCAL和USCAL在大型预训练语言模型下对不同任务测试性能
Training Details
BERT和Roberta中[CLS]上面加pooling层和分类层
datasets
有监督:GLUE、AG’s News and TREC
无监督:SentEval
稳健性:ANLI
models
bert(base和large)、roberta(base和large)
对比模型:SIMCSE、FreeLB、SMART、ALUM、InfoBERT、
Experiment Result on SCAL
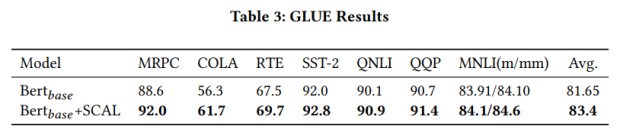
消融试验
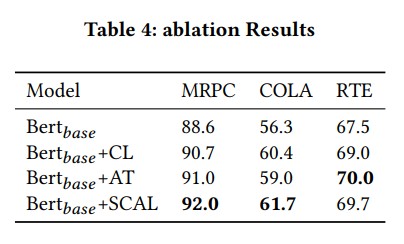
; Experiment Result on USCAL

阅读感官
第一次接触对比+对抗做自监督,第一眼看到结果觉得好惊讶,看完消融试验觉得又是符合预期的,后面要多补充一下对抗做NLP的知识
Original: https://blog.csdn.net/zpp13hao1/article/details/122123047
Author: 红酒暖心也暖胃
Title: Simple Contrastive Representation Adversarial Learning for NLP Tasks
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/531237/
转载文章受原作者版权保护。转载请注明原作者出处!